
目录
订单业务一直都是系统研发中的核心模块,订单的产生过程,与系统中的很多模块都会高度关联,比如账户体系、支付中心、运营管理、库存扣减、物流管理等,即便单看订单本身,也足够的复杂
上一篇聊完 电商业务 - 秒杀,接下来聊一下订单业务的场景,这也是大多数技术的应用实践业务。
订单
业务在发展的过程中,必然会导致订单量的持续增加,订单自身、数据体量、实现流程,都需要不断的迭代更新,如果在订单流程的研发初期,没有相对全面的考量,那么很有可能导致中后期的重构;
从实践经验上说,围绕订单业务:建议过度设计,轻量级分步实现
在产品初期先做好全面的设计,场景和流程上做好可扩展性的保留,在数据层面规划好不同体量的应对方案,走在订单业务的前面避免被动,尽量不要被业务的发展和演变甩在身后;
订单的整体体系如下:
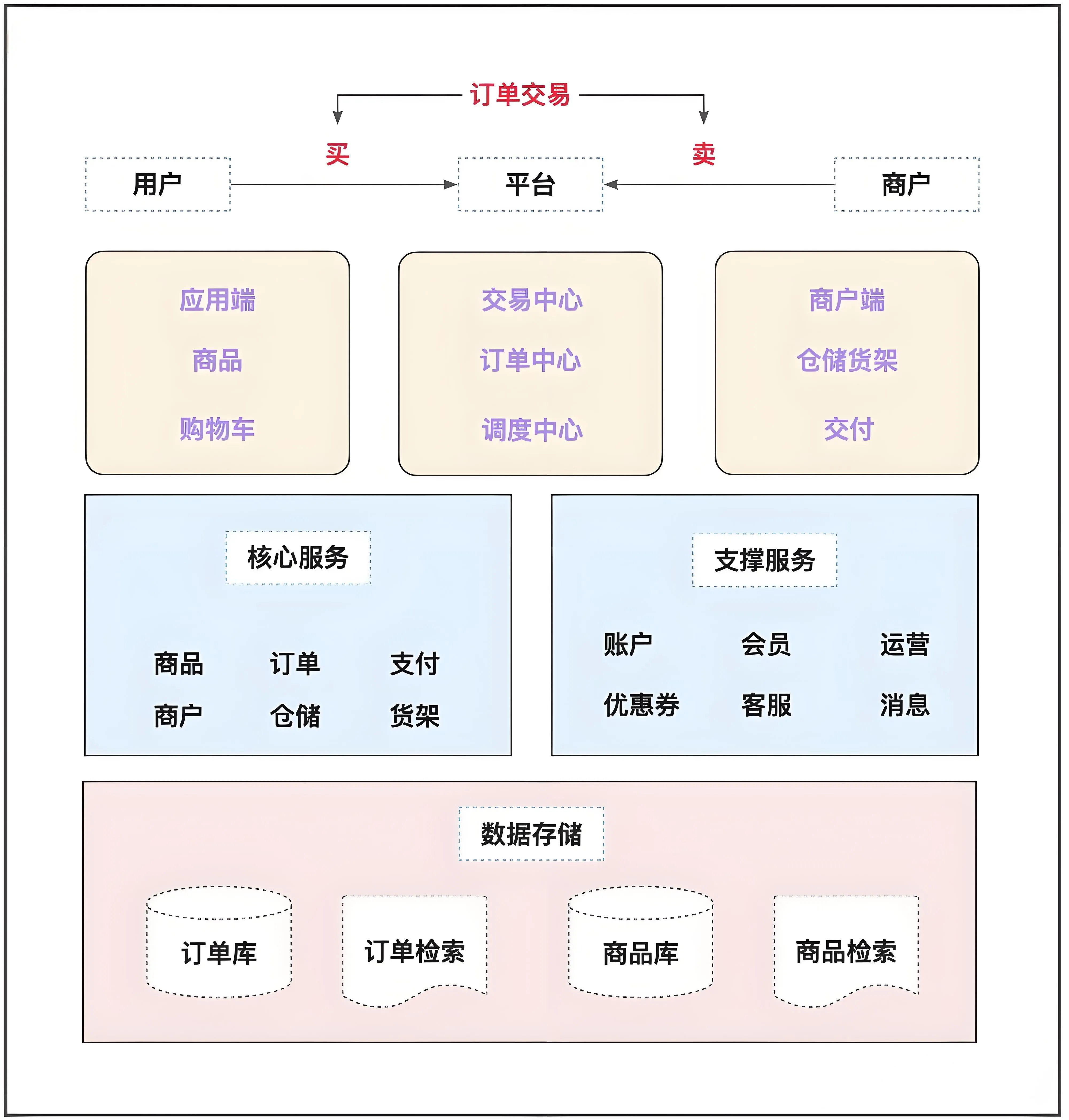
业务体系分析
商品的创建(SPU 与 SKU)
在电商系统中,商品管理的核心是 SPU(标准化产品单元) 和 SKU(库存量单位)。SPU 代表商品的通用属性,例如品牌、型号、描述等,而 SKU 则是具体规格变体的唯一标识,例如颜色、尺寸、价格等。这种分层设计允许同一 SPU 下存在多个 SKU,满足差异化销售需求。
-
SPU(Standard Product Unit):标准化产品单元(简称产品),是一组可复用、易检索的标准化信息的集合,描述了一个产品的特性。例如:iPhone 12 是一个SPU。
-
SKU(Stock Keeping Unit):库存量单位(简称商品),是物理上不可分割的最小存货单元。例如:iPhone 12 红色 128GB 是一个SKU。
商品的创建过程中,会根据产品 SPU 的规格属性进行 笛卡尔乘积 计算,例如手机分类下存在 颜色(属性值有 红色、黑色、蓝色 )、内存(属性值有256、512 ) 2个规格属性,那对应手机分类下的 SPU iPhone 12 的 SKU 商品有 红色+256、黑色+256、蓝色+256、红色+512、黑色+512、蓝色+512 6款商品。
加深理解
从上述的描述中,我们了解了SPU与SKU的关系,结合我们的日常生活中购买手机的场景,你是否遇到过切换手机颜色,对应内存的某个属性下是置灰的,提示没有库存,是不可购买的,感兴趣的小伙伴可以自行探索一下。
下单全流程
下单流程是用户购买行为的核心路径,通常包括 浏览商品、加入购物车、确认订单、支付、发货、收货 等环节。流程图需涵盖以下关键步骤:
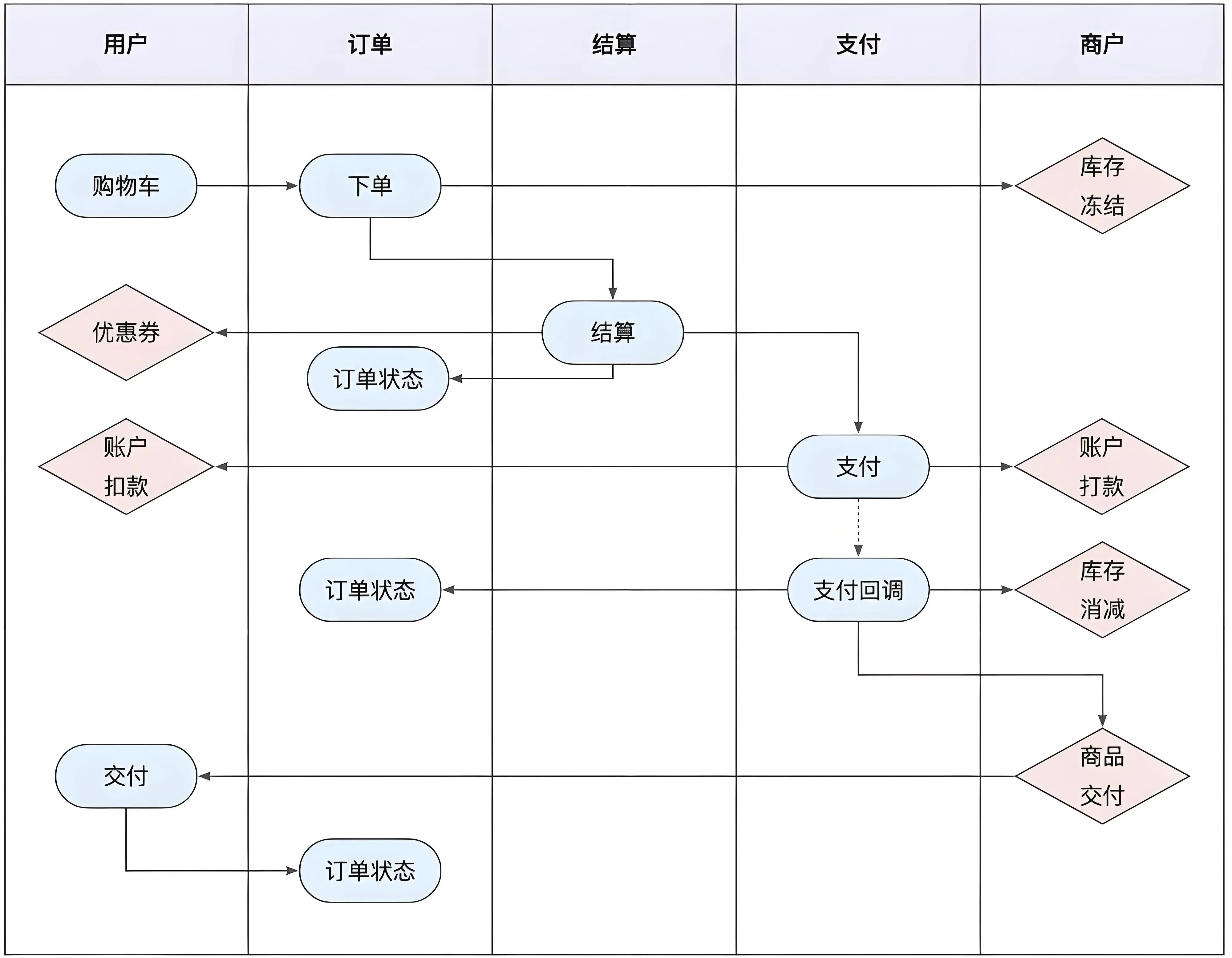
订单的拆分,主单与子订单
