
目录
上文中了解数据架构的演进,当读写分离后主节点的写入成为性能瓶颈,又或者单表数据量突破数千万大关,数据库性能急剧下降时,在经历读写分离、缓存优化、SQL与索引调优等手段后,核心指标仍然告警,那分库分表成为技术架构演进的必然选择。
今天,我将带你了解 Apache 软件基金会的顶级项目 ShardingSphere ,它提供了一套完整的分布式数据库解决方案,接下来将学习它的核心架构与实战应用,掌握如何将庞大的数据拆分得井井有条。
ShardingSphere
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
官方文档: https://shardingsphere.apache.org/document/current/cn/overview/

Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。

Apache ShardingSphere 由 Sharding-JDBC、Sharding-Proxy 这2款相互独立的产品组成。他们的使用场景如下:
-
Sharding-JDBC:被定位为轻量级Java框架,在Java的JDBC层提供的额外服务,以jar包形式使用
-
Sharding-Proxy:被定位为透明化的数据库代理端,向应用程序完全透明,可直接当做 MySQL 使用
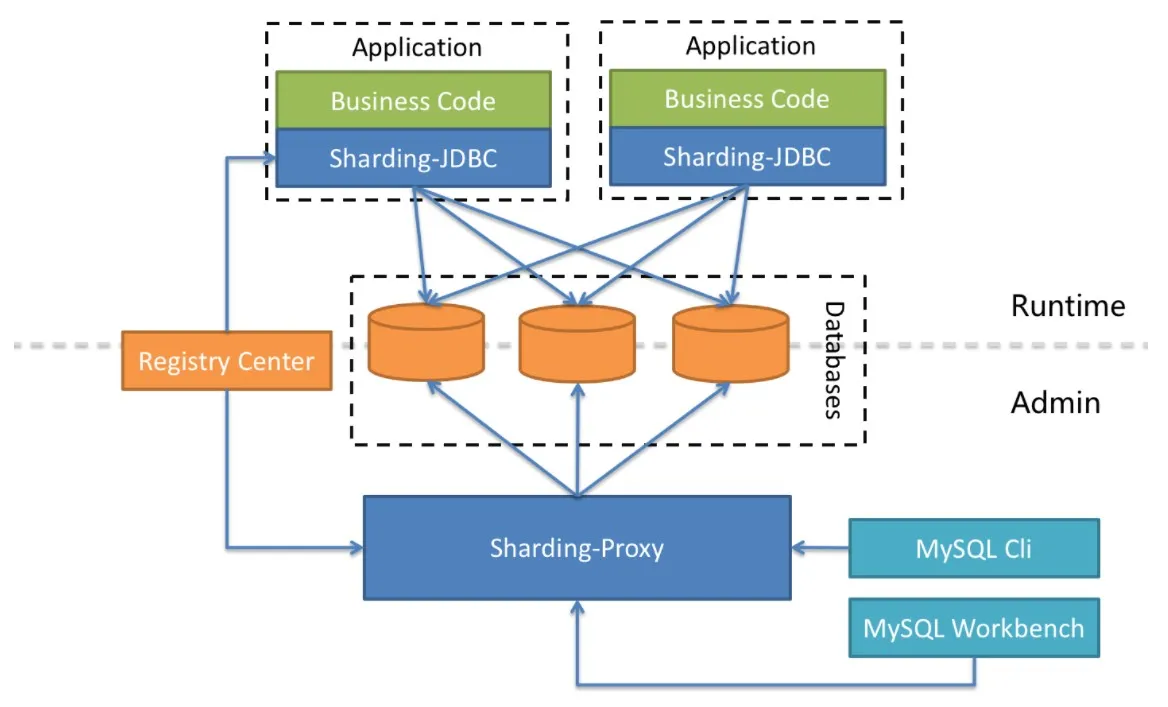
很显然 ShardingJDBC 只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有 分库分表逻辑均有业务方自己控制, 所以他的功能相对灵活,支持的 数据库也非常多,但是对业务侵入大,需要业务方自己定义所有的分库分表逻辑.
而 ShardingProxy 是一个独立部署的服务,对业务方无侵入,业务方可以像用一个普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,但是这也意味着功能会比较固定,能够支持的数据库也比较少,两者各有优劣.
