
目录
我们思考这样一个问题,在互联网应用中,如果一张数据库的表中有1千万的数据量,某次需求调整,需要修改字段类型或者修改字段长度,或者 int 类型达到上限,你会怎么做?直接使用 ALTER TABLE 吗?

ALTER TABLE 问题分析
首先我们来分析一下,这个问题的本质就是对 mysql DDL 操作,虽然 MySQL 8.0.12 版本引入 Instant DDL(Instant Data Definition Language)允许在不阻塞读写(Online)的情况下,以毫秒级的速度修改表结构,当时在某些时候,还是会退回到最保守的 COPY 算法,例如:
- 修改数据类型
- 修改长度 (跨临界点,例如 varchar(255) 改成varchar(256))
- 修改字符集
COPY 算法
COPY 算法就是“复制数据”的过程。
当你要修改表结构时,MySQL 会生成一个临时表,把原表的数据一行行读出来,经过处理后再写入临时表,最后用临时表替换原表。
在使用 COPY 算法时,MySQL 在数据复制阶段,会给原表加上排他锁(Exclusive Metadata Lock)。这意味着在 DDL 执行期间,任何对原表的 INSERT、UPDATE、DELETE 操作都会被阻塞,直到 DDL 完成。
通过上面的分析,我们可以发现对于千万级的大表,直接使用 ALTER TABLE 会导致锁表,这个过程可能持续很长一段时间,这期间业务写入会堆积,连接池耗尽,最终导致整个服务不可用。
结合具体的场景来分析,如果是面向企业级的 TOB 系统,晚上系统是处于无人操作下,直接使用 ALTER TABLE 也不能说错。但是对于互联网的 TOC 应用是随时能访问的,对于高可用非常关注,所以我们需要另外的方案,这也是接下来我们的主题,数据迁移。
数据迁移