下单
当用户购买的商品来自不同商家或需分批次发货时,系统需将订单拆分为 主单 和 子订单。主单记录整体交易信息,子订单则对应每个商家或物流批次的明细。例如:
用户购买 A 商家的商品 X 和 B 商家的商品 Y,系统生成主单 O1,拆分为子订单 O1-1(A 商家)和 O1-2(B 商家)。
拆分逻辑需满足以下条件:
- 商家隔离:不同商家的商品必须拆分为独立子订单;
- 物流隔离:若商品需分仓发货,按仓库拆分;
- 支付隔离:支持子订单独立支付(如部分退款)。
数据库设计中,主订单表(main_order)存储总订单信息,子订单表(sub_order)通过 main_order_id 关联,并记录商家信息和状态。
退货
在电商系统中,当一个订单包含多个商品,用户仅需要退货其中一个商品时,系统需要支持 部分退货 的业务逻辑。这种场景下,订单本身不会被整体取消,而是针对具体的某个或某些商品发起售后申请,其余商品仍保持正常状态。此时,系统通常会创建一个独立的**售后单(如退换单)**来管理该次退货请求,而不是直接修改原订单的状态。
在子订单级别添加退货标志,并且在主订单中汇总这些信息。例如,如果一个主订单中有三个子订单,其中一个被退货,则该子订单应标记为“退货”,而主订单则可以有一个字段来记录退货的商品数量或金额比例。
在整个过程中,原订单仍然存在且其他商品状态不受影响,确保了订单生命周期的完整性与可追溯性。同时,售后单与原订单通过订单号或商品 SKU 建立关联,便于后续统计、对账和客服查询。这样的设计也支持更细粒度的售后服务,比如仅退款不退货、换货、维修等多种类型。
订单的逆向流程
对于订单这种极度复杂的流程,导致订单流程逆向的情况,像订单的创建、支付的超时、支付失败等异常流程,要细致的考虑并且提供相应的解决方案,尽量确保程序可以兜底流程逆向,人工干预的成本和风险都极高
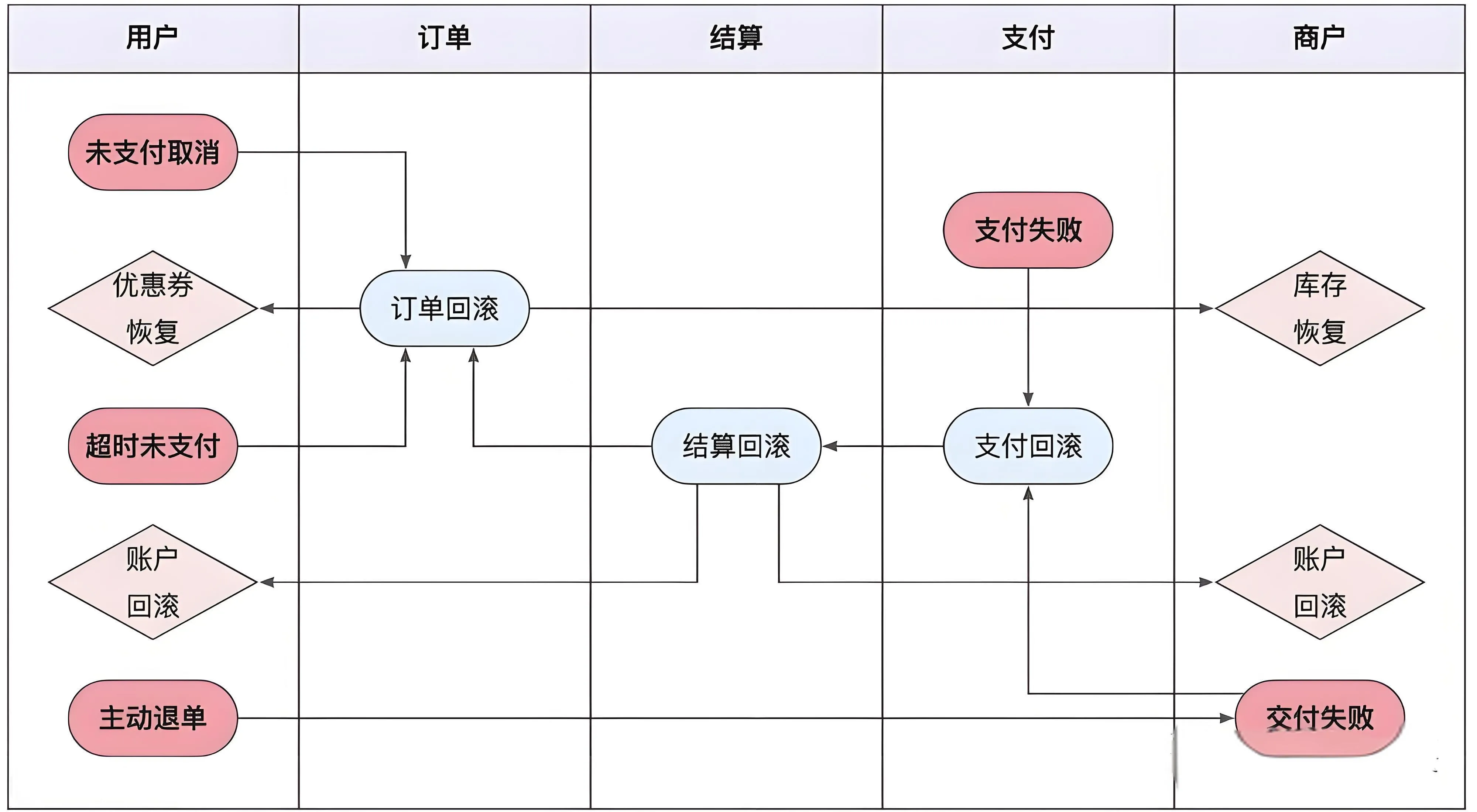
关键点包括:
- 状态机设计:明确逆向订单的状态转换(如待审核、已寄回、已退款);
- 事务一致性:确保退款与库存回滚的原子性;
- 用户通知:通过短信/邮件实时同步处理进度
调度与监控
订单属于核心流程又兼具复杂的特性,自然依赖系统平台的调度与监控手段,无论是正向还是逆向流程,都依赖调度手段提高订单的完成率,或者促使逆向流程有序执行,在这个过程中需要对订单路径有完整的监控能力
订单系统的稳定性依赖 调度与监控 机制。调度任务包括:
- 超时订单自动关闭:未支付订单超过设定时间(如 30 分钟)自动取消;
- 库存预警:库存低于阈值时触发补货提醒;
