
目录
在互联网应用的演进过程中,支撑百万级并发(QPS)是许多大型系统必须跨越的一道门槛。这不仅仅是硬件堆叠的问题,更是一场关于架构设计、资源调度、数据一致性和异步处理的艺术。本文将结合微服务拆分、连接池、RPC、线程模型、缓存、消息队列及数据库优化等多个维度,深入探讨其执行原理、解决的瓶颈以及潜在的缺点。
今天我将自己所掌握的支撑高并发体系的知识内容进行总结,从微服务拆分到分库分表,各个层面都有考虑,但深层需求可能不只是罗列技术,而是如何将这些技术整合,并在设计时的权衡和取舍,形成完整的架构思路。
本文不涉及硬件的调整,毕竟想要提升并发能力,最简单的无非就是一台机器不够那就十台,只要老板同意,沙漠都能种出水果。
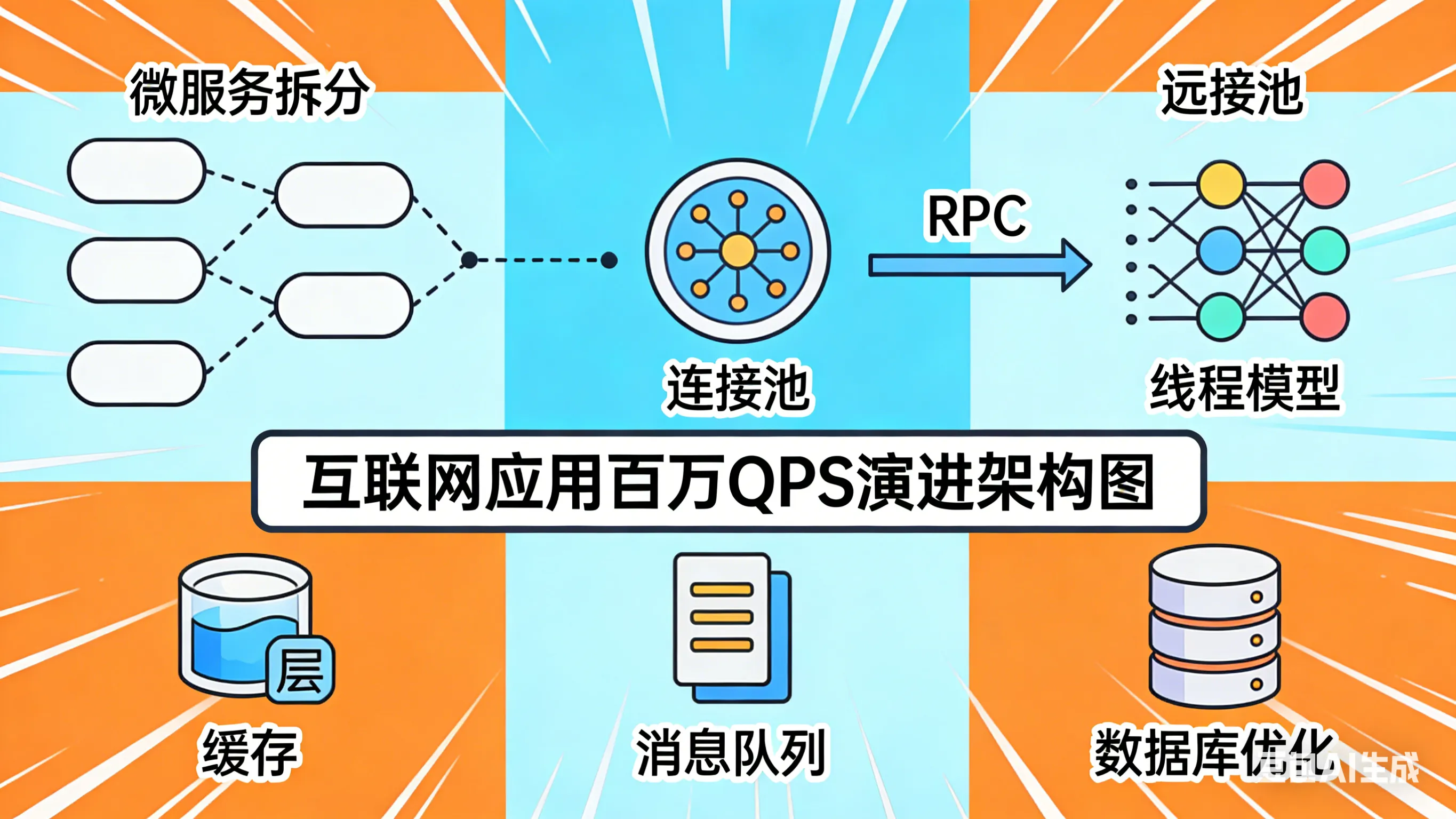
微服务分布式的拆分
将单体应用拆分为多个独立的、围绕业务能力构建的小型服务(微服务),每个服务独立部署、扩展和维护,结合服务注册与发现(如Nacos, Eureka)机制实现动态寻址。
当我们的服务存在单点故障与性能瓶颈时,微服务,分布式集群部署应然而生。根据业务的垂直领域拆分后,其隔离性与可用性增强,同时针对一些特定高负载模块可以进行独立扩容,扩展性非非常强。
在高并发的场景下,其一台机器的资源是有限的,大多数情况下,我们采用 Tomcat 作为 Web 容器,其中内部配置的 Executor 和 Connector 共同构成了连接处理模型。通过配置 maxThreads(最大工作线程数)、acceptCount(等待队列长度)等参数,形成一个线程池来处理 HTTP 请求,当微服务拆分以后,每个服务都对应一个 Web 容器处理请求,并发度立马提升上来了,如果还存在瓶颈,那么单个微服务的分布式集群部署,也是可以提升并发量的手段。
Tomcat 容器的优化
现在主流的还是微服务架构,想要提升最大的并发处理能力,那么 Tomcat Web 容器的优化也是必不可少的。例如 maxThreads(最大工作线程数)、acceptCount(等待队列长度)等参数的配置。
像传统的 Tomcat 线程池(BIO)在处理IO操作(如数据库查询、RPC调用)时,线程会被阻塞挂起,导致线程利用率不高。尽可能的使用 Tomcat 8 及以后得版本,其默认的 I/O 模型改为了 NIO,这是一个非常重要的架构升级,主要是为了解决高并发场景下的性能和扩展性问题。
缺点:
虽然拆分了微服务,但是同样也带了各种问题,例如:
- 运维复杂度剧增:需要管理成百上千个服务的部署、监控和日志收集。
- 网络通信开销:服务间调用引入网络延迟,且需处理网络分区、超时、重试等分布式固有问题。
- 分布式事务难题:数据一致性从单机事务变为跨服务的分布式事务,实现难度大。
RPC 框架的选择
RPC(远程过程调用)框架屏蔽了底层网络通信细节,让服务调用像本地方法调用一样简单。常见的有基于 HTTP 的Feign/OpenFeign,基于 TCP 的 Dubbo/gRPC/Thrift。
