
目录
在面试中回答过多次分库分表的问题以后,经过几次复盘,我对分库分表的内容已然掌握的炉火纯青,接下来我将根据实际的业务场景,系统性地总结分库分表的回答思路与个人思考的解决方案。
为什么分库分表?
在回答分库分表的问题以前,你是否清晰的了解到你们业务中分库分表的目的?需要以结果为导向,描述业务场景中遇到的问题,以及通过分库分表解决的是哪些问题。
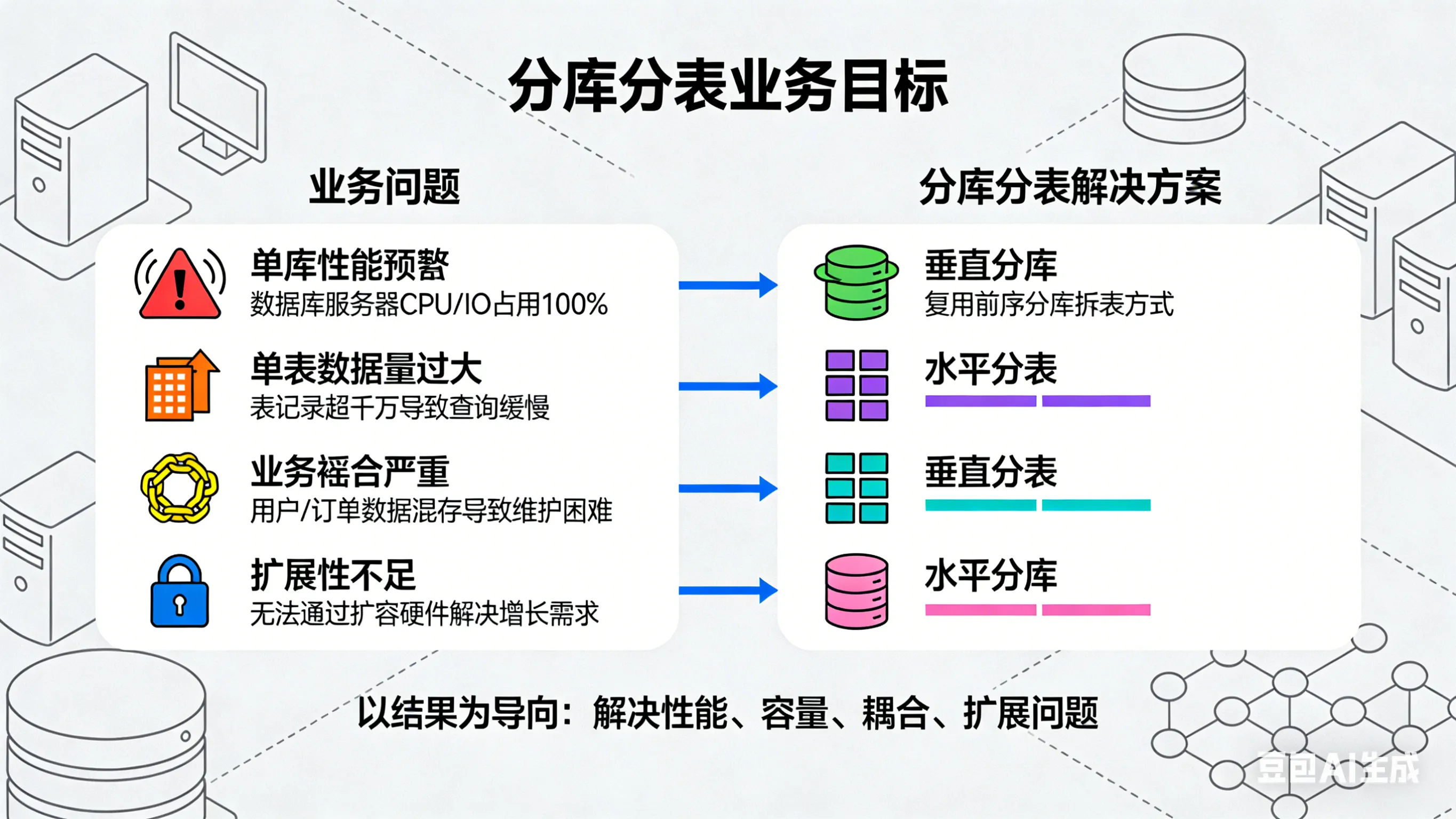
首先我们需要描述下业务的背景,以及遇到的问题,例如我当前的业务场景如下:
我们主要是做光伏电站建设的,每个电站下会有
1到2个逆变器,每个逆变器在光照后会进行发电的工作,每隔5分钟会传输一条发电量数据,一个逆变器平均每天产生120条发电量数据,一年可到到4w多条数据。我们公司整体规划的目标是第一年建站
2w,第二年到10w个电站,由于电站的数量是一个持续增长的过程,很快我们的数据量达到几千万,查询电站下逆变器的发电量信息的性能急剧下降,为此我们采用了分库分表。
描述完场景,我们来引用下分库分表解决了哪些问题
分库分表主要解决了 mysql 读写分离下,写入的性能瓶颈问题,提高系统的吞吐量,同时也解决了单表下数据量存储过大,从而导致的查询性能缓慢的问题。基于我们的业务场景,此处也是为了解决海量数据存储的问题。
接下来结合业务场景,我们来考虑拆分的维度,以及分片数量的考量
分库分表的拆分维度主要分为垂直分库、垂直分表、水平分库、水平分表4个维度,根据我们的数据量上的预估,在3年内会达到
