
目录
电商领域的业务是我们IT绕不开的话题,对于电商领域的业务体系,在开发生涯中有很强的借鉴意义,同时对于拓展熟悉其他业务领域的个性化玩法有很大帮助。
电商系统的复杂性很高,对高并发 、高性能 、高可用等方面要求很高。你在其他业务中可能遇到的问题,在电商系统中基本都会遇到,接下来我将会 秒杀、订单、支付 3个经典场景进行描述。
什么是秒杀?
“秒杀”是指在有限的时间内对有限的商品数量进行抢购的一种行为,这是商家以“低价量少”的商品来获取用户的一种营销手段。
秒杀特点
- 瞬时并发访问量很高
一般DB每秒只能支撑k级并发,而Redis并发能达到w级。所以,当大量并发请求涌入秒杀系统时,要使用Redis先拦截大部分请求,避免大量请求直接发给DB
- 读多写少
读还是简单的查询操作
秒杀下,用户需先查验商品是否还有库存(即根据商品ID查询该库存量),只有库存有余量时,秒杀系统才进行库存扣减、下单,可本地缓存保存库存是否为 0 的标识,避免再请求
redis 库存查验操作是典型KV查询,Redis正满足。但秒杀只有小部分用户能成功下单,所以: 商品库存查询操作(读操作)>>库存扣减、下单操作(写操作)。
秒杀阶段
秒杀从过程上来说,总共分为3个阶段:准备阶段、秒杀中、秒杀后
准备阶段
这个阶段也叫作系统预热阶段,此时会提前预热秒杀系统的业务数据
问题
用户不断刷新商品详情页,导致详情页瞬时请求量猛增
解决方案
将商品的详情页的属性进行静态化,然后使用CDN或浏览器缓存这些静态化元素,秒杀前的大量请求可直接由CDN或浏览器缓存服务,不会到达服务端,同时将一些商品的动态数据存储到Redis中进行预热
秒杀中
问题
大量用户点击商品详情页上的秒杀按钮,会产生大量的并发请求查询库存,一旦某个请求查询到有库存,紧接着系统就会进行库存扣减,然后,系统会生成实际订单,并进行后续处理,例如订单支付和物流服务,如果请求查不到库存,就会返回。用户通常会继续点击秒杀按钮,继续查询库存,每个秒杀请求都会查询库存,而请求只有查到有库存余量,后续的库存扣减和订单处理才会被执行