- 对账任务:定期比对订单与支付流水,发现异常单。
- 自动提醒发货:对有时间限制的发货订单进行提醒
监控需覆盖以下指标:
- 订单处理延迟:从下单到发货的时间;
- 支付成功率:支付接口的成功率统计;
- 履约异常率:异常订单占比。
- 订单创建成功率:下单成功的订单
调度机制:更侧重订单被动状态的处理,多见于各种超时的场景,用来提前对用户和商户进行消息提醒触达,或者进行订单流程的处理;
监控策略:更侧重对订单的主动干预处理,在发现订单中断或者异常时,可以通过产品层面的入口进行主动修复,或者系统层面的主动重试,当然也不排除最后的手动干预;
技术方案实现
数据库的设计
购物车的存储
购物车是电商系统的标配功能,暂存用户想要购买的商品,主要分为添加商品、列表查看、结算下单三个动作。
技术设计并不是特别复杂,存储的信息也相对有限(用户id、商品id、sku_id、数量、添加时间),使用 Redis hash 存储临时购物车数据,定期将 Redis 数据同步到数据库(如 MySQL),避免丢失
redis# Redis存储结构 HSET cart:{user_id} {sku_id} {quantity} # 集群部署方案: 1. 按user_id分片 2. 设置7天过期时间 3. 双写机制保障可靠性
重复下单
在商品结算下单时,需要前后端一起进行控制
- 幂等性校验:通过订单号或业务流水号判断是否已存在;
- 前端防重:限制用户重复点击提交按钮。
幂等机制,多次请求和一次请求产生的效果是一样的
当用户点击购买按钮时,访问数据渲染下单页面,同时后端会返回一个 Token 令牌 并存储到 Redis 中 原子操作:SET token 1 EX 300 NX,同一个 Token 令牌只能用一次,用完后立马失效掉
java /**
* 进入产品页,获取token,防止下单接口盗刷,防重复提交
*
* @param userId 用户ID
* @param skuId skuID
* @return token
*/
@GetMapping("/order/{skuId}")
public String orderCode(@RequestHeader String userId, @PathVariable String skuId) {
// 有效期 - 随机10分钟的秒数 + 2小时秒数
int se = new Random().nextInt(10 * 60) + 2 * 60 * 60;
System.out.println("有效期:"+se);
String token = UUID.fastUUID().toString();
