
目录
在现代分布式系统中,我们常常需要将数据同时写入多个存储系统(如数据库+缓存),这种操作被称为"双写"。双写场景下最大的挑战是如何保证不同存储系统间的数据一致性。本文将深入探讨双写一致性问题,并通过Java实战演示解决方案。
双写一致性挑战
常见问题场景:
-
写入顺序不一致:先写缓存成功但数据库失败
-
并发冲突:多个线程同时更新同一数据
-
部分失败:一个存储成功另一个失败
-
网络延迟:不同存储系统的响应时间差异
主流方案
基于消息队列的最终一致性方案
基于消息队列的最终一致性方案的实现思路为: 应用服务 → 更新数据库 ↓ 同时发送消息 → 消息队列 → 缓存服务 → Redis
核心代码
数据库操作与消息发送(原子操作)
java@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
private final MessageSender messageSender;
@Transactional
public void updateUser(User user) {
// 1. 更新数据库
userRepository.save(user);
// 2. 发送缓存更新消息
messageSender.sendCacheUpdate(new CacheUpdateEvent(
"user:" + user.getId(),
user
));
}
}
消息发送器(保证可靠性)
java@Component
@RequiredArgsConstructor
public class MessageSender {
private final RabbitTemplate rabbitTemplate;
private final TransactionTemplate transactionTemplate;
public void sendCacheUpdate(CacheUpdateEvent event) {
transactionTemplate.execute(status -> {
// 将消息存入本地事务表(略)
saveToLocalTxTable(event);
// 发送到MQ
rabbitTemplate.convertAndSend(
"cache.update.exchange",
"cache.update.key",
event
);
return null;
});
}
}
缓存消费者(幂等处理)
java@Component
@RequiredArgsConstructor
public class CacheConsumer {
private final RedisTemplate<String, Object> redisTemplate;
private final CacheUpdateRecordRepository recordRepository;
@RabbitListener(queues = "cache.update.queue")
public void handleMessage(CacheUpdateEvent event) {
// 幂等检查:防止重复消费
if (recordRepository.existsByMessageId(event.getMessageId())) {
return;
}
try {
// 更新缓存
redisTemplate.opsForValue().set(
event.getKey(),
event.getData(),
Duration.ofMinutes(30)
);
// 记录消费日志
recordRepository.save(new CacheUpdateRecord(event.getMessageId()));
} catch (Exception e) {
// 告警并加入重试队列
sendToRetryQueue(event);
}
}
}
在实体中添加版本号字段,每次更新完版本号叠加,发送消息的同时存储事务消息记录(缓存更新的快照记录),到缓存消费者中进行幂等校验处理,校验后将缓存进行更新,如果更新失败,可抛出异常进行重试,也可进入自定义重试队列中,当重试达到一定次数后,进入死信队列人工处理。
java@Entity
public class User {
@Id
private Long id;
@Version
private Long version; // 乐观锁版本号
// 其他字段...