两者均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
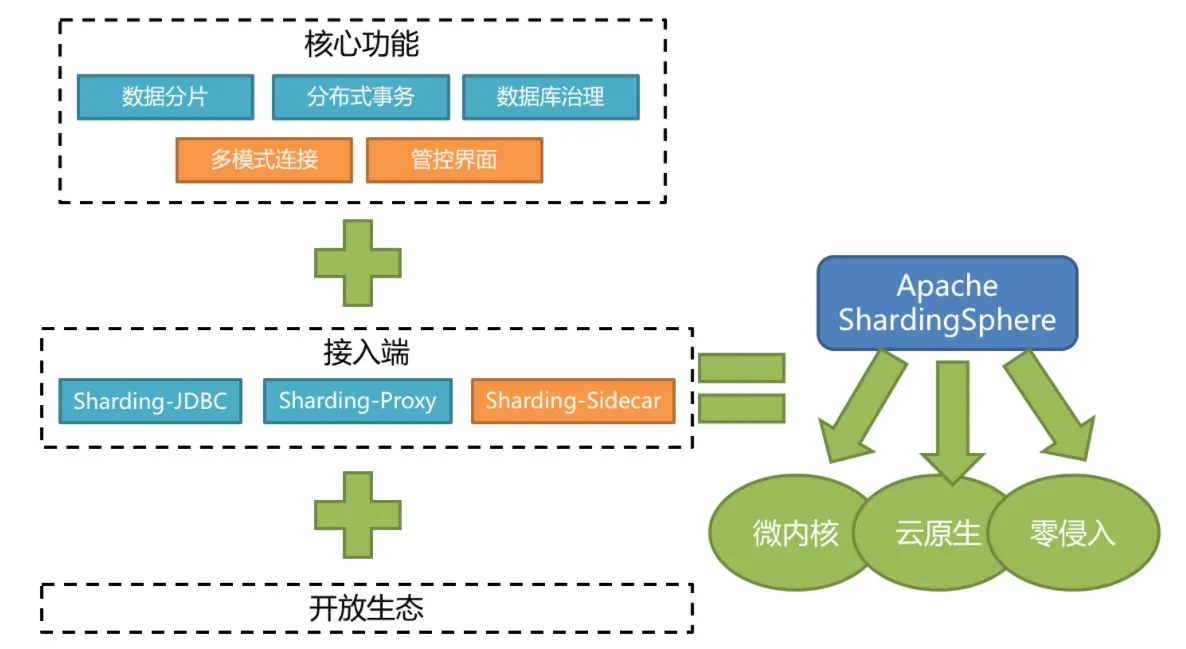
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
Sharding-JDBC
Sharding-JDBC 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架的使用。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
核心功能
数据分片
是应对海量数据存储与计算的有效手段。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储。
广播表
实现在所有数据分片中保持一致的全局数据。
分布式事务
事务能力,是保障数据库完整、安全的关键技术,也是数据库的核心技术。基于 XA 和 BASE 的混合事务引擎,ShardingSphere 提供在独立数据库上的分布式事务功能,保证跨数据源的数据安全。
读写分离
读写分离,是应对高压力业务访问的手段。基于对 SQL 语义理解及对底层数据库拓扑感知能力,ShardingSphere 提供灵活的读写流量拆分和读流量负载均衡。
联邦查询
联邦查询,是面对复杂数据环境下利用数据的有效手段。ShardingSphere 提供跨数据源的复杂查询分析能力,实现跨源的数据关联与聚合。
数据加密
数据加密,是保证数据安全的基本手段。ShardingSphere 提供完整、透明、安全、低成本的数据加密解决方案。
数据脱敏
数据脱敏,根据业界对脱敏的需求及业务改造痛点,提供了一套完整、安全、透明化、低改造成本的数据脱敏整合解决方案
影子库
在全链路压测场景下,ShardingSphere 支持不同工作负载下的数据隔离,避免测试数据污染生产环境。
内部结构
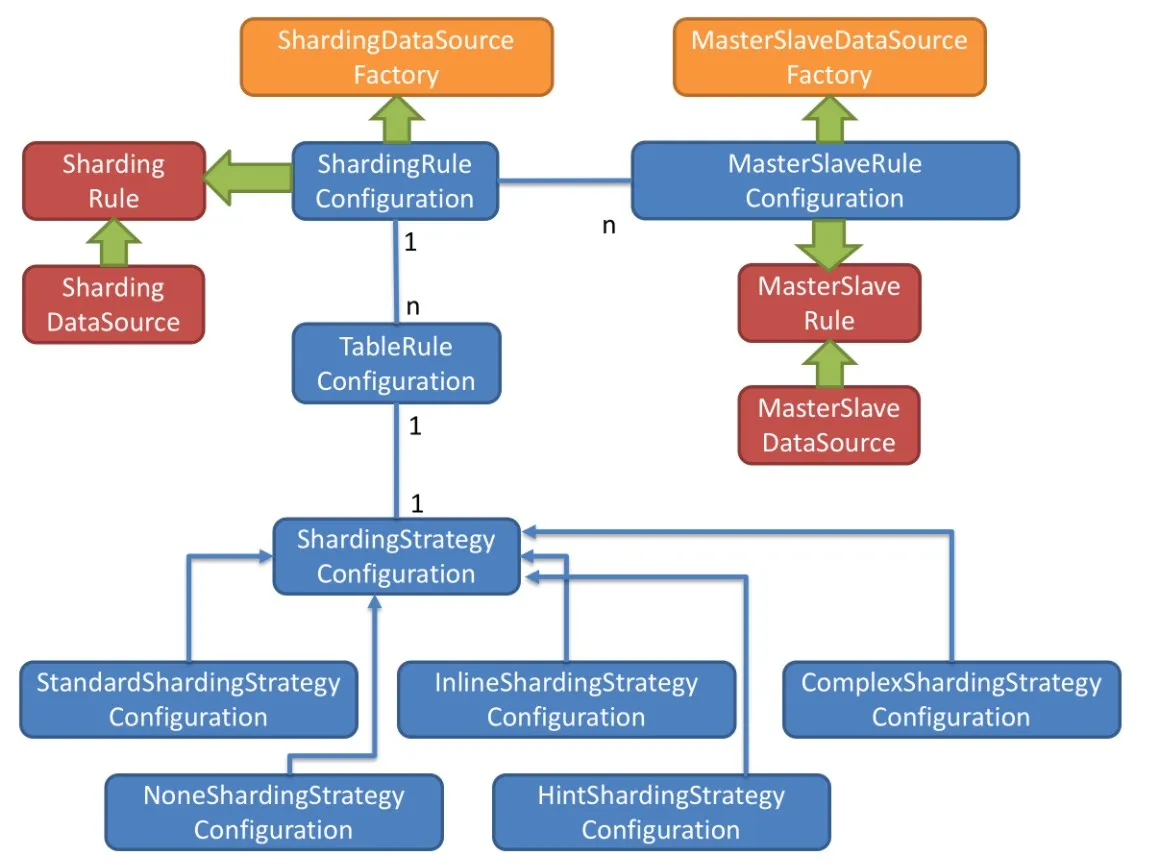
图中黄色部分表示的是 Sharding-JDBC 的入口API,采用工厂方法的形式提供。 目前有ShardingDataSourceFactory 和 MasterSlaveDataSourceFactory 两个工厂类。
ShardingDataSourceFactory支持分库分表、读写分离操作MasterSlaveDataSourceFactory支持读写分离操作
图中蓝色部分表示的是 Sharding-JDBC 的配置对象,提供灵活多变的配置方式。 ShardingRuleConfiguration 是分库分表配置的核心和入口,它可以包含多个 TableRuleConfiguration 和MasterSlaveRuleConfiguration。