解决方案
该阶段最大并发压力在库存查验,这就需使用Redis保存库存量,请求直接从Redis读库存并查验,当库存查验完成后,一旦库存有余量,立即在Redis扣库存,为避免请求查询到旧库存值,库存查验、库存扣减两个操作需保证原子性,同时注意幂等的处理,防止重复下单
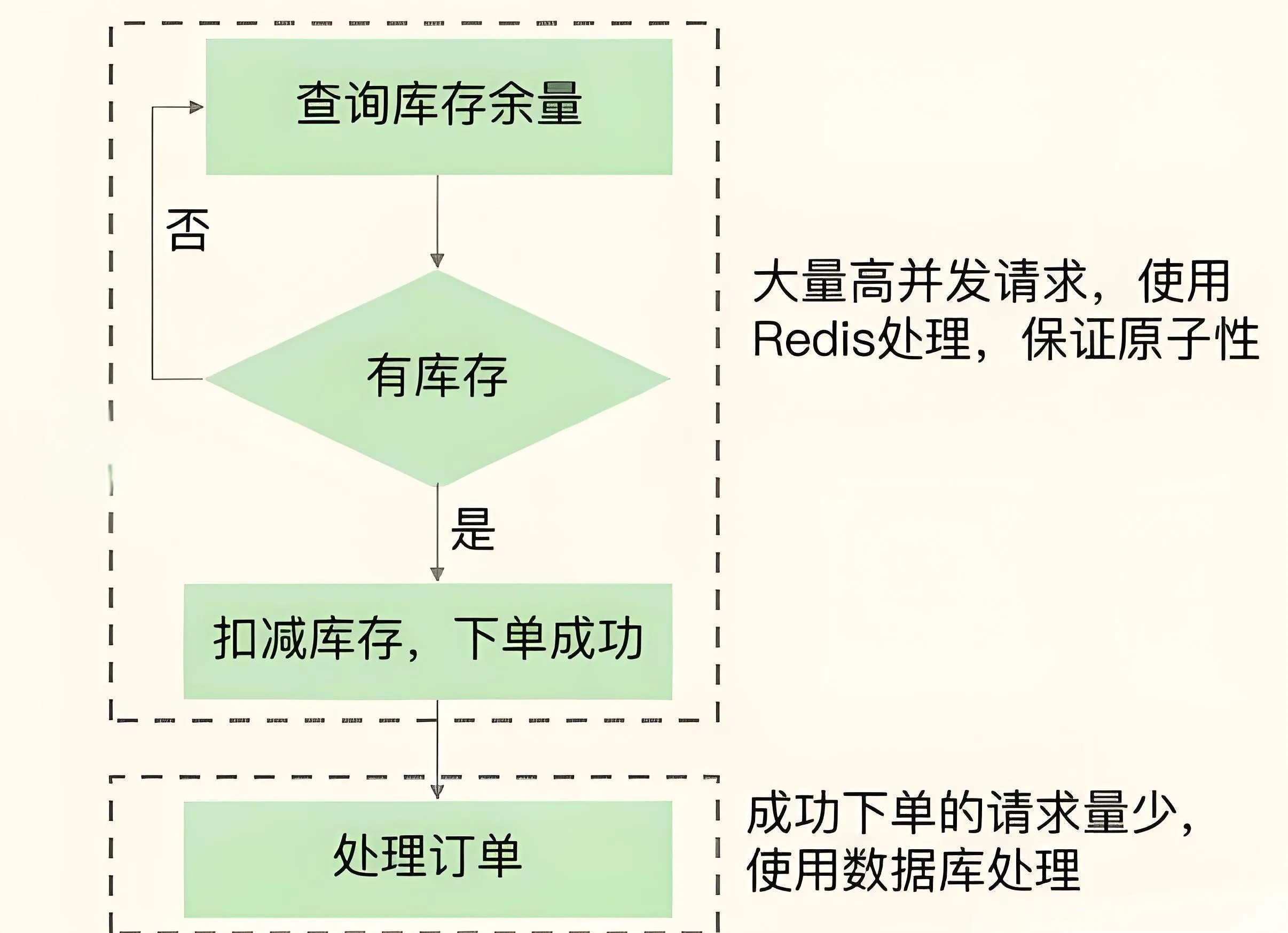
秒杀后
该阶段,可能还有部分用户刷新商品详情页,尝试等待有其他用户退单。而已成功下单的用户会刷新订单详情,跟踪订单进度,不过,此阶段的用户请求量已下降很多,服务器端一般都能支撑。
完成秒杀后的数据处理工作,比如数据的最终一致性问题处理,异常情况处理,商品的回仓处理等。
方案设计
在负载均衡层进行 限流防刷 处理,在应用层进行 异步解耦,Redis处理瞬时高并发请求,最后进行db处理。
架构上的思考
了解了什么是秒杀以后,我们需要来思考需要确定设计哪些功能,同时根据公司的业务体量,要考虑系统需要承受多大的访问量?思考的维度大体如下:
- QPS(Queries Per Second)
即一秒内可以处理的请求数量,假如一个服务的RT(Response time)是20ms,则QPS为50
- 电商系统核心层与预估每一层的并发量
主要分为:负载均衡层、应用层和持久层
负载均衡层使用的是高性能的Nginx,则我们可以预估Nginx最大的并发度为:10W+,这里是以万为单位。
假设应用层我们使用的是Tomcat,而Tomcat的最大并发度可以预估为800左右,这里是以百为单位。
假设持久层的缓存使用的是Redis,数据库使用的是MySQL,MySQL的最大并发度可以预估为1000左右,以千为单位。Redis的单机最大并发度可以预估为5-10W左右,以万为单位。
- 方案
系统扩容: 系统扩容包括垂直扩容和水平扩容,增加设备和机器配置,绝大多数的场景有效。
缓存: 本地缓存或者集中式缓存,减少网络IO,基于内存读取数据。大部分场景有效。