}
注意
以上仅为demo实现,具体可根据思路自行扩展,例如可以将存储的本地事务消息添加状态,在消费者中可以先查询缓存版本号与当前消息的版本号进行对比,对比不通过则更新缓存,缓存处理成功时,查询一次最新缓存的版本号与事务版本号对比,如果对比成功则对本地事务消息的状态进行更新。
这个时候,定时任务只需要扫描缓存未更新的情况即可,而无需全量扫描。
补偿与降级
添加双重保障机制,消息队列保证主流程,通过定时任务兜底检查,如果版本不一致也可以添加补偿缓存数据,保证数据的最终一致性。同时查询方法添加降级策略,保证服务的高可用。
补偿任务(兜底机制)
java@Scheduled(fixedDelay = 30000)
public void checkInconsistency() {
// 查询最近更新的数据库记录
List<User> recentUsers = userRepository.findUpdatedLast5Minutes();
recentUsers.forEach(user -> {
String key = "user:" + user.getId();
User cachedUser = (User) redisTemplate.opsForValue().get(key);
// 比较数据库与缓存的数据版本
if (cachedUser == null ||
cachedUser.getVersion() < user.getVersion()) {
// 触发缓存更新
redisTemplate.opsForValue().set(key, user);
}
});
}
熔断降级策略
java// 当缓存更新失败时降级
public User getUser(Long id) {
try {
return cacheService.getUser(id);
} catch (Exception e) {
log.warn("缓存降级,查询数据库");
return userRepository.findById(id).orElse(null);
}
}
方案评估
方案的整体效果上,通过高性能的 RocketMQ 可以保障最终一致性达到秒级。不过会对性能产生一些影响:由于添加了消息发送,会给业务流程操作增加部分耗时。同时依赖 MQ 中间件,要注意消息堆积,消息幂等,消息的可靠性处理
此方案的核心原则:容忍短暂不一致,保证最终一致;优先保障核心存储,非核心系统可降级;始终设计补偿机制。
同步双写,失败补偿
补偿机制的核心思想是:当主操作成功但辅助操作失败时,通过后续的补偿操作来达到数据一致的状态。在双写场景中,补偿机制通常用于在数据库更新成功但缓存更新失败时,通过定时任务或后台线程来修复缓存的不一致状态。
补偿机制方案设计
方案本质就是双写,不成功就重试,重试多次不成功,则告警通知,主体流程如下:
-
主操作:先更新数据库(事务操作),再更新缓存(或发送消息更新缓存)
-
失败检测:当数据库更新失败时,直接失败,无需处理缓存操作
-
缓存更新:数据库事务提交成功,开始执行缓存
-
异步补偿:如果缓存更新失败,通过线程池进行异步补偿
-
重试策略:补偿采用指数退避重试,设置最大重试次数,避免雪崩
-
最终处理:超过最大重试次数后,发出告警,人工介入
核心代码
定义基础的补偿架构支撑
java@Slf4j
@Component
public class CompensableTransaction<T> {
/**
* 最大重试次数
*/
private static final int MAX_RETRY = 3;
/**
* 静态线程池
*/
static class CompensableThreadPool {
private static final AtomicInteger number = new AtomicInteger(1);
public static final ThreadPoolExecutor executor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
Runtime.getRuntime().availableProcessors() * 2,
60,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
r -> new Thread(r, "CompensableTransaction-thread-" + number.getAndIncrement()),
new ThreadPoolExecutor.CallerRunsPolicy());
}
/**
* 执行
*/
@SneakyThrows
public void execute(String operation, Callable<T> doPrimaryAction, Consumer<T> doSecondaryAction, Consumer<T> doCompensate) {
// 执行主操作
T call = doPrimaryAction.call();
try {
// 执行辅助操作
doSecondaryAction.accept(call);
} catch (Exception e) {
// 异步补偿
CompensableThreadPool.executor.execute(() -> {
// 补偿操作
int retryCount = 0;
while (retryCount < MAX_RETRY) {
try {
// 自定义补偿逻辑,成功则返回
doCompensate.accept(call);
return;
} catch (Exception ex) {
retryCount++;
log.warn("补偿操作失败({}/{}): {}", retryCount, MAX_RETRY, ex.getMessage());
// 指数
try {
TimeUnit.MILLISECONDS.sleep(exponentialBackoff(retryCount));
} catch (InterruptedException exc) {
log.error("{}补偿操作线程被中断", operation);
return;
}
}
}
// 最终补偿失败
log.error("{}补偿操作最终失败", operation);
alertAdmin(operation);
});
}
}
private void alertAdmin(String operation) {
// 发送告警邮件、短信、钉钉消息
log.info("发送告警邮件、短信、钉钉消息");
}
/**
* 根据重试次数计算指数停顿时间
*/
private long exponentialBackoff(int retryCount) {
// 100ms, 200ms, 400ms...