TableRuleConfiguration封装的是表的分片配置信息,有5种配置形式对应不同的Configuration类型。MasterSlaveRuleConfiguration封装的是读写分离配置信息。
图中红色部分表示的是内部对象,由Sharding-JDBC内部使用,应用开发者无需关注。
Sharding-JDBC 通过 ShardingRuleConfiguration 和 MasterSlaveRuleConfiguration 生成真正供使用的规则对象。ShardingDataSource 和 MasterSlaveDataSource 实现了 DataSource 接口,是 JDBC 的完整实现方案。
数据分片详解
Shading JDBC 的入门与应用,可以通过官方文档配置:https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/
在这单独说一下集群模式的选择,有两种模式:单机模式、集群模式
yaml# 参数解析
mode (?): # 不配置则默认单机模式
type: # 运行模式类型。可选配置:Standalone、Cluster
repository (?): # 持久化仓库配置
# 单机模式
mode:
type: Standalone
repository:
type: # 持久化仓库类型
props: # 持久化仓库所需属性
foo_key: foo_value
bar_key: bar_value
# 集群模式
mode:
type: Cluster
repository:
type: # 持久化仓库类型
props: # 持久化仓库所需属性
namespace: # 注册中心命名空间
server-lists: # 注册中心连接地址
foo_key: foo_value
bar_key: bar_value
警告
这里的“集群模式”,指的不是 Sharding-JDBC 自身进程组成集群,而是指它能够从外部“集群化”的配置中心(如ZooKeeper、Nacos、Apollo)动态获取和管理分片规则等配置。
推荐使用 集群模式,分片规则集中存储在配置中心,在配置中心修改一次,通过监听机制动态推送到所有应用实例,中心化存储,天然保证所有实例配置一致,适用于实例数多、需频繁弹性伸缩、或配置需频繁变更的生产环境。
接下来我们看数据分片,对于数据分片,有一些核心概念,需要我们理解与掌握。官方文档地址:https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/