读写分离: 采用读写分离,分而治之,增加机器的并行处理能力。
QPS的考虑
对于系统中需要达到支撑一定量级的QPS的考虑与实际压测,需要结合公司实际业务,如果你所在公司的企业是某一领域的独角兽,人均日活好几万,那对应设计的系统QPS要至少在一天峰值的2 - 5倍,如果日活量很少,那一般设计的功能足以支撑
资源的控制
- 使用 OpenResty 的使用Lua脚本库由负载均衡层直接访问缓存进行限流,避免了调用应用层的性能损耗。
- 使用动态渲染技术,CDN技术来加速网站的访问性能。
- 可以将用户的请求放入队列中进行处理,并为用户弹出排队页面。
微服务的划分
对同类业务的逻辑处理放在一个服务中
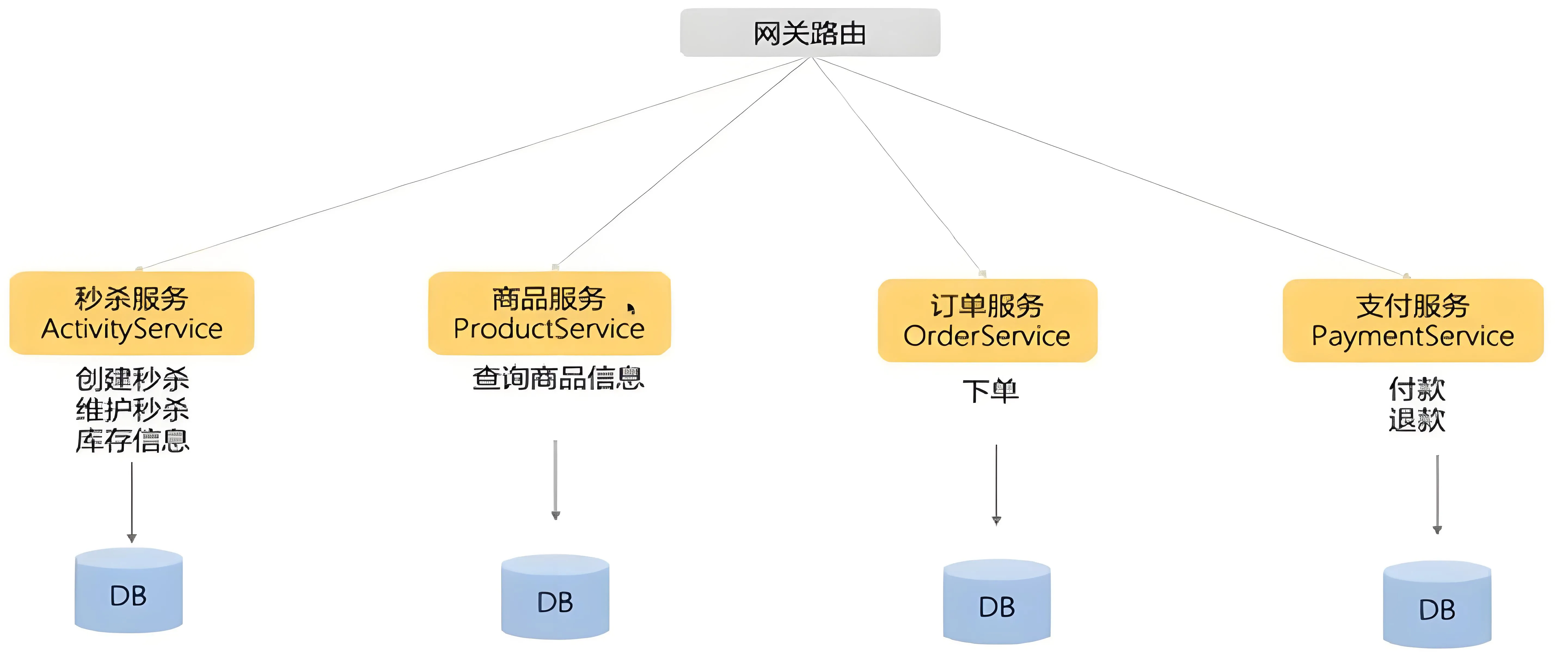
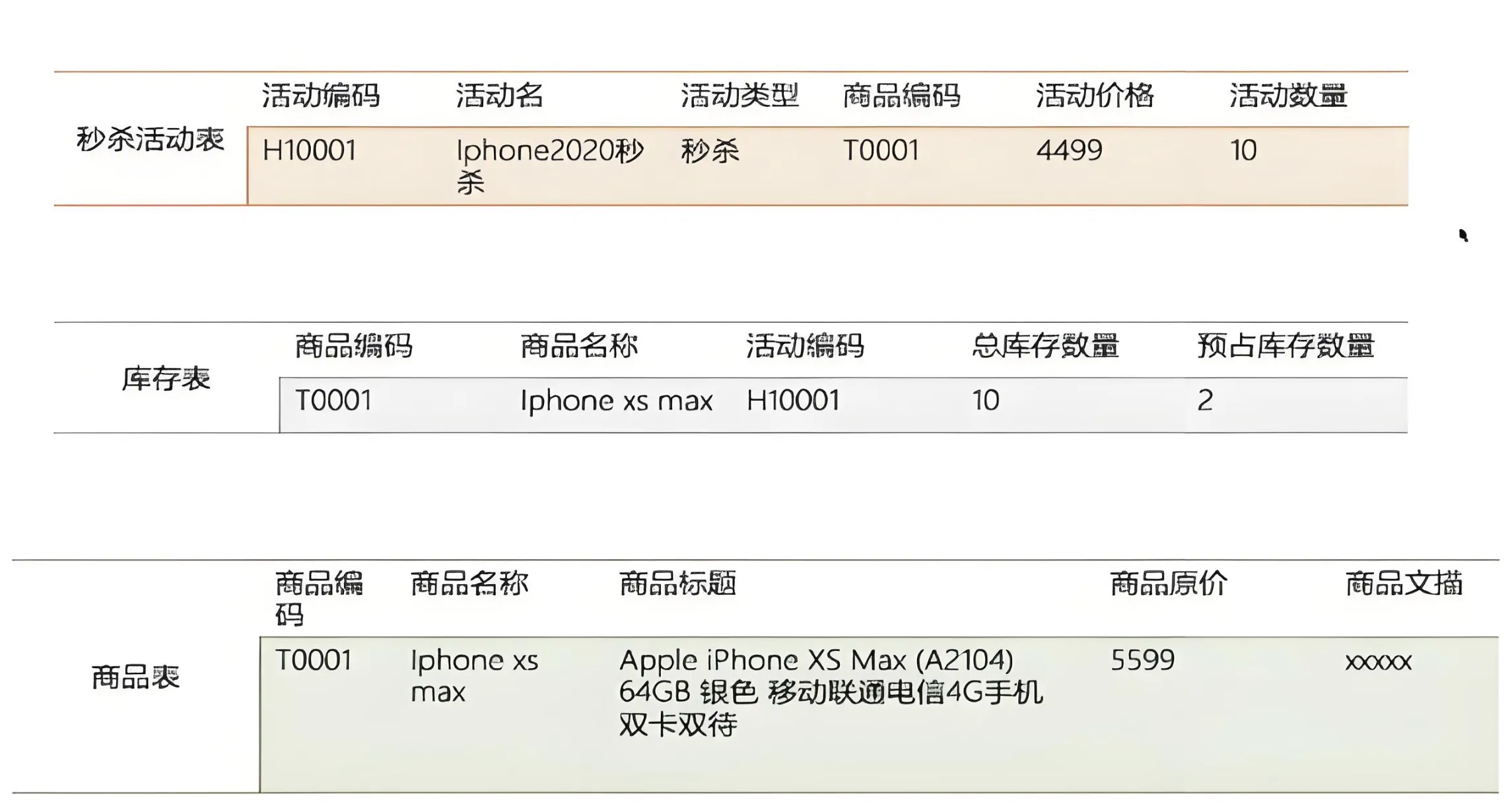
数据库的设计
选择合适的存储结构,然后细化
超卖问题的解决
- 通过redis lua脚本和消息队列可以有效控制超卖
- 通过设置数据库表的库存字段为无符号进行兜底
并发与性能的平衡
网上很多的秒杀系统和对秒杀系统的解决方案,并不是真正的秒杀系统,他们采用的只是同步处理请求的方案,一旦并发量真的上来了,他们所谓的秒杀系统的性能会急剧下降。接下来进行同步与异步两种秒杀方式的对比
同步秒杀
当用户发起秒杀请求时,由于系统每个业务流程都是串行执行的,整体上系统的性能不会太高
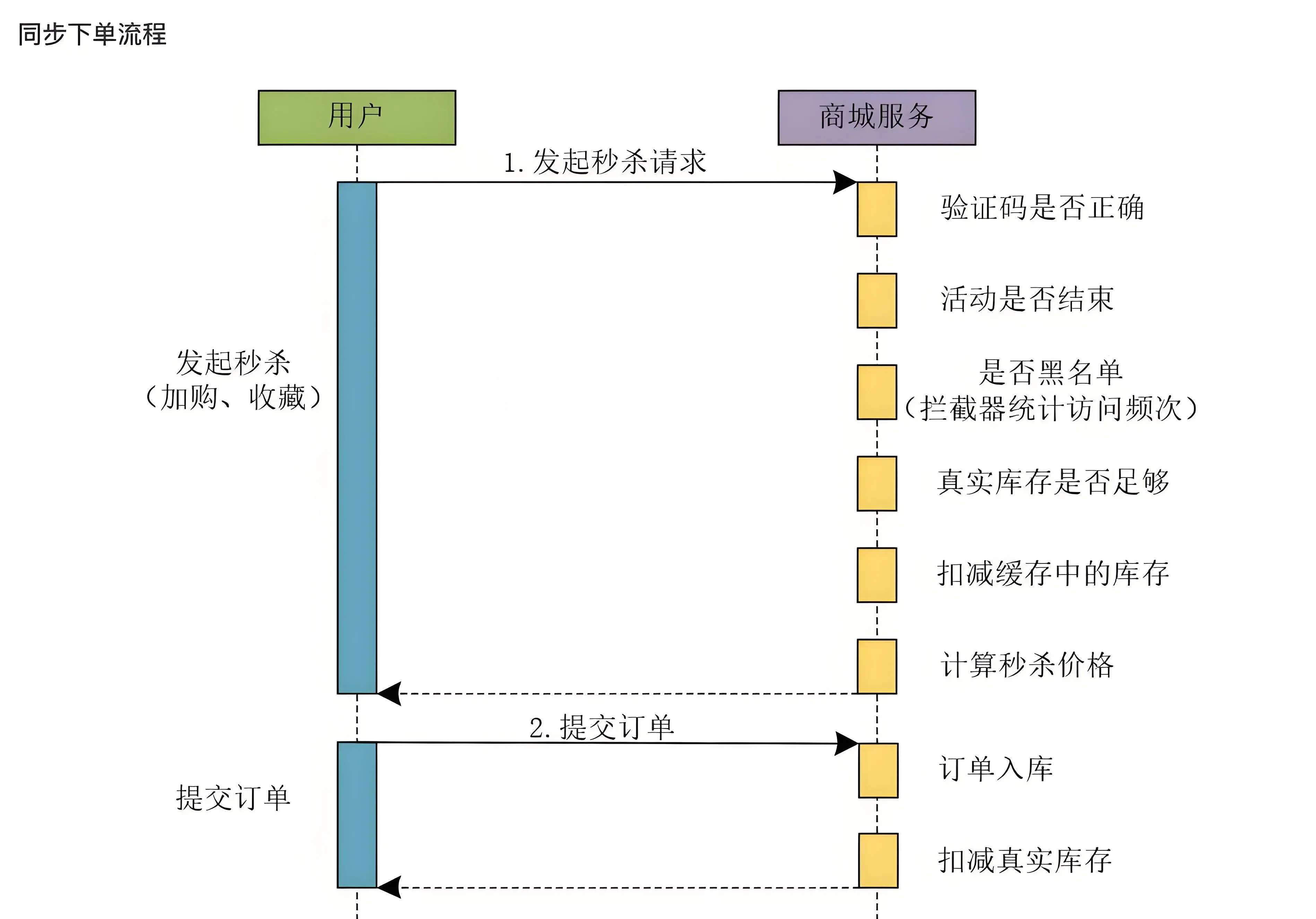
使用同步下单方式确实可以做秒杀系统,但是同步下单的性能不会太高。
很多所谓的秒杀系统,存在着秒杀的业务,但是称不上真正的秒杀系统,原因就在于他们使用的是同步的下单流程,限制了系统的并发流量。之所以上线后没出现太大的问题,是因为系统的并发量没达到一定的量级,不足以压死整个系统。
异步秒杀
接下来看下异步的执行流程
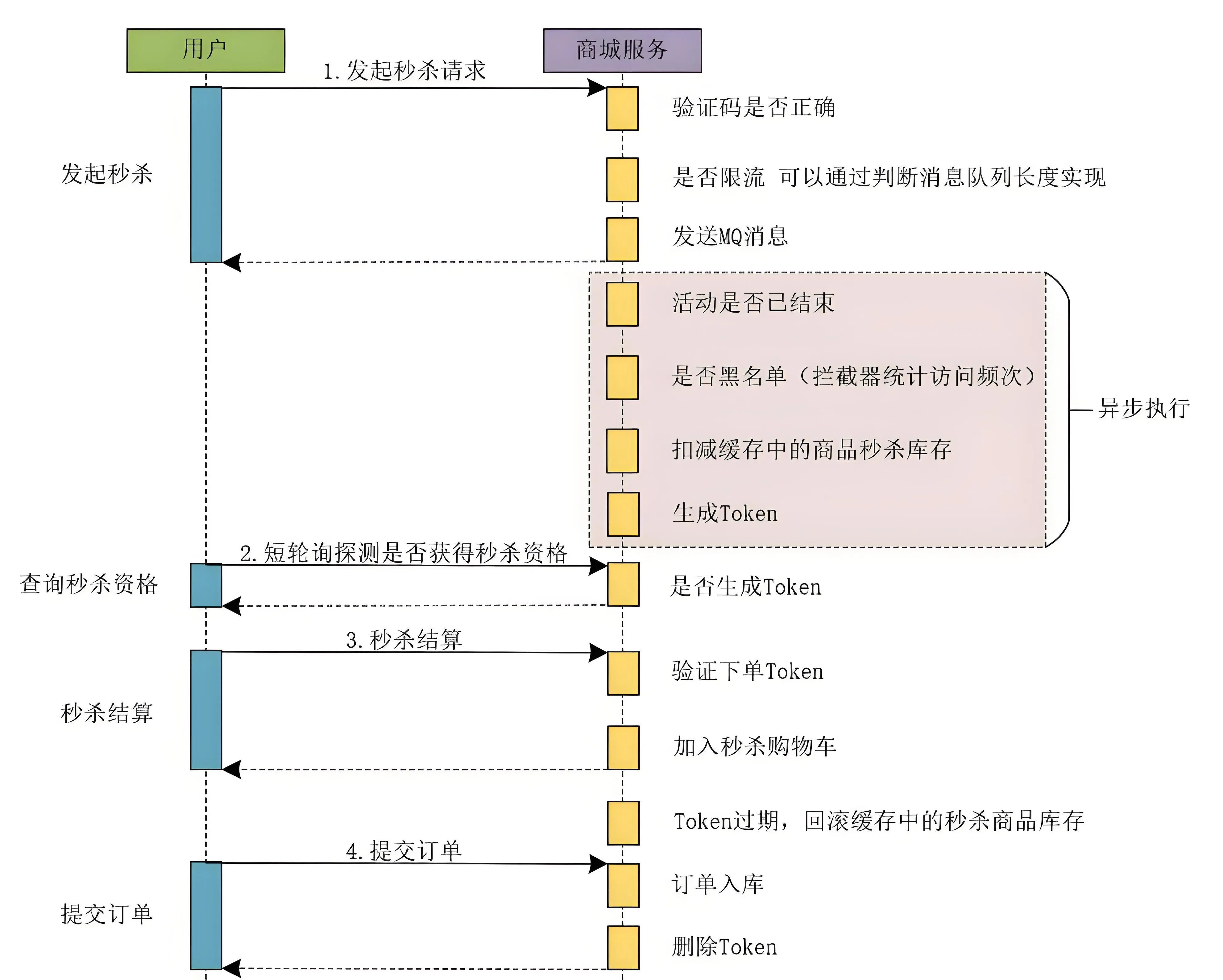