百亿,而一条数据占用1.6K左右,从数据量与内存占用的角度,我们拆分的维度为水平分库和水平分表,拆分为8个库,每个库下128张表,每张表可平均存储千万数据。
分库分表后,我们需要结合业务来进行分片键的抉择
从业务模块的角度进行考虑,我们是展示的是电站分页信息,详情中展示所有逆变器信息,每个逆变器下展示近期的发电量折线图。整体关系为
电站 1 → n 逆变器 1 → n 发电量,基于此场景我们选择电站ID(psId)作为分库的分片键,选择逆变器ID(inveterId)作为分表的分片键,这样保证了查询同一电站下的逆变器数据在同一个数据库中,同一个逆变器的发电量数据都在同一个表当中,提升查询的效率。
选择了分片键,我们需要考虑如何将数据更均匀的分布到表中,如何选择分片的路由算法,与分片键组成 分片策略
其实分片算法有很多,其核心保障均分分配,防止数据倾斜问题。因此分表算法不需要太精密,太复杂,只需要能实现均分分配就行了。弄得太复杂的算法,反而肉眼无法识别,算不明白,这不是很麻烦么。
所以一般就是
取模算法,而我们的业务也是基于取模算法,对电站ID取模,对逆变器ID取模。
到这我们的业务场景已经描述清楚了,接下来就到了面试官的提问环节,大体的方向就是基于我们设计的方案实现,以及分库分表所带来的问题。
分库分表所带来的问题?
分库分表看似美好,其实也带来了很多的分布式问题。
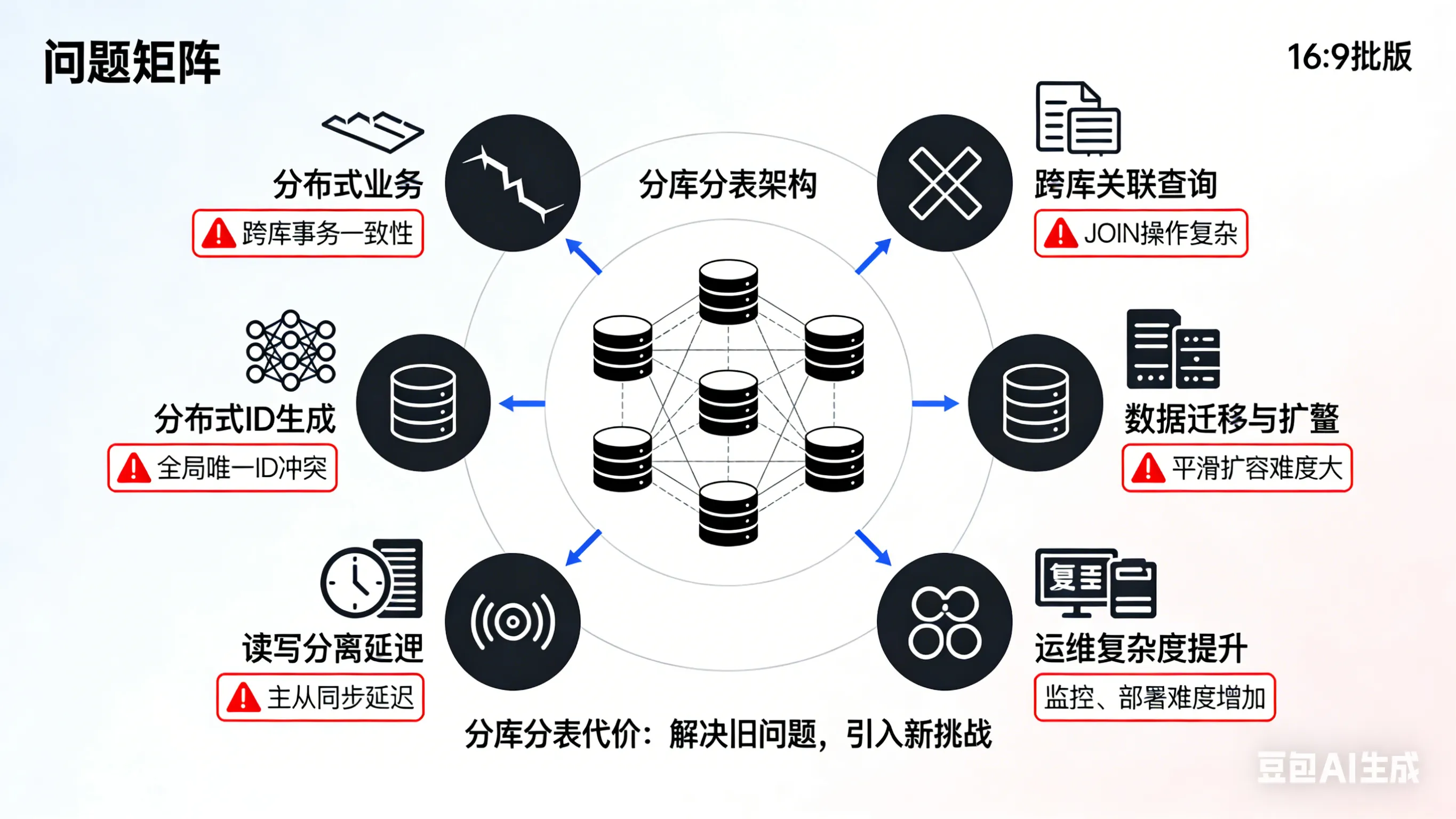
接下来我将总结一下面试官可能会问到的问题。
你们分库分表后是如何保证唯一性ID不重复的?