数据迁移是指把一批数据从一个数据库表迁移到另一个数据库表中。数据迁移的使用场景无非就是以下几种:
- 对某张表进行分库分表
- 数据库表中导致锁表的 DDL 操作
- 历史数据归档
- 需求调整产生的技术架构改变
当然数据迁移的前提是要以 迁移的数据体量 做考量的,不同的业务场景与不同的数据量,迁移的方案肯定是不一样的。如果只是几十万,都不需要搞那么复杂,直接导入导出 或者 写代码同步过来再做一下数据核对都能搞得定。
接下来我就以千万级数据量的大表为例,讲解下在业务无感知的情况下进如何行 平滑迁移。
迁移的数据类型
对于数据迁移的场景来说,主要包含两种数据的迁移类型,一个是开始迁移时的已存在数据的数据快照,也就是 存量数据,一个是程序运行时产生的新的数据,这部分数据就是 增量数据。
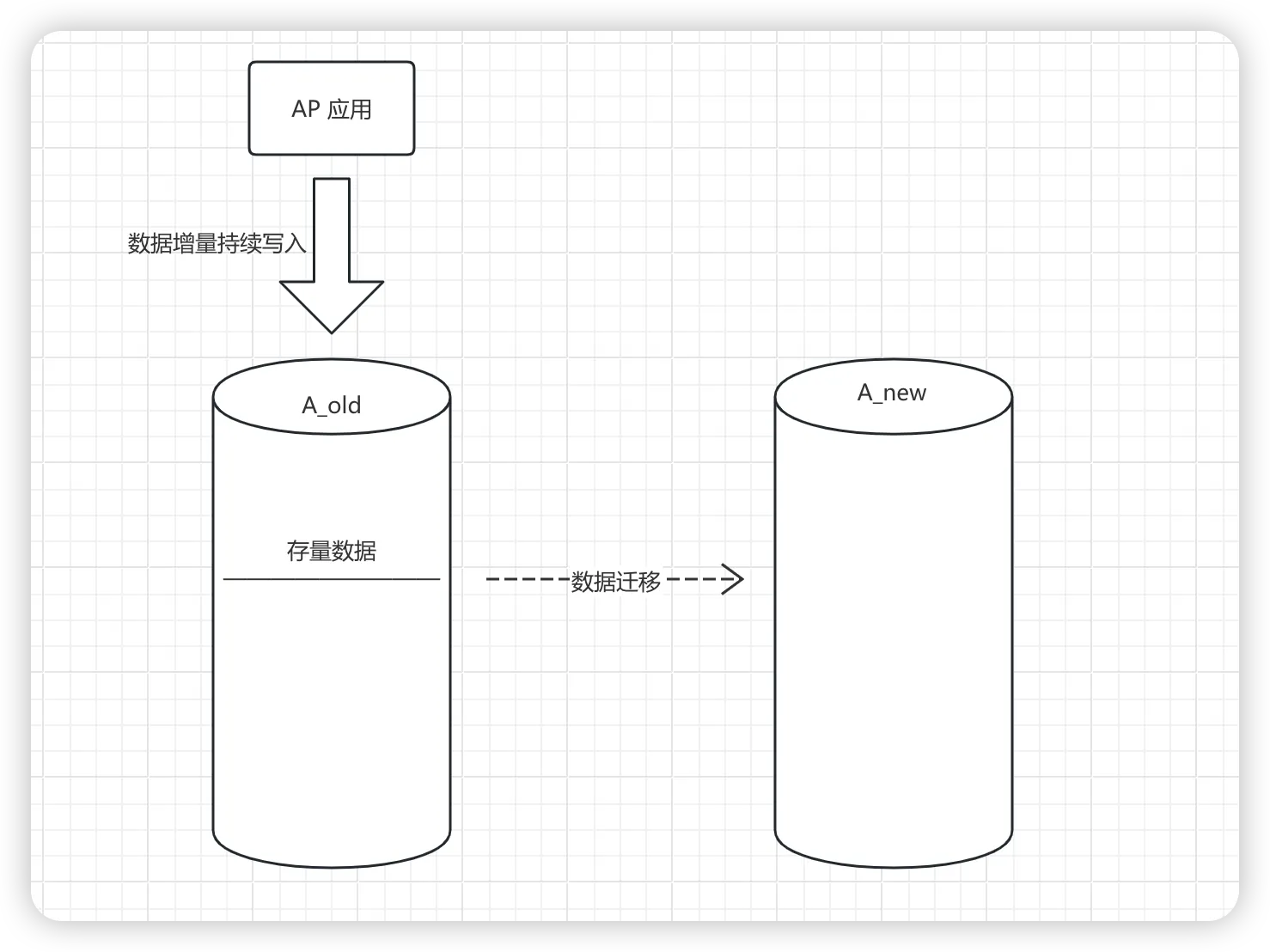
也就是我们在正式的数据迁移开始之前,需要定义个节点,作为存量数据的一致性数据快照,而在这个节点以后产生的 insert 数据,都是增量数据。在此处需要考虑一点,如果是 update 和 delete 操作的数据,不一定是存量也不一定是增量,要看他 insert 的时候是增量还是存量。
如何保障数据完整性的思考
在做数据迁移的时候,需要思考如何保障数据的完整性与一致性,怎么做到在不停机的情况下,将数据完整的迁移完成,例如上面描述的 update 和 delete 场景,都是需要去解决的问题。
其实最核心的解决处理就是在数据的读写上,那么我们就从 读 和 写 两步操作分析,首先是 写 处理:
- 数据实时性:在开始平滑迁移后,需要保证旧系统和新系统数据的实时同步,直至完全切换到新系统。
- insert 数据验证:在双写的同时,需要有验证机制,例如定时查询每天的数据增量进行对比