redisUtils.setEx(skuId + ":" + userId, token + "-0", se, TimeUnit.SECONDS);
return token;
}
用户提交订单时,后端业务逻辑会校验 Token 令牌是否存在,根据返回的内容进行区分是异常访问、重复提交还是令牌过期
java /**
* 订单提交
*/
@GetMapping("/order/submit")
public String secKillSyn(@RequestHeader String userId, @RequestParam String skuId, @RequestParam String token, HttpServletResponse response) {
// redis key
String key = skuId + ":" + userId;
// 有效期 - 10分钟秒数
int se = (int)TimeUnit.MINUTES.toSeconds(10);
// 执行lua脚本
Long status = redisUtils.execute(RedisScript.of(new ClassPathResource("lua/fangchong.lua"), Long.class), Collections.singletonList(key), token, se);
Asserts.state(Long.valueOf(1).equals(status), Re.fail().setMessage("请勿重复提交"));
Asserts.state(Long.valueOf(2).equals(status), Re.fail().setMessage("页面已失效,请刷新重试"));
return "success";
}
幂等校验的lua脚本:
lualocal re = function()
-- token,替换掉"
local token = string.gsub(ARGV[1],'"','')
-- 初始value
local status = redis.call('get', KEYS[1])
-- 状态0,未提交
local status0 = token..'-0'
-- 状态1,重复提交
local status1 = token..'-1'
-- key对应的value,value不存在,表示非法请求、或key已过期
if status then
-- 是状态0,第一次访问
if status == status0 then
-- 更新状态
