
目录
深夜的告警短信、缓慢滚动的日志、监控面板上刺眼的红色曲线——这些场景背后,往往是未被察觉的效率黑洞。 我们总在架构层面讨论分布式、缓存、分库分表,却忽略了日常编码中那些微小却高频的损耗点。 本文从实战出发,揭秘5个可立即落地的优化技巧,让你从第一行代码开始构建高性能应用。
让优化思维成为肌肉记忆
今日分享几个优化点,很具有代表性,从技术维度上来看,并行化和异步属于并发模型,锁粒度是线程安全核心,集合分配涉及内存管理,启动预处理则是生命周期优化。它们共同构成了高性能系统的骨架。
并行化:释放多核处理器的洪荒之力
代码实现与优化
日常开发中,我们的代码是否都如以下的实现
java// 顺序处理耗时任务
for (Item item : itemList) {
process(item); // 单线程阻塞执行
}
并行优化的实现
java// 利用并行流拆分任务(适用于无状态操作)
itemList.parallelStream().forEach(this::process);
// 或使用CompletableFuture实现精细控制
List<CompletableFuture<Void>> futures = itemList.stream()
.map(item -> CompletableFuture.runAsync(() -> process(item), executor))
.collect(Collectors.toList());
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
关键原则
任务独立性:并行任务间避免共享状态
线程池隔离:CPU密集型 vs IO密集型任务使用不同线程池
代价平衡:避免细粒度任务带来的线程调度开销
异步处理:别让用户为后台操作买单
代码实现与优化
日常开发中的同步阻塞的实现
javapublic Response handleRequest(Request req) {
saveLog(req); // 同步写日志阻塞主线程
sendMQ(req); // 同步消息发送
return doBusinessLogic(req);
}
通过异步解耦方案进行优化
java@Async("ioThreadPool") // Spring异步注解
public void asyncSaveLog(Request req) { ... }
public Response handleRequest(Request req) {
asyncSaveLog(req); // 异步日志
mqTemplate.asyncSend(req); // 消息队列异步发送
return doBusinessLogic(req); // 主线程快速返回
}
实现方案
异步解耦的方案各种各样,例如
-
Spring @Async + 自定义线程池
-
MQ解耦(RabbitMQ/Kafka)
-
Reactor响应式编程
我们选择适合当前业务场景的即可
锁粒度控制:并发场景的精细手术刀
代码实现与优化
1、使用 synchronized 互斥锁
java@RequestMapping("/doSave")
public synchronized void doSave(String path,String filterUrl){
// 创建文件夹
mkdir();
// 上传文件
uploadFile(filterUrl);
// 发送消息
sendMessage(filterUrl);
}
减少锁粒度
java@RequestMapping("/doSave")
public void doSave(String path,String filterUrl){
// 创建文件夹
synchronized (this){
if(!existPath(path)){
mkdir();
}
}
// 上传文件
uploadFile(filterUrl);
// 发送消息
sendMessage(filterUrl);
}
2、由于我们一般都是多台机器所以我们需要分布式锁
java@RequestMapping("/doSave")
public void doSave(String path,String filterUrl) {
String lockKey = "mkdir-lock";
RLock lock = redissonClient.getLock(lockKey);
if(lock.tryLock()) {
try {
//创建文件夹
mkdir();
// 上传文件
uploadFile(filterUrl);
// 发送消息
sendMessage(filterUrl);
} finally {
lock.unlock();
}
}
}
减少锁粒度
java@RequestMapping("/doSave")
public void doSave(String path,String filterUrl) {
String lockKey = "mkdir-lock";
RLock lock = redissonClient.getLock(lockKey);
if(lock.tryLock()) {
try {
//创建文件夹
mkdir();
} finally {
lock.unlock();
}
}else{
return;
}
// 上传文件
uploadFile(filterUrl);
// 发送消息
sendMessage(filterUrl);
}
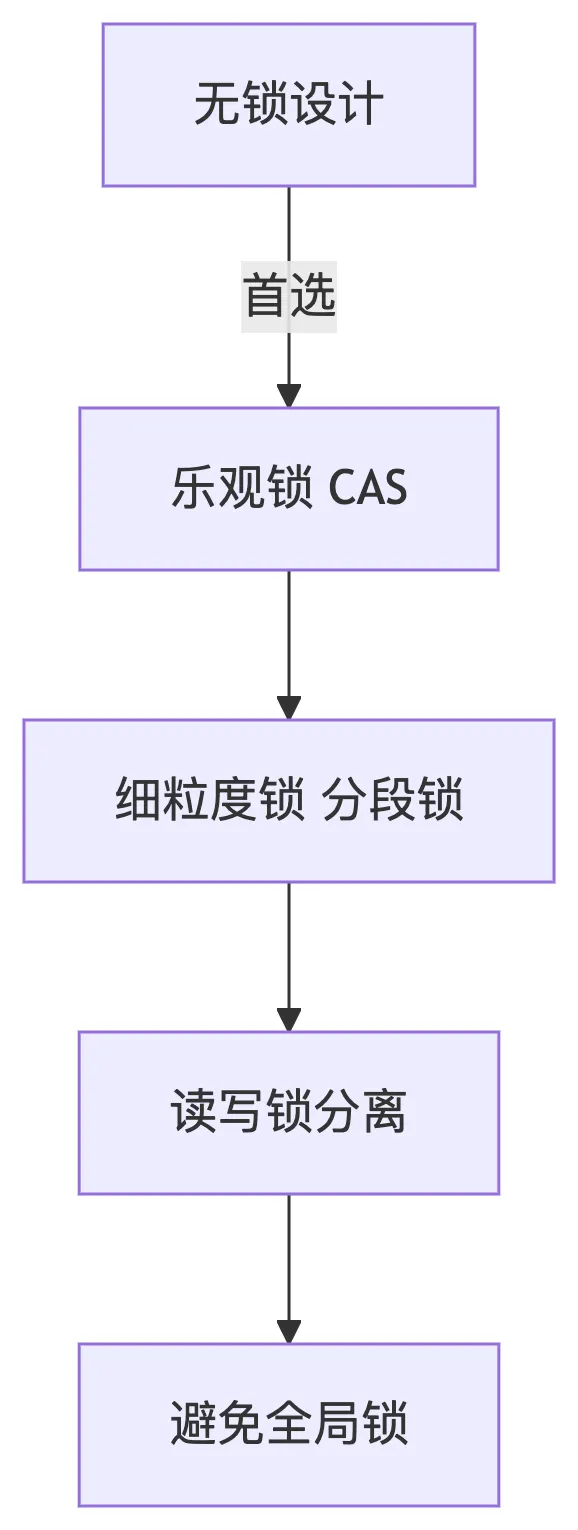
3、粗粒度锁的性能瓶颈