对于数据库的垂直拆分一般都是在数据库设计初期就会完成,因为垂直拆分与业务直接相关,而我们提到的分库分表一般是指的水平拆分,数据分片就是将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表t_order_0、t_order_1......t_order7,每张表只保存原表的部分数据。
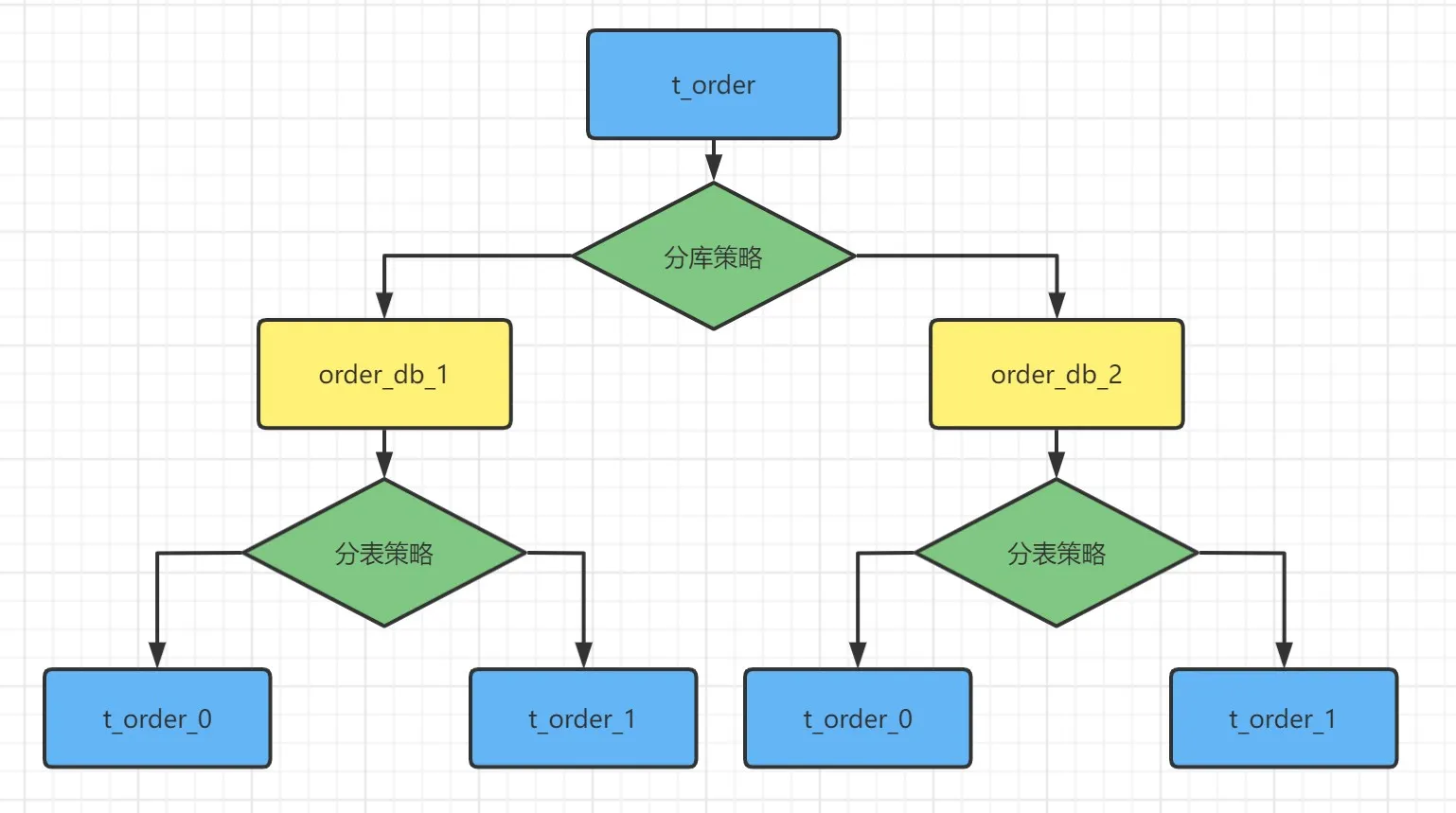
表概念
逻辑表与真实表
在上述示例中 t_order 被称为逻辑表,因为它本身是不存在的,属于业务层面逻辑上的表,我们一般描述都以逻辑表为称。
同样上述示例中的 t_order_0 到 t_order_7 统称为真实表,其本身是在水平拆分的数据库中真实存在的物理表。
数据节点
在分片之后,由数据源和数据表组成。比如: t_order_db1.t_order_0
绑定表
指的是按照相同规则进行分库分表的表进行关联,例如 t_order 和 t_order_item 关联查询,均按照 order_id 分片,则此两个表互为绑定表关系。
sql-- 分片拆分
-- t_order:t_order0、t_order1
-- t_order_item:t_order_item0、t_order_item1
select * from t_order o join t_order_item i on o.order_id=i.order_id where o.order_id in (10,11);
由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
sqlselect * from t_order0 o join t_order_item0 i on o.order_id=i.order_id
where o.order_id in (10,11);
select * from t_order0 o join t_order_item1 i on o.order_id=i.order_id
where o.order_id in (10,11);
select * from t_order1 o join t_order_item0 i on o.order_id=i.order_id
where o.order_id in (10,11);
select * from t_order1 o join t_order_item1 i on o.order_id=i.order_id
where o.order_id in (10,11);