- update/delete 数据验证:需要区别是增量数据还是存量数据的操作,进行单写或者双写。
- 存量数据的完整性:存量数据在迁移的过程中需要确保所有数据都能准确的迁移到新表中,不能丢失数据。
- 存量数据数据验证:存量数据迁移完成后,也是需要对存量数据进行验证。
接下来我们来分析下 读 操作的处理:
- 全量验证:当写操作全部完成以后,我们再一次进行全量的验证,防止存量数据先读取在写入时,在并发下读取数据后数据产生了变更,导致最终的数据不一致的情况。
- 部分切流:当全量数据么有问题以后,那么可以通过自定义开关控制,进行部分切流,如果有灰度环境可以在灰度上进行控制,在试验阶段,要保证尽可能的对业务影响最小
- 全量切流:当部分切流验证没有问题后,就会进行全量切流,我们需要可以支持回滚,当一旦有问题,可以快速的做回滚。
增量数据的迁移
首先我们来思考对于增量数据的迁移,处理的方案来说都是基于 双写机制,数据双写是指同时进行新表和老表的写入,让新表与老表中同时都有增量数据,这么做的主要原因一方面是让新数据不丢,另外也是随时可以做回滚。
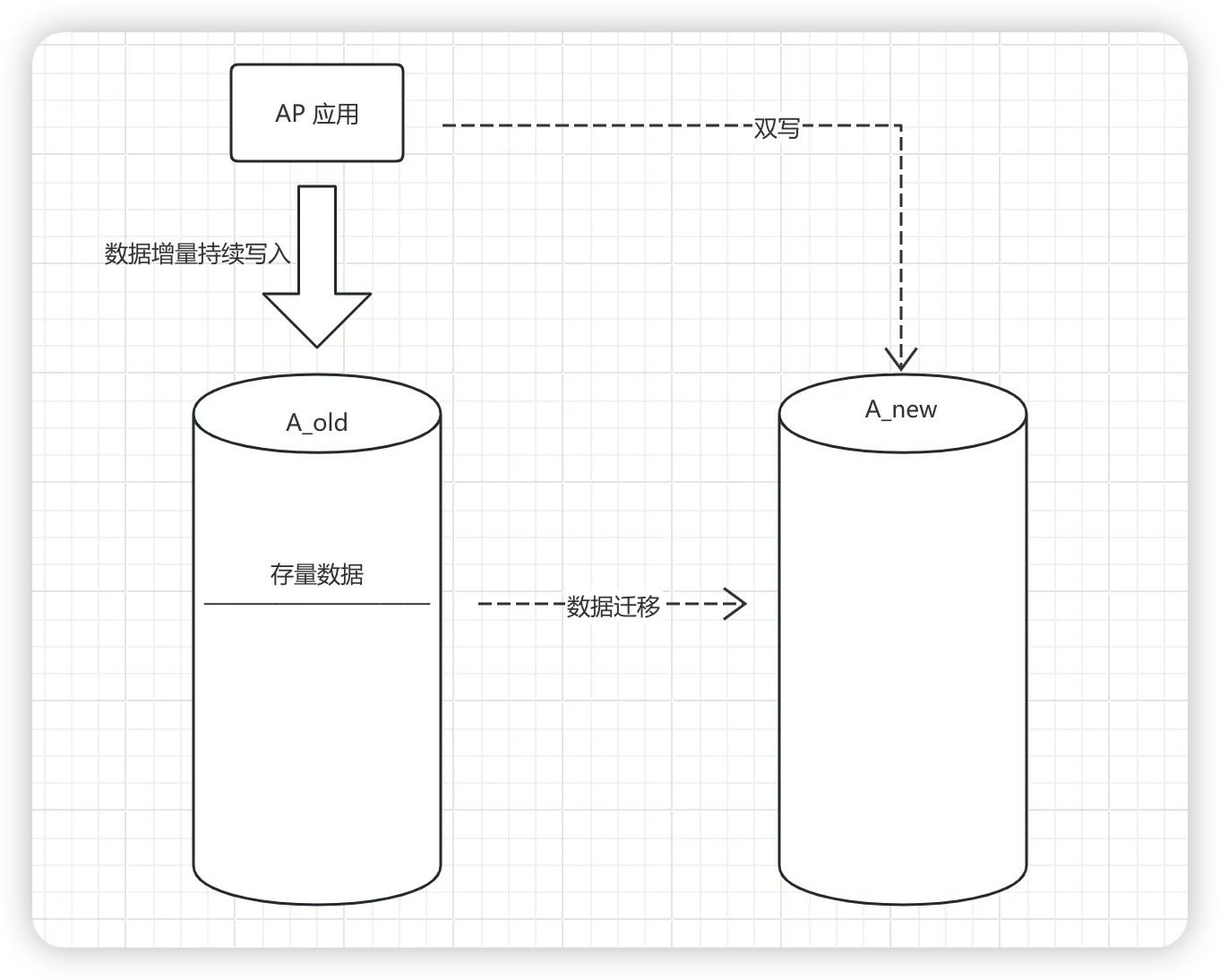
双写的方案有很多,主要有以下这么几种:
- 工具增量双写:在增量双写过程中,我们可以用
canal、flink cdc等这种增量数据更新的工具来进行双写,他们的原理就是在原库写入数据后,基于产生的binlog,自动把数据再写入新库。这个方案的好处是无需编码,支持各种异构的数据库,也支持表结构的各种不一致的转换。缺点就是依赖工具,需要单独部署,同时有可能存在失败或者延迟的风险,一旦过程中出问题了,中间的数据可能会丢失。 - 代码实现双写:我们可以自己编码,在代码中实现双写,即写完旧库之后再写入新库。如果是同一个数据库的不同表的话,这里还可以借助事务保证数据的完整性。但是一般都是跨表或者跨库,所以这里需要考虑好重试的机制。优点就是代码实现的可靠性更强一些,逻辑可以自己定制,缺点就是需要写代码,比较复杂。