redis.call('set', KEYS[1], status1, 'EX', ARGV[2])
return 0
else
-- 是状态1,多次访问
if status == status1 then
return 1
else
return 2
end
end
else
return 2
end;
end
return re
订单号的生成策略
订单号需具备唯一性与可读性,生成策略大多与日期、userId、一个递增的序列号有关,常用的生成策略如下:
- 时间戳+序列号:如 20250531123456789012(年月日时分秒+序列号);
- Snowflake 算法:分布式 ID 生成,保证全局唯一;
- 自定义规则:包含商家编码、用户 ID 等业务标识。
在实践的过程中,建议避免连续和可猜测性,加入随机因子
避免单调递增
我们单号中一般都添加了一个序列号,严格单调递增会暴露业务量,趋势递增的随机性防止推测业务规模
订单快照,如何减少存储成本
商品信息是可以修改的,当用户下单后,为了更好解决后面可能存在的买卖纠纷,创建订单时会同步保存一份商品详情信息,称之为订单快照。
同一件商品,会有很多用户会购买,如果热销商品,短时间就会有上万的订单。如果每个订单都创建一份快照,存储成本太高。另外商品信息虽然支持修改,但毕竟是一个低频动作。我们可以理解成,大部分订单的商品快照信息都是一样的,除非下单时用户修改过,所以如何实时识别修改动作是解决快照成本的关键所在。
- 增量存储:仅保存关键字段(如价格、商品名称);
- 压缩技术:对文本字段(如商品描述)使用 GZIP 压缩;
- 归档策略:定期将旧订单迁移到低成本存储(如对象存储)。
我们采用增量存储的方法:
每次商品信息变更时,都会新增一条最新版本的快照记录,而创建的订单会关联商品当前最新的快照主键,由于订单快照属于非核心操作,即使失败也不应该影响用户正常购买流程,所以通常采用异步流程执行。
订单超时的实现
订单超时需定时扫描未支付订单并自动关闭
- 定时任务:使用分布式任务调度:XXL-JOB、Quartz 或 Spring Scheduler 定期执行;
- 消息队列:通过延迟队列(如 RocketMQ:支持18个延迟级别、RabbitMQ 的 TTL)触发超时事件;
- Redis ZSET:时间轮询方案
大多数情况下都是使用万金油的 mq延迟队列进行实现的,对于主流方案的优缺点、对比与选型可查看 电商业务 - 订单超时取消 一文
RabbitMQ延时后发送到死信队列处理
通过 RabbitMQ 消息队列的 TTL和 DXL这两个属性间接实现的。
DLX即死信交换机,绑定在死信交换机上的即死信队列。