解决的瓶颈:
从通信效率而言,相比 HTTP,在建立 TCP 连接后,存在 队头阻塞 的性能瓶颈,同时传输协议采用 JSON 格式,定义的请求头与请求体内容体积大,占用带宽的传输。
而基于 TCP 的 RPC 框架,通常采用自定义传输层协议(例如 Dubbo)又或者采用成熟的 HTTP/2.0 协议,其无限并发流解决了传统 HTTP 1.1 的性能瓶颈问题,同时采用二进制序列化(如Protobuf, Hessian),传输体积更小,解析更快。
线程池
Java 中通过 ThreadPoolExecutor 自定义线程池,核心参数包括核心线程数、最大线程数、队列、拒绝策略等,将大幅度利率 CPU 资源,用于异步处理耗时任务(如发短信、写日志),提升了并发性能。
解决的瓶颈:
- 资源控制:防止无限制创建线程导致系统崩溃。
- 异步解耦:将非核心业务(如通知、统计)异步化,缩短主链路响应时间。
缺点:
- 配置复杂且易出错:不同业务场景(CPU密集型 vs IO密集型)需不同配置,配置不当会导致死锁、线程饥饿或OOM。
- 线程泄漏风险:如果任务中发生死循环或阻塞未处理,可能导致线程池耗尽。
提示
线程池是我们编码中最常用的并发提升手段了,就不过多陈述。
JDK21 的虚拟线程
JDK21 引入的 虚拟线程(Virtual Threads),这是划时代的变化,让我们系统天然的支撑高并发与高吞吐。本质就是轻量级线程,从底层的操作系统调用,变为了由 JVM 调度。一个操作系统层面的平台线程,管理着多个虚拟线程,类似于一致性哈希算法中的虚拟节点,与物理节点存在映射关系。它允许创建数百万个虚拟线程而不会耗尽内存。通过 Executors.newVirtualThreadPerTaskExecutor() 创建。
解决的瓶颈:
虚拟线程的出现,解决了我们传统线程池中,RPC 调用与 IO 调用时产生的线程阻塞,CPU资源浪费的情况。同时传统平台线程(Platform Threads)受限于OS线程数,创建百万级线程不现实。而虚拟线程解决了此类问题,一个虚拟线程只占用4KB,同时当虚拟线程遇到 IO 阻塞时,JVM 会自动将其从载体线程(Carrier Thread)上卸下,调度其他虚拟线程运行,极大提升了吞吐量。
一句话,虚拟线程是将 CPU 资源利用到了极致,比我更像纯牛马。

虽然虚拟线程强大,但是也存在一些 缺点:
- JDK版本限制:需要JDK21+。
- 并非万能:对于CPU密集型任务,虚拟线程优势不明显,甚至可能因频繁调度带来额外开销。仍需合理使用结构化并发(Structured Concurrency)管理生命周期。
一级缓存,二级缓存
缓存也是我们提升并发性能最常用的手段:
- 一级缓存:本地缓存(如Caffeine, Guava Cache),存储在应用JVM内存中,访问速度极快,无网络开销。
- 二级缓存:分布式缓存(如Redis, Memcached),存储在独立服务中,数据共享,容量大。