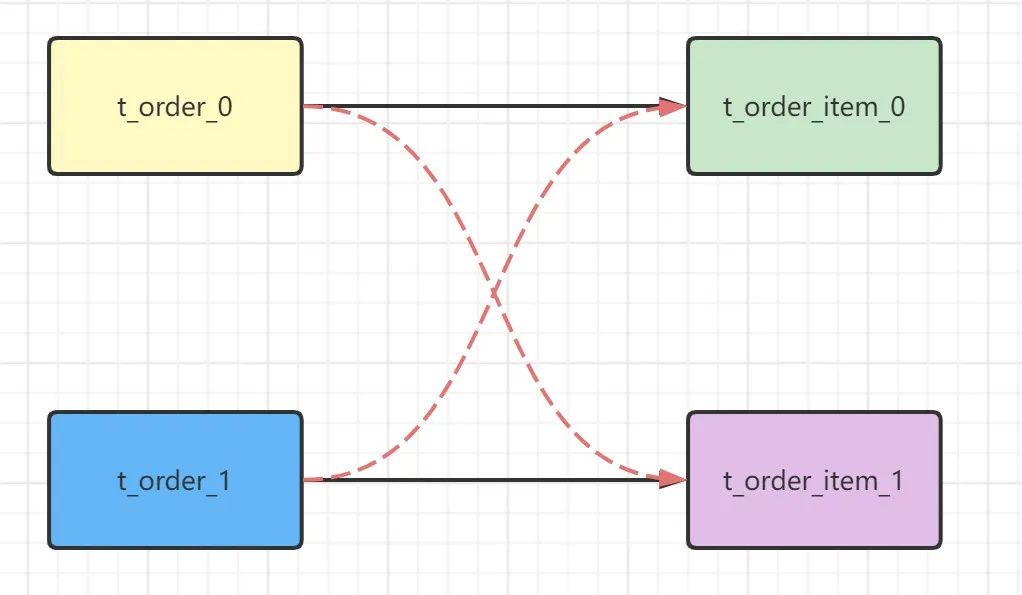
如果配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0 和 t_order_item_0 表关联即可,路由的 SQL 应该为 2 条:
sqlselect * from t_order0 o join t_order_item0 i on o.order_id=i.order_id
where o.order_id in (10,11);
select * from t_order1 o join t_order_item1 i on o.order_id=i.order_id
where o.order_id in (10,11);
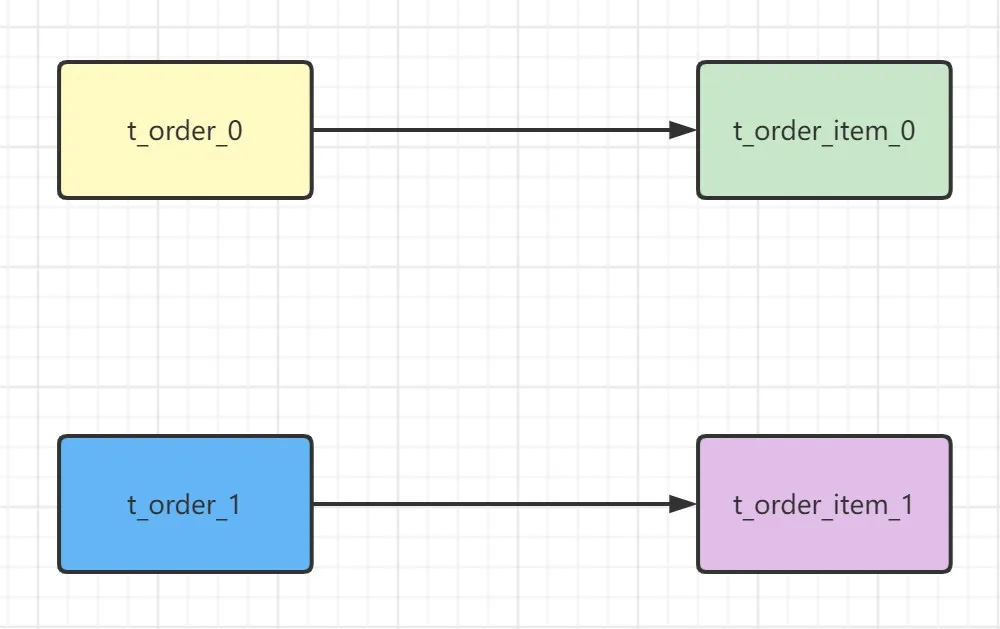
绑定表中的多个分片规则,需要按照逻辑表前缀组合分片后缀的方式进行配置,例如:
yamlrules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
bindingTables:
- t_order, t_order_item
广播表
在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储的表结构和数据完全相同。
单表
指所有的分片数据源中只存在唯一一张的表。适用于数据量不大且不需要做任何分片操作的场景。
分片概念
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。
例:将订单表中的 订单主键ID 取模分片,则订单主键为分片字段。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
提示
SQL 中如果无分片字段,将执行全路由(去查询所有的真实表),性能较差。
分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。
-
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 包括取模、哈希、范围、时间等常用分片算法的实现。
-
自定义分片算法,提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。
分片策略
分片策略(ShardingStrategy) 包含 分片键 和 分片算法,真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
强制分片路由