return (long) (100 * Math.pow(2, retryCount));
}
}
数据库 + 缓存双写实现
java@Service
public class ImUsersServiceImpl extends ServiceImpl<ImUsersMapper, ImUsers> implements ImUsersService {
@Resource
private CompensableTransaction<ImUsers> compensableTransaction;
/**
* 初始化用户信息
*
* @param userInfo 微信用户信息
*/
@Override
public void initUser(WxOAuth2UserInfo userInfo) {
// 主操作
Callable<ImUsers> primaryAction = () -> {
// 保存用户信息
ImUsers users = BeanUtil.toBean(userInfo, ImUsers.class);
this.save(users);
// 登录
StpUtil.login(users.getId());
return users;
};
// 辅助操作
Consumer<ImUsers> secondaryAction = users -> {
// 缓存用户信息
UserInfo info = BeanUtil.toBean(users, UserInfo.class);
RedisCacheUtil.hPutAll(String.format(RedisKeyDefine.USER_INFO, users.getId()), BeanUtil.beanToMap(info));
};
// 补偿操作
Consumer<ImUsers> compensateAction = users -> {
String key = String.format(RedisKeyDefine.USER_INFO, users.getId());
if (!RedisCacheUtil.hasKey(key)) {
RedisCacheUtil.hPutAll(String.format(RedisKeyDefine.USER_INFO, users.getId()), BeanUtil.beanToMap(users));
}
};
compensableTransaction.execute("初始化用户信息", primaryAction, secondaryAction, compensateAction);
}
}
此处定义了3个步骤操作:
- 主操作,就是事务提交的方法
- 辅助操作,就是缓存等需要双写的方法
- 补偿操作,当辅助操作失败后,进行补偿操作,可直接复用辅助操作,也可自定义其他处理,例如删除缓存
在实现以上补偿机制的同时,还要注意补偿失败情下的补偿,做好补偿的监控体系,关注补偿的失败率统计与失败的问题定位,进行人工干预补偿,也可定时扫描补偿,就不在过多陈述
补偿机制优缺点分析
其实补偿方案实现相对简单,不依赖其他中间件,补偿操作异步执行对性能影响小,同时保证最终一致性,可靠性比较高。
但也存在一些缺点,在高并发流量下,会存在一定的脏读,就是数据库更新了,缓存还没更新,存在短暂数据不一致的情况,这也是不可避免的;
在一个就是如果 Redis 缓存挂掉了,会导致线程池阻塞,存在性能瓶颈,同时补偿操作本身可能失败,极端情况下需要人工干预。
提示