RabbitMQ的Queue(队列)可以配置两个参数x-dead-letter-exchange和x-dead-letter-routing-key(可选),一旦队列内出现了Dead Letter(死信),则按照这两个参数可以将消息重新路由到另一个Exchange(交换机),让消息重新被消费。
实现超30分钟未支付关单功能,我们将订单消息A0001发送到延迟队列order.delay.queue,并设置x-message-tt消息存活时间为30分钟,当到达30分钟后订单消息A0001成为了Dead Letter(死信),延迟队列检测到有死信,通过配置x-dead-letter-exchange,将死信重新转发到能正常消费的关单队列,直接监听关单队列处理关单逻辑即可。
怎么避免库存超卖
针对于此类业务场景,需要结合实际业务,库存扣减方式有以下几种
- 下单减库存
即当买家下单后,在商品的总库存中减去买家购买数量。下单减库存是最简单的减库存方式,也是控制最精确的一种,下单时直接通过数据库的事务机制控制商品库存,这样一定不会出现超卖的情况。但是你要知道,有些人下完单可能并不会付款。
- 付款减库存
即买家下单后,并不立即减库存,而是等到有用户付款后才真正减库存,否则库存一直保留给其他买家。但因为付款时才减库存,如果并发比较高,有可能出现买家下单后付不了款的情况,因为可能商品已经被其他人买走了。
- 预扣库存
这种方式相对复杂一些,买家下单后,库存为其保留一定的时间(如 30 分钟),超过这个时间,库存将会自动释放,释放后其他买家就可以继续购买。在买家付款前,系统会校验该订单的库存是否还有保留:如果没有保留,则再次尝试预扣;如果库存不足(也就是预扣失败)则不允许继续付款;如果预扣成功,则完成付款并实际地减去库存。
对于库存扣减产生的超卖问题与秒杀中库存的扣减类似,可以通过 Redis lua 脚本的原子操作预减库存,也可以添加售罄标记进行快速拦截。
还有一种对分布式锁优化方案,我们来先思考下分布式锁的方案在高并发场景下有什么问题?
分布式锁的方案在高并发场景下有什么问题?
分布式锁一旦加了之后,对同一个商品的下单请求,会导致所有客户端都必须对同一个商品的库存锁key进行加锁。导致对同一个商品的下单请求,就必须串行化,一个接一个的处理。这种方案,要是应对那种低并发、无秒杀场景的普通小电商系统,可能还可以接受
并发量很低,每秒就不到10个请求,没有瞬时高并发秒杀单个商品的场景的话,其实也很少会对同一个商品在一秒内瞬间下1000个订单,因为小电商系统没那场景。
在高并发场景下如何优化分布式锁的并发性能?