- 中间件异步双写:其本质还是编码,但是我们不是直联数据库做写入,而是在写入新库的时候,通过 MQ 来做异步写入。
注意
编码方案中,在新表写入时,序列化ID 需要与旧表保持一致,而不是自增处理。
增量数据更新
在数据迁移过程中,业务数据是会发生不断地变化的,前面的双写我们提了,只把新发生的 insert 当做增量。那这个过程中,如果发生了update 或者 delete 要怎么办呢?
其实这里就需要我们在编码的时候进行控制,在 update/delete 的时候,判断一下这个数据是增量的还是存量的,其实就是判断新表中是否有这个数据,如果有,就需要做双写更新,如果没有,就说明这是个存量数据,只更新旧表就行了。不用担心他们会丢,因为后续我们会做存量同步,这部分更新也会带过来的。
javapubliv viod update(){
if(增量数据){
同时更新旧表和新表();
}else{
更新旧表();
}
}
增量数据核对
在数据迁移过程中,做数据核对是至关重要的。尤其是增量数据,因为增量数据需要双写,双写是有可能失败的,所以需要有一定的机制可以发现这些双写失败的数据。
在做数据核对方面,有很多方式,从编码上来说,像通过定时,单独服务批量查询数据,通过 MD5 加密进行对比;又或者加载到内存中转为字符串通过哈希code对比;建议去做旁路验证,流程是可以通过旁路(可以起一个异步线程,或者通过MQ等)进行一次新库的读取,然后把拿到的结果和旧库的读取作比对,当发现不一致的时候,报警报出来,进行人工核对。
还可以借助工具,把新表和旧表的数据做逐条核对,确保他们的数据是一模一样。