我个人更加推荐同步双写,失败补偿的方案,适用于大多数并发不高,可接受短暂脏数据的系统。
延迟双删方案
延迟双删是一种在双写场景中用于保证缓存与数据库一致性的策略。它主要用于解决在更新数据库和缓存时,由于并发操作导致的脏数据问题。
核心思想
延迟双删是解决缓存与数据库双写一致性的经典策略,其核心流程为:
-
先删缓存 - 避免旧数据污染
-
更新数据库 - 完成持久化操作
-
延迟删除缓存 - 消除并发期间产生的脏数据
先删除缓存 -> 更新数据库 -> 延迟一段时间(比如几百毫秒) -> 再次删除缓存
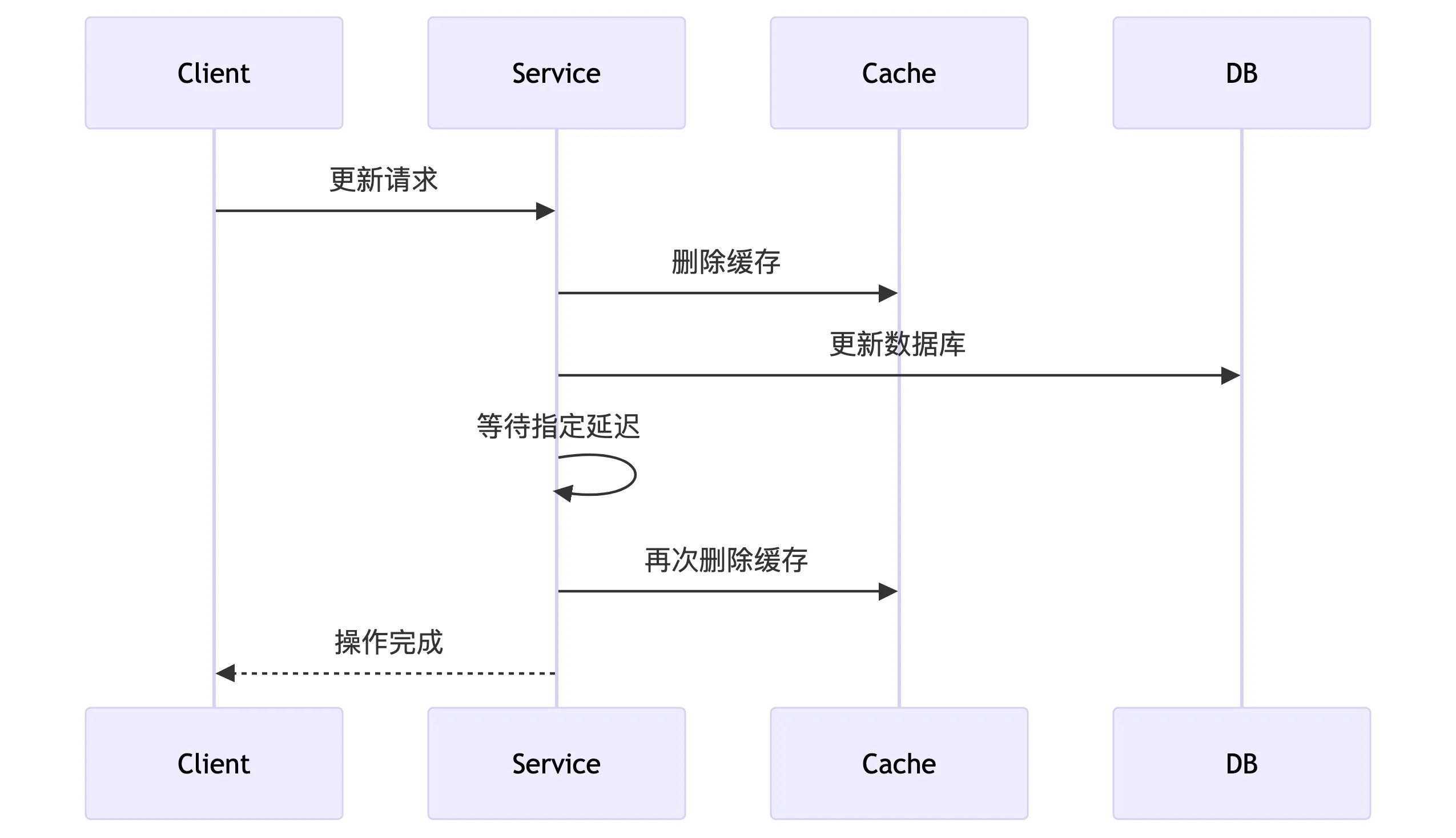
为什么需要延迟双删?
考虑以下并发场景:
-
线程A更新数据,先删除缓存,然后准备更新数据库。
-
此时线程B来读取数据,发现缓存不存在,于是从数据库读取旧数据,并写入缓存。
-
线程A更新数据库,然后等待一段时间(确保线程B的读操作完成并写入缓存)后再次删除缓存。
这样,线程B写入的旧数据缓存会被第二次删除,后续读取会重新加载最新数据。
核心代码
业务代码的基础实现
java@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
private final RedisTemplate<String, Object> redisTemplate;
private final ScheduledExecutorService scheduler =
Executors.newScheduledThreadPool(4);
// 更新操作入口
@Transactional
public void updateUser(User user) {
String cacheKey = "user:" + user.getId();
// 1. 先删除缓存
deleteCache(cacheKey);
// 2. 更新数据库
userRepository.save(user);
// 3. 提交事务后发起延迟双删
scheduler.schedule(() -> {
deleteCacheWithRetry(cacheKey, 3); // 带重试的二次删除
}, 500, TimeUnit.MILLISECONDS); // 延迟500ms
}
// 带重试机制的缓存删除
private void deleteCacheWithRetry(String key, int maxRetry) {
int retryCount = 0;
while (retryCount < maxRetry) {
try {
redisTemplate.delete(key);
log.info("延迟双删成功: {}", key);
return;
} catch (Exception e) {
retryCount++;
log.warn("缓存删除失败({}/{}): {}", retryCount, maxRetry, key);
try {
Thread.sleep(100 * retryCount); // 指数退避
} catch (InterruptedException ignored) {}
}
}
log.error("缓存删除最终失败: {}", key);
}
}
优化版 - 结合版本号校验
java// 实体类增加版本控制
@Entity
public class User {
@Id
private Long id;
@Version
private Long version; // 乐观锁版本号
// 其他字段...