很多人看过java里的ConcurrentHashMap的源码和底层原理,应该知道里面的核心思路,就是 分段加锁
把数据分成很多个段,每个段是一个单独的锁,所以多个线程过来并发修改数据的时候,可以并发的修改不同段的数据,不至于说,同一时间只能有一个线程独占修改ConcurrentHashMap中的数据。
另外,Java 8中新增了一个LongAdder类,也是针对Java 7以前的AtomicLong进行的优化,解决的是CAS类操作在高并发场景下,使用乐观锁思路,会导致大量线程长时间重复循环。LongAdder中也是采用了类似的分段CAS操作,失败则自动迁移到下一个分段进行CAS的思路。
其实分布式锁的优化思路也是类似的,之前我们是在另外一个业务场景下落地了这个方案到生产中,不是在库存超卖问题里用的。
优化分布式锁扣减库存的实现
假如你现在iphone有1000个库存,那么你完全可以给拆成20个库存段,要是你愿意,可以在数据库的表里建20个库存字段,比如stock_01,stock_02,类似这样的,也可以在redis之类的地方放20个库存key。
总之,就是把你的1000件库存给他拆开,每个库存段是50件库存,比如stock_01对应50件库存,stock_02对应50件库存。
接着,每秒1000个请求过来了,好!此时其实可以是自己写一个简单的随机算法,每个请求都是随机在20个分段库存里,选择一个进行加锁。
bingo!这样就好了,同时可以有最多20个下单请求一起执行,每个下单请求锁了一个库存分段,然后在业务逻辑里面,就对数据库或者是Redis中的那个分段库存进行操作即可,包括查库存 -> 判断库存是否充足 -> 扣减库存。
一旦对某个数据做了分段处理之后,有一个坑大家一定要注意:就是如果某个下单请求,咔嚓加锁,然后发现这个分段库存里的库存不足了,此时咋办?
这时你得自动释放锁,然后立马换下一个分段库存,再次尝试加锁后尝试处理。这个过程一定要实现。
缺点
代码实现太复杂了。不过我们确实在一些业务场景里,因为用到了分布式锁,然后又必须要进行锁并发的优化,又进一步用到了分段加锁的技术方案,效果当然是很好的了,一下子并发性能可以增长几十倍。
商家发货,物流单更新ABA问题
过程
开始「请求A」发货,调订单服务接口,更新运单号 123,但是响应有点慢,超时了。此时,商家发现运单号填错了,发起了「请求B」,更新运单号为 456 ,订单服务也响应成功了,但是,「请求A」触发了重试,再次调用订单服务,更新运单号 123,订单服务也响应成功了,订单服务最后保存的 运单号 是 123
解决
乐观锁思想,引入版本号 version,每次更新时,判断表中的版本号与请求参数携带的版本号是否一致
sqlupdate orderset logistics_num = #{logistics_num} , version = {version} + 1where order_id= 1111 and version = #{version}
一致:才触发更新;不一致:说明这期间执行过数据更新,可能会引发错误,拒绝执行。
其他解决方式
可以通过 操作日志审计 与 限制单号修改次数 来进行控制
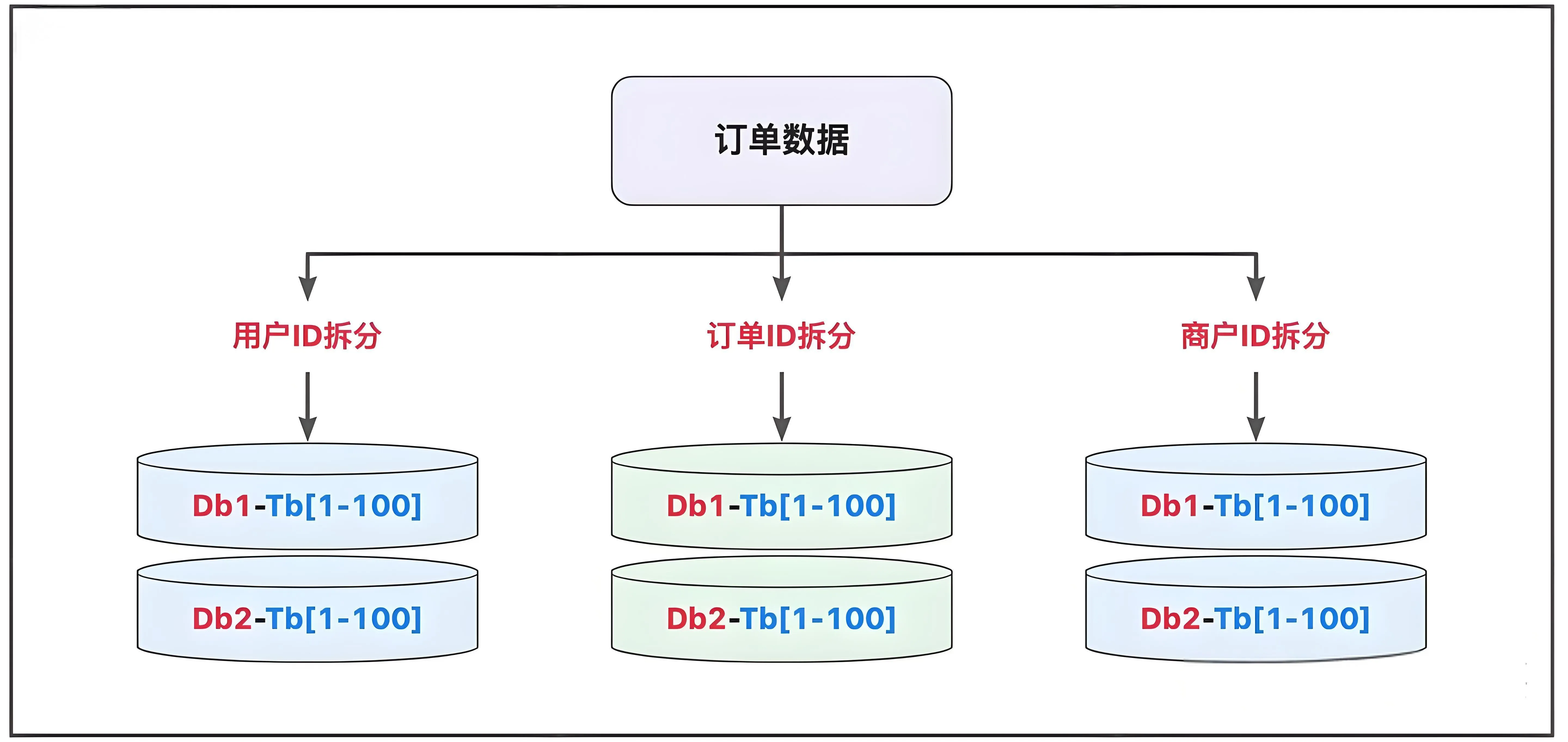
订单分库分表,多维度查询
数据在到达一定体量之后,需要进行分库分表的操作,从而解决各种性能方面的问题;将订单数据按照特定的维度进行计算,从而将数据分流到不同的库表中,解决读和写的瓶颈;