- mysqldiff:MySQL官方mysql-utilities工具集的一部分,用于对比不同数据库间的表结构或数据结构差异
- pt-table-checksum:Percona Toolkit核心工具,专为线上主从数据一致性高效校验设计,支持自动分块控制对业务影响
- Navicat:提供数据同步、结构比对等可视化核对功能
- GitHub check-data工具:支持双库数据CRC32校验及复核机制,可输出详细差异报告
存量数据的迁移
做好了增量数据迁移和核对之后,我们就可以把存量的数据也迁移过来了。存量数据的迁移也有很多方案,比如自己写代码去扫表迁移,也可以通过工具做存量的数据同步。
- DataX:是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
- canal:要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
- Kettle:是一款开源的ETL(Extract, Transform, Load)工具,主要用于数据的抽取、转换和加载。通过Kettle,我们可以轻松地进行数据迁移,实现不同数据库之间的数据传输和整合。它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来进行操作。
- Flink CDC(Change Data Capture,即数据变更抓取)是一个开源的数据库变更日志捕获和处理框架,它可以实时地从各种数据库(如MySQL、PostgreSQL、Oracle、MongoDB等)中捕获数据变更并将其转换为流式数据。Flink CDC 可以帮助实时应用程序实时地处理和分析这些流数据,从而实现数据同步、数据管道、实时分析和实时应用等功能。