}
// 服务层增强校验
public void updateUserWithVersion(User user) {
String cacheKey = "user:" + user.getId();
// 1. 先删除缓存
redisTemplate.delete(cacheKey);
// 2. 更新数据库(带版本校验)
try {
userRepository.save(user);
} catch (OptimisticLockingFailureException ex) {
// 版本冲突时重新加载数据
User freshUser = userRepository.findById(user.getId()).orElseThrow();
throw new ConcurrentUpdateException("数据已被修改,请刷新重试");
}
// 3. 延迟双删(携带版本信息)
scheduler.schedule(() -> {
Object cached = redisTemplate.opsForValue().get(cacheKey);
if (cached instanceof User) {
User cachedUser = (User) cached;
// 仅当缓存版本较旧时删除
if (cachedUser.getVersion() < user.getVersion()) {
redisTemplate.delete(cacheKey);
}
}
}, 600, TimeUnit.MILLISECONDS);
}
生产级增强方案
java@Component
public class CacheDoubleDeleteManager {
private final RedisTemplate<String, Object> redisTemplate;
private final RedissonClient redissonClient;
private final DelayQueue<DeleteTask> delayQueue = new DelayQueue<>();
@PostConstruct
public void init() {
// 启动处理线程
new Thread(this::processTasks).start();
}
// 添加延迟双删任务
public void scheduleDelete(String key, long delayMs) {
delayQueue.put(new DeleteTask(key, delayMs));
}
// 任务处理核心
private void processTasks() {
while (!Thread.currentThread().isInterrupted()) {
try {
DeleteTask task = delayQueue.take();
RLock lock = redissonClient.getLock(task.key + ":lock");
try {
if (lock.tryLock(1, 5, TimeUnit.SECONDS)) {
redisTemplate.delete(task.key);
}
} finally {
lock.unlock();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 延迟任务对象
private static class DeleteTask implements Delayed {
final String key;
final long executeTime;
DeleteTask(String key, long delayMs) {
this.key = key;
this.executeTime = System.currentTimeMillis() + delayMs;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(executeTime - System.currentTimeMillis(),
TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return Long.compare(executeTime, ((DeleteTask)o).executeTime);
}
}
}
延迟双删优缺点分析
延迟双删是平衡性能与一致性的有效方案,以可控延迟换取更高吞吐,适用于写少读多、可接受短暂不一致的业务
优势:
-
有效解决"读请求在更新期间加载旧数据"问题
-
实现简单,不依赖复杂中间件
-
性能影响可控(异步化处理)
-
兼容各种数据库和缓存类型
局限性:
-
短暂不一致窗口(延迟期间)
-
删除操作可能失败(需配合重试)
-
不保证强一致性(最终一致)
-
延迟时间需根据业务调优
注意
没有完美的解决方案,只有最适合场景的方案。延迟双删在电商库存、用户配置等场景表现优异,但对金融交易等强一致性场景需慎重使用。
主流方案对比
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 基于消息队列 | 通过消息队列保证最终一致性 | 高可靠性,解耦系统 | 实现复杂,依赖中间件 |
| 补偿机制 | 失败后执行反向操作 | 简单易实现,适用性高 | 高并发下数据短暂不一致性 |
| 延迟双删策略 | 更新前后删除缓存 | 缓解脏读问题 | 不能完全避免不一致 |
总结
保障双写一致性没有银弹,需要根据业务场景选择合适方案。注意每种方案完善重试机制,最好结合版本控制,每种方案的监控+告警+兜底三位一体必不可少。
本文展示的基于主流的解决方案进行讲述。在实际应用中还需结合监控(如缓存命中率、不一致告警)和压力测试持续优化。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!