发起秒杀
- 在秒杀的过程中,通过在负载层进行限流,比如秒杀100件商品,那么保留前100个请求
- 验证token,进入订单页提供的,防止重复下单的token。
- 将限流后的请求发到mq处理
我们 在用户发起秒杀请求阶段对用户的请求进行了限流操作 ,可以说,系统的限流操作是非常前置的。在用户发起秒杀请求时进行了限流,系统的高峰流量已经被平滑解决了,再往后走,其实系统的并发量和系统流量并不是非常高了。
所以,网上很多的文章和帖子中在介绍秒杀系统时,说是在下单时使用异步削峰来进行一些限流操作,那都是在扯淡! 因为下单操作在整个秒杀系统的流程中属于比较靠后的操作了,限流操作一定要前置处理,在秒杀业务后面的流程中做限流操作是没啥卵用的。
异步处理
通过mq异步处理,达到削峰填谷的作用,异步处理如下
- 判断活动是否已经结束
- 判断本次请求是否处于系统黑名单,为了防止脚本与电商领域同行的恶意竞争可以为系统增加黑名单机制,将恶意的请求放入系统的黑名单中。可以使用拦截器统计访问频次来实现。
- 扣减缓存中的秒杀商品的库存数量。
- 生成秒杀的Token令牌,这个Token是绑定当前用户和当前秒杀活动的,只有生成了秒杀Token的请求才有资格进行秒杀活动(此token也有防重复的作用)。
秒杀的Token令牌
此处秒杀的Token令牌由Redis存储,采用 string 结构,其中Key的规则可以定义为 seckill:商品ID:用户ID,Value值则为生成的Token令牌
短轮询查询秒杀结果
采取客户端短轮询查询是否获得秒杀资格的方案。
客户端可以每隔3秒钟轮询请求服务器,查询是否获得秒杀资格,这里,我们在服务器的处理就是判断当前用户是否存在秒杀Token,如果服务器为当前用户生成了秒杀Token,则当前用户获取到秒杀资格。否则继续轮询查询,直到超时或者服务器返回商品已售完或者无秒杀资格等信息为止。