对于存量的数据迁移,需要考虑几个问题:
1、不能丢数据:迁移过程中,数据的完整性需要保证,不能中间丢了数据
2、断点能续传:迁移过程中,如果失败了,需要能够在失败处做断点续传,确保不重复不丢失。
3、不要覆盖增量数据:存量数据在迁移的过程中,新表中是有增量数据的,所以,需要确保存量数据的迁移,不会覆盖到这部分已经存在的增量数据。
4、迁移性能要好:存量数据一般都是量很大,所以迁移过程中的性能也是至关重要的。
为了保证数据不丢和能实现断点续传,我们可以在旧表中增加一个字段,来标识出这条记录是否已经被迁移过,这样我们就可以在一条记录迁移成功后,把他的这个标识改了,这样如果中间失败了,我们就知道哪些数据迁移过,哪些数据没迁移过,就只迁移这些没迁移的就行了。
有了这个标识之后,我们就可以做分批的迁移了,因为我们可以通过标记清晰的知道还有多少数据没迁移,可以方便的做分批处理和扫描。
为了不在存量数据迁移的过程中把增量数据覆盖了,这里就需要在 insert 之前做一个检查,判断下这个数据新表中是否已经存在了,已经存在的话,要么就是增量数据双写写进来的,要么就是上一次同步的时候失败了导致旧表的标记没来及更新,不管怎么样,直接认为这条记录已经迁移成功了就行。
提示
对于一些单表的操作,可以通过主键索引来保证唯一性,防止覆盖。
至于性能的问题,我们就需要通过各种手段来解决了,例如批处理,多线程、MQ等。
存量数据核对
存量数据迁移完成以后,需要进行数据核对,与增量数据类似,就不过多描述了。
当增量与存量数据都完成以后,进行一次 全量数据的验证,主要防止增量数据期间产生的数据不一致的情况,验证完成后下一步就是要做读写切流了,要把读请求从老表切流到新表了,在这之前就需要确保是否可以切流。
数据切流
在确保数据都完成迁移之后,我们可以做切流了,一般是先把读请求切流到新的表上,跑一段时间,确保存量和增量数据都没问题,在切流写请求。