javapublic class CachePool {
private final Map<String, Object> cache = new HashMap<>();
private final ReentrantLock lock = new ReentrantLock(); // 全局锁
public void update(String key, Object value) {
lock.lock(); // 更新任何key都阻塞所有读写
try { cache.put(key, value); }
finally { lock.unlock(); }
}
}
细粒度锁优化
javapublic class CachePool {
private final Map<String, Object> cache = new ConcurrentHashMap<>();
// 使用分段锁(JDK8+推荐直接用ConcurrentHashMap)
private final Striped<Lock> keyLocks = Striped.lock(32); // Guava分段锁
public void update(String key, Object value) {
Lock keyLock = keyLocks.get(key);
keyLock.lock(); // 只锁定当前key的槽位
try { cache.put(key, value); }
finally { keyLock.unlock(); }
}
}
集合空间分配:向动态扩容说“不”
代码实现与优化
如何创建一个集合,这还不简单,很快我们就写出下面代码
List<String> lists = Lists.newArrayList();
如果说,要往里面插入 1000000 个元素,有没有更好的方式?
javapublic class ArrayListTest {
public static void main(String[] args) {
List<String> userNames = new ArrayList<>();
Long beginTime = System.currentTimeMillis();
for(int i = 0;i < 1000000;i++){
userNames.add("天涯" + i);
}
long endTime = System.currentTimeMillis();
System.out.println("1000000 次插入List花费的时间:" + (endTime - beginTime));
List<String> userNames2 = new ArrayList<>(1000000);
Long beginTime2 = System.currentTimeMillis();
for(int i = 0;i < 1000000;i++){
userNames2.add("天涯" + i);
}
long endTime2 = System.currentTimeMillis();
System.out.println("1000000 次插入List花费的时间:" + (endTime2 - beginTime2));
}
}
ArrayList 初始大小是 10,超过阈值会按 1.5 倍大小扩容,涉及老集合到新集合的数据拷贝,浪费性能。了解其底层,可以知道 频繁扩容 才是罪魁祸首,通过一下测试数据可以看出性能差距

预分配空间优化
如果我们预先知道集合要存储多少元素,初始化集合时尽量指定大小,尤其是容量较大的集合。
java// ArrayList预分配
List<User> userList = new ArrayList<>(100_000);
// HashMap避免哈希冲突
Map<String, User> userMap = new HashMap<>(100_000, 0.75f);
// Guava集合工厂
Set<String> typeSet = Sets.newHashSetWithExpectedSize(50);
项目启动预处理:赢在起跑线上
有很多业务的计算逻辑比较复杂,比如页面要展示一个网站的 PV,教育网站中用户学习时间等等,
如果在用户访问接口的瞬间触发计算逻辑,而这些逻辑计算的耗时通常比较长,很难满足用户的实时性要求。
一般我们都是提前计算,然后将算好的数据预热到缓存中,接口访问时,只需要读缓存即可
如果业务实时性没有那么高,可以通过定时,晚上进行处理计算处理。
还有一种是项目启动时初始化的动作,例如加载字典到缓存中,可以通过实现 CommandLineRunner 或 ApplicationRunner 接口
预热方案实践
java@Component
public class PreloadRunner implements CommandLineRunner {
@Autowired
private CacheService cacheService;
@Autowired
private DbConnectionPool pool;
@Override
public void run(String... args) {
// 1. 提前初始化连接池
pool.warmUp(10);
// 2. 热点数据缓存预热
cacheService.preloadHotData();
// 3. 类加载触发(如日志配置)
LoggerFactory.getLogger(this.getClass());
}
}


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!