对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。 例:按照员工登录主键分库,而数据库中并无此字段。 SQL Hint 支持通过 Java API 和 SQL 注释两种方式使用。 详情请参见强制分片路由。
分布式主键
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题,同一个逻辑表(t_order)内的不同真实表(t_order_n)之间的自增键由于无法互相感知而产生重复主键。
尽管可通过设置自增主键初始值和步长的方式避免ID碰撞,但这样会使维护成本加大,缺乏完整性和可扩展性。如果后期需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
ShardingSphere不仅提供了内置的分布式主键生成器,例如UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
内置主键生成器:
-
UUID:采用UUID.randomUUID()的方式产生分布式主键。
-
SNOWFLAKE:在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法,生成64bit的长整型数据。
也可以自定义实现主键生成器。
分片策略
从上述概念中我都知道 分片策略 本质上就是 分片键 + 分片算法 组成,规则配置示例如下:
yamlrules:
- !SHARDING
tables: # 数据分片规则配置
<logic_table_name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
standard:
# 分片列名称
shardingColumn:
# 分片算法名称
shardingAlgorithmName:
# 用于多分片键的复合分片场景
complex:
# 分片列名称,多个列以逗号分隔
shardingColumns:
# 分片算法名称
shardingAlgorithmName:
# Hint 分片策略
hint:
# 分片算法名称
shardingAlgorithmName:
# 不分片策略
none:
分片策略的接口定义如下,它有四个子类,分别对应上面四种分片策略,我们可以通过继承不同的分片策略完成自定义分片策略的扩展。
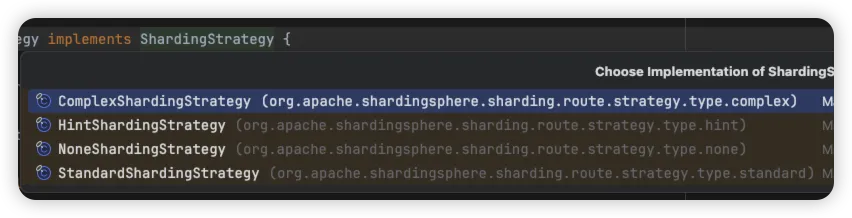
标准分片策略 StandardShardingStrategy
只支持单分片键,提供对SQL语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持,同时提供StandardShardingAlgorithm 类型的分片算法,目前实现了10种分片算法