采用短轮询查询秒杀结果时,在页面上我们同样可以提示用户排队处理中,但是此时客户端会每隔几秒轮询服务器查询秒杀资格的状态,相比于同步下单流程来说,无需长时间占用请求连接。
轮询的过程中,只需要同时校验 查询Redis库存剩余数量 与 秒杀的Token令牌 即可,如果库存为0,且没有对应用户的秒杀的Token令牌,即为没有获取到秒杀资格。
采用短轮询查询的方式,会不会存在直到超时也查询不到是否具有秒杀资格的状态呢?
有可能,不过从真实的业务角度出发,商家参加秒杀活动本质上不是为了赚钱,而是提升商品的销量和商家的知名度,吸引更多的用户来买自己的商品。所以,我们不必保证用户能够100%的查询到是否具有秒杀资格的状态。
秒杀结算
当获取到秒杀的Token令牌后,跳转到结算页面,即可进行下单与支付操作了
- 验证下单Token
客户端提交秒杀结算时,会将秒杀Token一同提交到服务器,商城服务会验证当前的秒杀Token是否有效。
- 加入秒杀购物车
商城服务在验证秒杀Token合法并有效后,会将用户秒杀的商品添加到秒杀购物车。
- 提交订单
订单入库,将用户提交的订单信息保存到数据库中。 删除Token,秒杀商品订单入库成功后,删除秒杀Token。
具体实现
在Redis中设计一个Hash数据结构,来支持商品库存的扣减操作
luaseckill:goodsStock:${goodsId}{
totalCount:200,
initStatus:0,
seckillCount:0
}
- totalCount
表示参与秒杀的商品的总数量,在秒杀活动配置时将此值加载到Redis缓存中。
- initStatus
我们把这个值设计成一个布尔值。秒杀开始前,这个值为0,表示秒杀未开始。可以通过定时任务或者后台操作,将此值修改为1,则表示秒杀开始。
- seckillCount
表示秒杀的商品数量,在秒杀过程中,此值的上限为totalCount,当此值达到totalCount时,表示商品已经秒杀完毕。
库存扣减