切流读新
在切流的时候,我们要逐步进行,比如根据可以基于用户ID的尾号,或者其他的业务字段来做切流,从10%,到20%,再到30%,50%,最后逐步放量到100%,最好有灰度的机制验证。
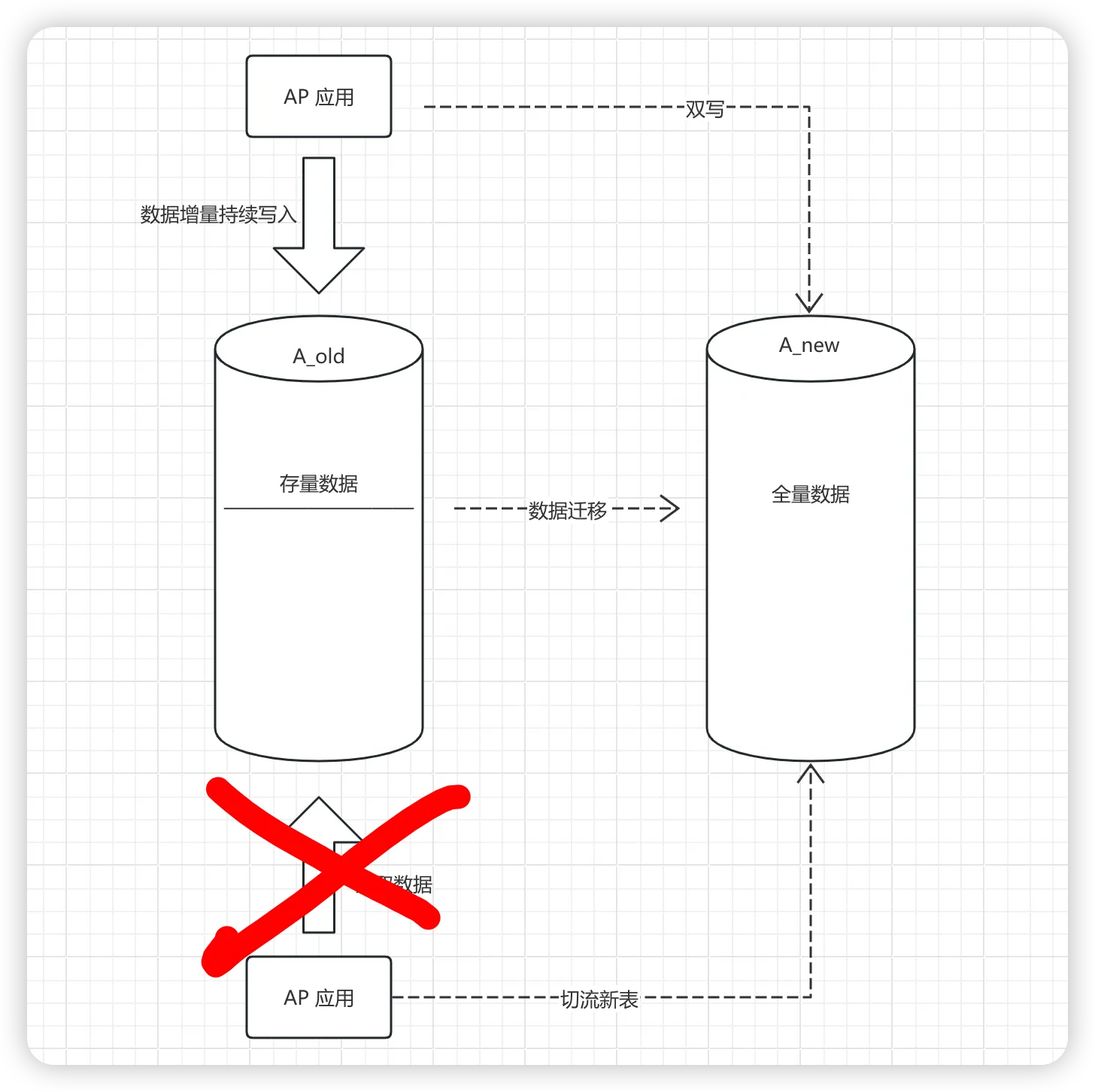
这一步在切流之后,我们的旁路的策略也需要跟着调整。因为切流后读新表了,那么旁路就需要切换到读旧表。
切流写新
这是最后一步了,这一步也是唯一的一步不能回滚的步骤了,开始写切流。
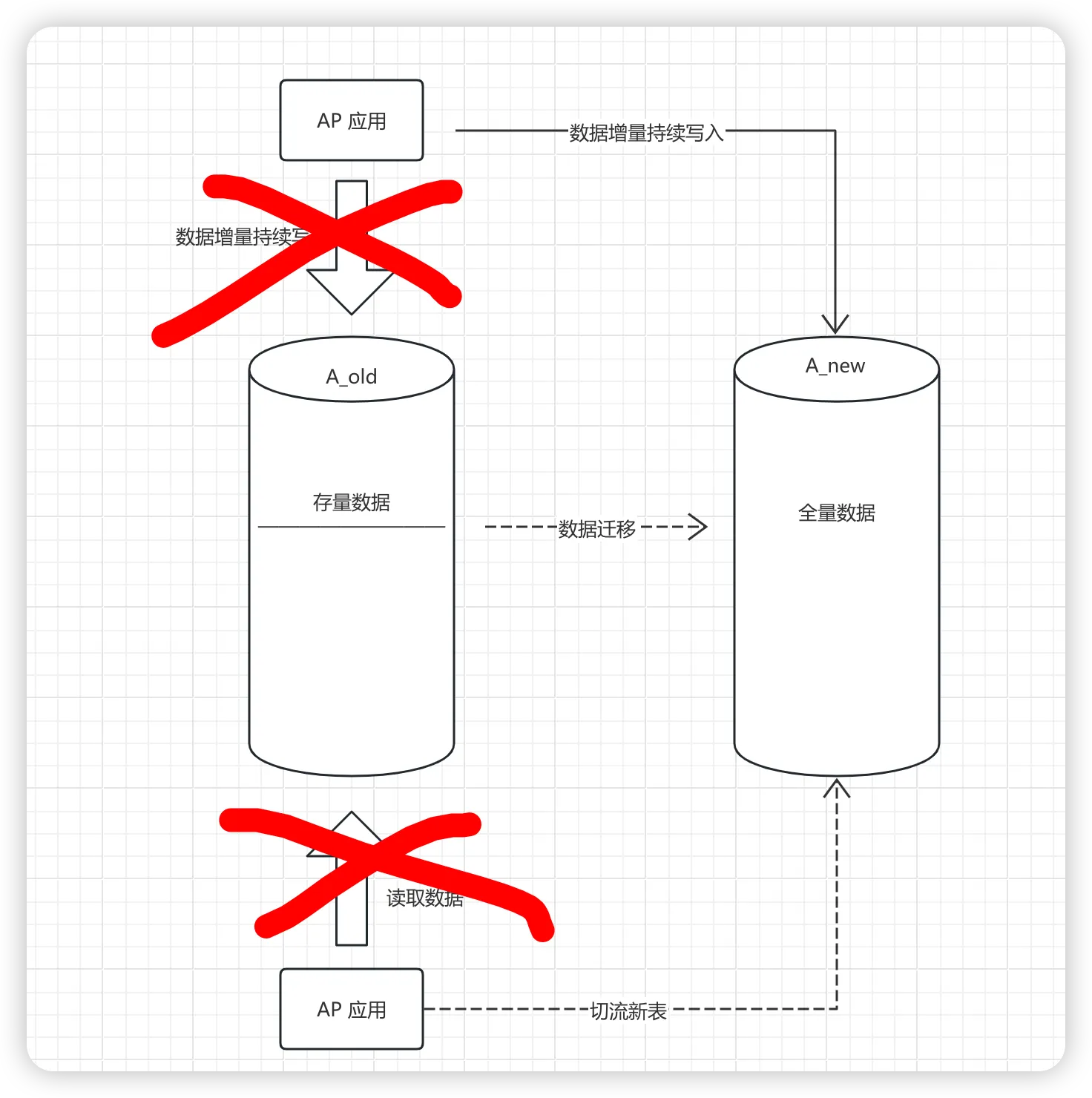
这一步我们就要把双写去掉,完全变成单写了,这一步之后,旧表的数据就不会再做更新了。所以,在这一步之前,要做好足够的验证和核对,确保数据无误之后,在做谨慎操作。建议先切流1%,或者0.1%这样的比例切流。
开关&监控
在上述切流的这个过程中,我们就需要在代码中提前放好开关,然后在上线之后,只需要通过推开关就可以做控制流程的切换了。可以把这些开关配置到配置中心上,然后可以做到动态切换即可。
javaif(flag){
// ...
}else{
// ...
}
这里的 flag 就是个开关,这个值你可以通过配置中心进行动态的调整。
然后,除了核对以外,监控也至关重要,需要做好足够的监控来帮助我们提前的去发现问题。而且监控和核对是要覆盖了整个迁移流程的,一定不能裸奔!
比如在做旧表的读的时候,我们可以通过旁路(可以起一个异步线程,或者通过MQ等)进行一次新库的读取,然后把拿到的结果和旧库的读取作比对,当发现不一致的时候,报警报出来,进行人工核对。
到此我们整个平滑迁移就已经完成了。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!