我发现微服务架构中,使用最频繁的还是分布式缓存,对于本地缓存反而使用的并不太多,我个人觉得造成这种情况的原因可能是因为大多数的系统的 QPS 并不太高,分布式缓存足以支撑,同时本地缓存还需要保证一致性问题,比如通过 MQ 广播机制进行缓存更新,增加了系统复杂度,或许会让人望而生怯吧。
解决的瓶颈:
对于高并发性能的角度来考虑,通过缓存热点数据,减少对数据库的直接访问,降低数据库负载。同时使用本地缓存极大降低了读取延迟,将机器资源也算是利用到家了。
也存在了一些 缺点:
- 数据一致性问题:缓存与数据库、不同实例间的本地缓存可能存在不一致。
- 缓存穿透/雪崩/击穿:需额外设计(布隆过滤器、互斥锁、随机过期时间)来防范。
本地缓存对系统内存占用的问题
我探索过一些方案,有些人觉得本地缓存占用 JVM 堆内存,可能会导致 GC 压力增大。
我个人觉得缓存本身解决热点数据问题,对于高频读,低频写的热点数据而言,从数据量上来看,大多数也不会占用太多的空间,与分布式缓存从性能成本上考虑,还是很有必要的,如果真的要缓存几百M的热点数据,那么就需要额外的一些考虑。
Redis 分桶
其实 Redis 分桶,是将一个大 Key 的数据拆分成多个子Key(桶)存储。例如,一个包含百万个元素的集合,可以按Hash 取模拆分成 100 个Key,每个 Key 存储约1万个元素。
为什么要分桶呢,这还得从 Redis cluster 说起,其集群原理是通过哈希槽实现的,每个集群下的主节点负责一部分哈希槽的节点,当key通过 CRC16 算法计算出哈希槽节点,会到对应的节点上进行数据的读写,那么问题来了,如果某个 key 需要支撑百万并发呢,那么所处在哈希槽节点的机器,不就存在性能瓶颈了么?接下来我们瞅瞅 Redis 分桶还解决了哪些问题。
解决的瓶颈:
- 解决热点Key问题:分散单个 Key 的访问压力,更好利用 Redis 集群的多个节点解决读写瓶颈。
- 大 Key 阻塞:Redis是单线程处理命令,操作大Key(如 hget 百万级 Hash)会导致 Redis 阻塞,引发超时。
- 网络传输慢:大 Key 的网络传输耗时长,占用带宽。
缺点:
- 编程复杂度:读写数据时需要遍历所有桶,逻辑变复杂。
- 原子性挑战:跨桶的操作难以保证原子性(除非使用Lua脚本)。
数据一致性可采用 Lua 脚本,保障原子性
Redis 支持使用 Lua 脚本执行多条命令。Lua 脚本在 Redis 服务端以原子性方式执行,期间不会被其他命令插入,同时减少了网络开销,将多个操作合并为一次网络请求。
Lua 脚本也是存在一定的阻塞风险:如果Lua脚本执行时间过长,会阻塞 Redis 主线程,影响其他请求。需严格控制脚本逻辑的简洁性。
MQ 异步削峰填谷
引入消息队列(如Kafka, RocketMQ, RabbitMQ)作为生产者和消费者之间的缓冲层。生产者将请求/事件发送到 MQ后立即返回,消费者按自身处理能力从 MQ 拉取消息处理,是解决写入瓶颈的最佳手段。
- 系统解耦:上下游系统不直接依赖,一方故障不影响另一方。