使用Lua脚本将Redis中 库存查验、库存扣减 的操作封装成一个原子操作,这样就能够保证操作的原子性,从而解决高并发环境下的同步问题。
lualocal resultFlag = "0"
local n = tonumber(ARGV[1])
local key = KEYS[1]
local goodsInfo = redis.call("HMGET",key,"totalCount","seckillCount")
local total = tonumber(goodsInfo[1])
local alloc = tonumber(goodsInfo[2])
if not total then
return resultFlag
end
# 如果当前请求的库存量加上已被秒杀的库存量仍然小于总库存量,就可以更新库存
if total >= alloc + n then
local ret = redis.call("HINCRBY",key,"seckillCount",n)
return tostring(ret)
end
return resultFlag
- resultFlag
结果标记,0表示扣减失败,1表示扣减成功
- n
当前要扣减的数量,由客户端动态传入
- key
要扣减的库存结构 Key,需要查询与更新已秒杀的库存数量
- goodsInfo
商品的库存信息
每次扣减都从库存的结构中查询,然后通过对比秒杀的商品总数量与已秒杀数量,对已秒杀的库存数量进行更新,更新成功返回 1。
在Java代码中实现对lua脚本的调用
javapublic int secKill(String id, int number) {
String key = getCacheKey(id);
Object seckillCount = redisTemplate.execute(script, Arrays.asList(key), String.valueOf(number));
return Integer.valueOf(seckillCount.toString());