策略
- 水平分表:按订单号哈希分片,或按时间范围分表;
- 垂直分库:将订单表与支付表分离到不同数据库;
- 中间件:使用 ShardingSphere 或 MyCAT 实现透明分片。
基于订单ID计算拆分的逻辑是最常见的,在特殊情况下,也会基于用户ID或商户ID进行计算,从而将相关的数据堆放在一起,如果有必要,也可以考虑多维度拆分的多写模式
yaml# ShardingSphere配置示例
rules:
- !SHARDING
tables:
orders:
actualDataNodes: ds_${0..3}.orders_${0..15}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: mod_hash
databaseStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: mod4
商品的检索
订单数据分库分表虽然解决存储问题,但是也带来了很多查询方面的阻碍,其中商品检索需支持高性能全文搜索
技术方案
- Elasticsearch:建立商品索引,支持模糊搜索与过滤;
- 缓存优化:热门商品缓存到 Redis,减少数据库压力;
- 分页与排序:按价格、销量等字段排序,分页加载结果。
ES的实现思路
es### Elasticsearch索引设计 PUT /products { "mappings": { "properties": { "spu_name": {"type": "text", "analyzer": "ik_max_word"}, "sku_specs": {"type": "keyword"}, "category_id": {"type": "integer"}, "price": {"type": "double"}, "stock": {"type": "integer"} } } } ### 查询优化: 1. 分词器选择:ik_smart/ik_max_word 2. 多条件组合过滤 3. 聚合统计库存
订单数据在库和搜索引擎之间同步的方法有很多:
- 同步双写,对数据的实时性要求极高;
- 异步解耦,流程存在轻微的延迟;
- 定时任务,存在明显的时效问题;
- 组件同步,采用第三方数据同步组件;
订单场景的话推荐同步双写的方式。
历史订单归档
根据二八定律 ,系统绝大部分的性能开销花在20%的业务。数据也不例外,从数据的使用频率来看,经常被业务访问的数据称为热点数据;反之,称之为冷数据。
在了解的数据的冷、热特性后,便可以指导我们做一些有针对性的性能优化。这里面有业务层面的优化,也有技术层面的优化。比如:电商网站,一般只能查询6个月内的订单,如果你想看看6个月前的订单,需要访问历史订单页面。
历史订单归档可降低数据库负载。策略:
- 冷热分离:将 6 个月前的订单迁移到归档表或对象存储;
- 定期任务:通过定时任务执行归档操作;
- 查询优化:归档数据通过独立接口提供查询服务。
实现思路
sql-- 数据迁移方案
INSERT INTO orders_archive
SELECT * FROM orders
WHERE create_time < '2023-01-01'


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!