- 流量削峰:在流量洪峰(如秒杀)时,MQ作为“蓄水池”,暂存超出系统处理能力的请求,防止系统被瞬间打垮。
- 异步处理:非核心链路(如发红包、更新统计)异步化,提升主链路响应速度。
缺点:
- 提高了系统复杂性:引入 MQ 增加了系统组件,MQ 本身故障会影响整个系统。
- 数据一致性延迟:引入了最终一致性,无法立即看到操作结果。
- 消费问题:需保证消费者业务的幂等性、解决消息顺序、消息堆积等问题。
读写分离与分库分表
利用数据库主从复制机制,主库负责写入,一个或多个从库负责读取,解决了读性能的瓶颈问题。
解决的瓶颈:
- 读写互相影响:复杂的查询(报表、列表)会消耗大量数据库资源,影响写入性能。读写分离将读压力分流到从库。
- 读扩展性:通过增加从库数量,可以线性提升系统的读吞吐量。
主从延迟
读写分离架构下最大的问题就是主从延迟,数据从主库同步到从库有延迟(毫秒级),导致刚写入的数据可能在从库读不到(最终一致性),这是无法避免的。从库越多,延迟越大,主库需向所有从库发送 binlog,从库数量增加会加重主库IO负担。
对于一致性要求较高的数据,解决方案就是可以 强制路由读主库。
当单库单表数据量过大(如超过千万行)或写入 TPS 超过单机极限时,通过中间件(如ShardingSphere, MyCat)按照分片键(如用户ID、订单ID)将数据水平拆分到多个数据库或表中,这样写入时,就从不同库的连接池资源进行处理,解决了写入瓶颈的问题。
- 单机存储与性能瓶颈:突破单机磁盘、内存、CPU的限制,实现数据库的水平扩展。
- SQL性能下降:大表的查询、更新、索引维护成本极高。分表后数据量级降低,SQL执行效率提升。
缺点:
- 架构复杂度剧增:引入了分布式数据库的复杂性。
- 分布式事务难题:跨库事务无法使用本地事务,需引入Seata等分布式事务框架,或采用最终一致性方案。
- 跨库JOIN与聚合:原本简单的JOIN查询和COUNT/SUM聚合变得非常困难,通常需要通过应用层聚合或借助ES等外部系统解决。
- 扩容成本:重新分片(Resharding)数据迁移过程复杂且风险高。
- 深度分页:多个表数据的需要合并到一起进行分页,深度分页问题没有完美的解决方式。
注意
分库分表的引入,与分布式的引入一样,存在着很多问题,我们应该先从数据库层面、索引层面、SQL层面进行优化,在非无法避免的情况下,最好不要引入分库分表,复杂性真的是太高了。
总结
支撑百万级并发是一个系统工程,没有银弹,如何突出自己的价值给公司节省多少资源就在此时此刻。
上述每个维度都是解决特定瓶颈的利器,但也带来了相应的复杂性和新的挑战。在实际架构设计中,我们需要根据业务场景的特点(读多写少?强一致性要求?数据量级?),权衡利弊,组合使用这些技术手段,构建一个高可用、高性能、可扩展的分布式系统。
同时,完善的监控、告警和预案机制也是保障系统稳定运行不可或缺的一环。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!