}
保障高可用
- 秒杀页面上能静态化处理的页面元素,要尽量静态化,充分利用CDN或浏览器缓存服务秒杀开始前的请求
- 对恶意请求进行拦截,避免对系统的恶意攻击,例如使用黑名单禁止恶意IP进行访问。
- 如果Redis实例的访问压力过大,为了避免实例崩溃,我们也需要在接入层进行限流,控制进入秒杀系统的请求数量。
- Redis中保存的库存信息其实是数据库的缓存,为了避免缓存击穿问题,不要给库存信息设置过期时间。
- 数据库订单异常处理。如果数据库没能成功处理订单,可以增加订单重试功能,保证订单最终能被成功处理。
- 秒杀活动带来的请求流量巨大,我们需要把秒杀商品的库存信息用单独的实例保存,而不要和日常业务系统的数据保存在同一个实例上,这样可以避免干扰业务系统的正常运行。
存在的问题与解决方案
多个同时秒杀的商品如何处理?
在Redis集群中,Redis Cluster通过将键空间划分为16384个哈希槽(hash slots),并将这些槽分配给各个节点,来实现分布式的存储和查询,如果对应的秒杀商品的库存信息都命中到一个实例,导致产生倾斜要如何处理?
这其实是典型的 数据倾斜问题,属于 数据量倾斜。若有多个秒杀商品,可以利用Redis Cluster的哈希槽(hash slots)机制, ,用不同实例保存不同商品的库存,避免使用单实例导致所有秒杀请求都集中在一个实例。
理解Redis Cluster的哈希槽
每个key在存储时,都会根据它的CRC16算法计算出的值映射到一个具体的哈希槽上。Redis集群中的每个节点负责维护一部分哈希槽。
虽然通常来说,哈希槽的分配是由Redis集群自动完成的,但在某些特定场景下,可能希望手动分配或重新分配哈希槽到不同的节点。
如何支撑过百万的并发量?
在秒杀系统中我们使用Redis实现缓存,假设Redis的读写并发量在5万左右。我们的商城秒杀业务需要支持的并发量在100万左右。如果这100万的并发全部打入Redis中,Redis很可能就会挂掉,那么,我们如何解决这个问题呢?