分库分表以后,分布式序列ID就需要我们自行维护。默认有 UUID、雪花算法两种方案,UUID 基本我们就不考虑,毕竟不符合我们的B+树底层存储结构,也容易造成页分裂,索引碎片化等问题。常用的就是雪花算法,也可以自定义实现,例如结合 Leaf 的号段模式,实现自增的主键ID。
而我们此处采用的是数据库自增ID,根据我们的业务场景,此处的ID并不存在任何意义,所以使用默认的自增主键即可。
采用取模算法,如果扩容是如何保障数据的均匀分布的
取模算法是不支持动态伸缩的,所以说需要需要扩容,我们需要采用
一致性哈希的算法作为路由算法,一致性哈希算法的实现原理就是通过一个0 - 2^32长度的哈希环,类似于循环数组,通过对物理节点进行哈希取模,映射到哈希环中,通过对分片键进行哈希取模,到哈希环中顺时针查找到物理节点,则为存储的节点,本质就是路由寻址的方式。通过扩容后新增物理节点映射到哈希环上,将部分指向物理节点的数据,改指向最近的新节点即可。
联想到 Redis Cluster 哈希槽
其实现本质也是 一致性哈希算法,通过对 Key 进行哈希取模,映射到哈希槽上,也是我们当前 Key 实际存储的节点。
有没有遇到数据倾斜的问题?如何解决的
对于数据分布不均的问题,
一致性哈希算法中,采用虚拟节点的形式,一个物理节点下有多个虚拟节点,映射到哈希中,分片键哈希取模映射到哈希环时,寻址找到虚拟节点时,最终会路由到屋里节点上。虚拟节点越多,数据分布的也更均匀。
分库分表后,排序、遍历、分组、聚合等查询是如何实现的?
像我们使用 ShardingJDBC 中,是通过
执行引擎进行实现的,最核心的是归并引擎, 从结构划分,可分为流式归并、内存归并和装饰者归并。像流式归并中,是逐条从结果集中获取正确的数据,遍历、排序以及流式分组都属于流式归并的一种。而内存归并,则是将所有数据加载到内存中,然后进行分组,聚合封装结果集进行返回。而装饰者归并是在流式归并和内存归并的基础上,进行统一的功能增强,主要有分页归并和聚合归并2种处理。核心就是数据库的结果集是逐条返回的,无需一次性加载到内存中。
分库分表后,分页的多条件查询如何实现?深度分页是如何处理的?
分页的条件查询,基本分为2种实现,
简单查询和复杂查询。如果是简单查询,例如我们想根据订单号(一个订单号就是一个电站,也是一个psId)查询所有分片数据,可以采用基因法,在订单号的设计之初,携带上基因分子,这个基因分子可以是分片键也就是逆变器二进制的后7位(分表数量是128,2的7次方,取模128即可获取到路由表),也可以直接是取模数(后四位类似 0128),在通过订单号查询时,即可获取到分片表,进行直接路由查询。
如果是复杂查询,可以结合ES,构建复杂查询条件的
索引结构,包含主键的ID,在通过ES进行复杂条件查询后,返回其ID,然后通过ID直接查询数据库表即可。对于深度分页,为了避免加载大量数据到内存中,我们采用
select * from tablename where id > 999999 limit 10;的方式,结合ES深度分页,最佳方案也是通过Search After实现, 原理与上述sql类似,通过记录上个分页排序值,继续查找下一页的数据,但是此原理实现的方案有一个缺点,就是不允许跳页。
实现原理
分库分表中的实现也是通过 执行引擎 实现的,结构上采用 装饰者归并。
跨库事务的一致性是如何保障的
其实跨库的事务实现,也就是分布式事务的一种处理,ShardingJDBC 中提供了基于
XA 协议的两阶段事务和 基于Seata 的柔性事务两种方式,其本质就是分布式事务中CP与AP + BASE的抉择。开始描述分布式事务的内容,从CAP原理 + BASE理论,到 DTP 全局事务模型 与 XA 的两阶段提交,以及具体实现 2PC;再到最终一致性的各种实现方案。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!