复合分片策略 ComplexShardingStrategy
支持多分片键。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
Hint 分片策略 HintShardingStrategy
对于分片字段并非由 SQL 而是其他外置条件决定的场景,可使用 SQL Hint 注入分片值。也就是通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。
不分片策略 NoneShardingStrategy
不进行分片的策略。
提示
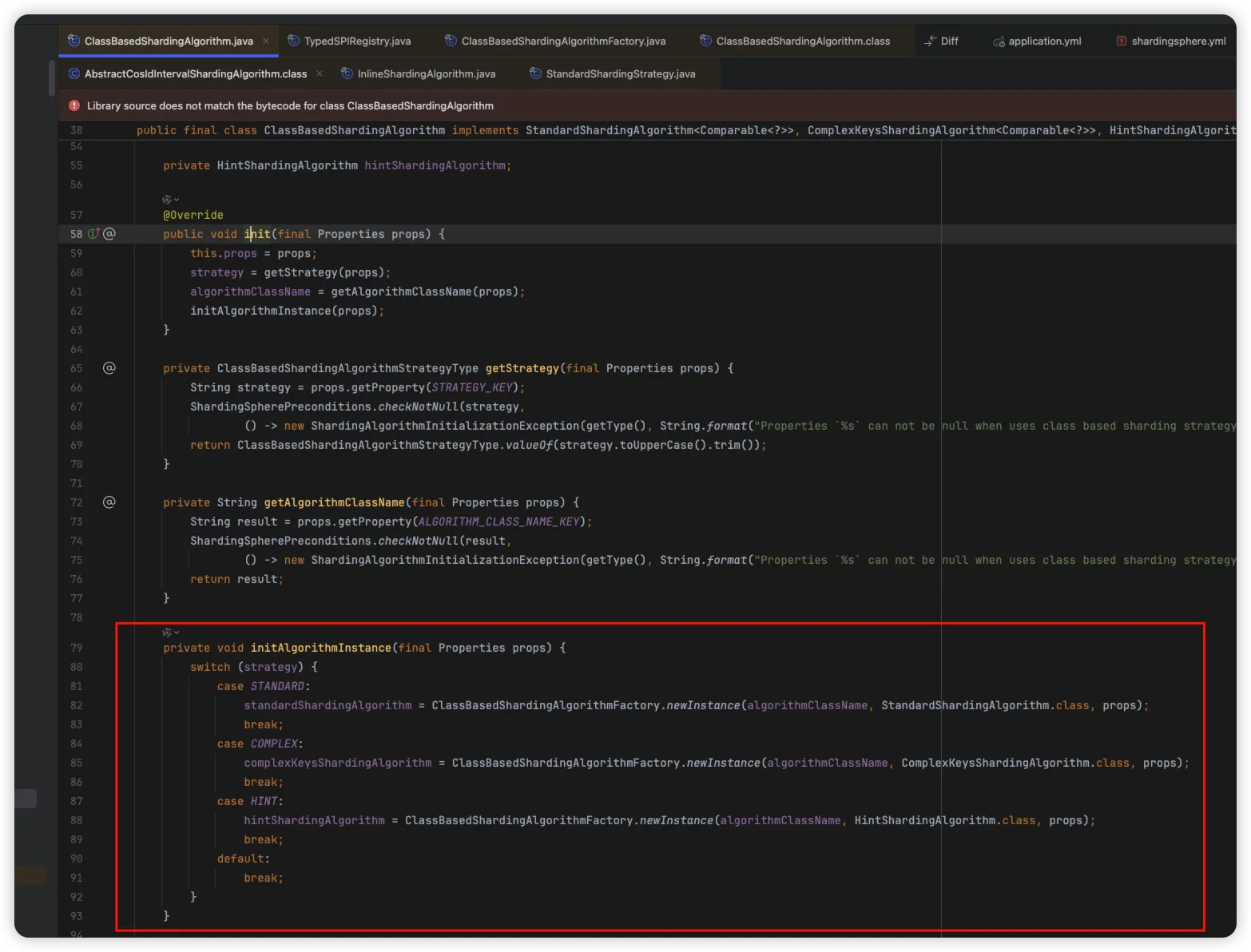
分片策略与分片算法之间的关联,可以查看源码实现 org.apache.shardingsphere.sharding.algorithm.sharding.classbased.ClassBasedShardingAlgorithm#initAlgorithmInstance
分片算法
分片算法与上述的分片策略息息相关,根据策略选择不同类型的算法,同时 Sharding JDBC 也提供了接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
-
标准分片算法:用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
-
复合分片算法:用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
-
Hint 分片算法:用于处理使用 Hint 行分片的场景。
具体实现可以查看官方文档
分片算法的开发者手册:https://shardingsphere.apache.org/document/current/cn/dev-manual/sharding/
分片原理
ShardingSphere 数据分片的原理如下图所示
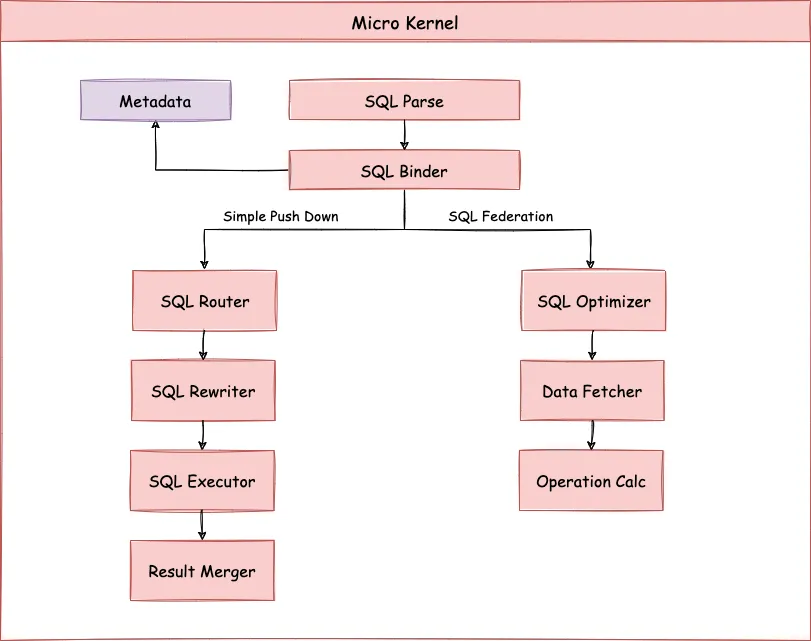
按照是否需要进行查询优化,可以分为 Simple Push Down 下推流程和 SQL Federation 执行引擎流程。
Simple Push Down 下推流程由 SQL 解析 => SQL 绑定 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并 组成,主要用于处理标准分片场景下的 SQL 执行。