其实此类问题也属于 数据倾斜问题,只不过是上一个问题是 数据量倾斜 ,将不同的秒杀商品存放到不同的实例,而当前问题是 数据访问倾斜,需要将同一个秒杀商品的库存拆分到不同的实例上。
采用算法中的分治思想,通过 HashTag 将商品库存分开存储在不同实例,同样采用 库存分桶策略(10桶*100库存),如果秒杀数量是200,实例有3个,可以拆成3份库存(3份累计数量是200),同样采用哈希槽机制,通过tag来命中不同的实例上,key的定义分别为:seckill:goodsStock:商品ID{1},seckill:goodsStock:商品ID{2},seckill:goodsStock:商品ID{3},根据用户ID取模(也可能会倾斜)或绑定一个原子性的序号取模,可将请求命中到不同实例的库存结构上,这样当请求并发访问时,根据取模命中到不同的实例,减少了单个实例的压力
什么是 HashTag
HashTag 是使用redis的一个小技巧,使用方式是在key中添加一对花括号 {},这个 {} 可以将key的一部分内容包裹起来,而redis server会对于加上{}的key进行识别,并进行分区的控制。
具体来说:正常情况下,客户端根据key的完整内容,按照CRC16算法生成一个CRC16值,redis-server按照这个CRC16值,给这个key分配slot,而使用HashTag后,客户端计算key的CRC16值,不在是整个key的内容,而是{}括起来的那部分内容。使用HashTag,可以让我们根据业务属性,在key的适当位置添加{},让业务相关的一些key存储到同一个slot中,同时也就分配到同一个实例上,当相关的数据全部分配到同一个实例上后,就可以 执行实例内事务操作(目前redis集群不支持跨实例事务操作) 和范围查询等相关操作了。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!