SQL Federation 执行引擎流程由 SQL 解析 => SQL 绑定 => 逻辑优化 => 物理优化 => 数据拉取 => 算子执行 组成,SQL Federation 执行引擎内部进行逻辑优化和物理优化,在优化执行阶段依赖 Standard 内核流程,对优化后的逻辑 SQL 进行路由、改写、执行和归并。
根据上述流程,Sharding JDBC 主要提供了 解析引擎、路由引擎、改写引擎、执行引擎、归并引擎 实现完整分库分表,具体可查看官方文档:
- 解析引擎:https://shardingsphere.apache.org/document/current/cn/reference/sharding/parse/
- 路由引擎:https://shardingsphere.apache.org/document/current/cn/reference/sharding/route/
- 改写引擎:https://shardingsphere.apache.org/document/current/cn/reference/sharding/rewrite/
- 执行引擎:https://shardingsphere.apache.org/document/current/cn/reference/sharding/execute/
- 归并引擎:https://shardingsphere.apache.org/document/current/cn/reference/sharding/merge/
归并引擎
为什么单独列一章节归并引擎呢?主要是因为实际开发中我们所遇到的所有问题,几乎都与归并引擎息息相关,接下来我们代入问题来思考归并引擎的实现原理。
提示
大家思考一个问题,在分库分表的场景下,如何实现分页、排序或者聚合的问题呢?
其实在分片的实现原理中,我们将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并,而在归并引擎中,就支持结果归并。从功能上分为遍历、排序、分组、分页和聚合 5 种类型,它们是组合而非互斥的关系。 从结构划分,可分为:
-
流式归并:流式归并是指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。
-
内存归并:内存归并则是需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
-
装饰者归并:装饰者归并是对所有的结果集归并进行统一的功能增强,目前装饰者归并有分页归并和聚合归并这 2 种类型。
流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理,归并引擎的整体结构划分如下图
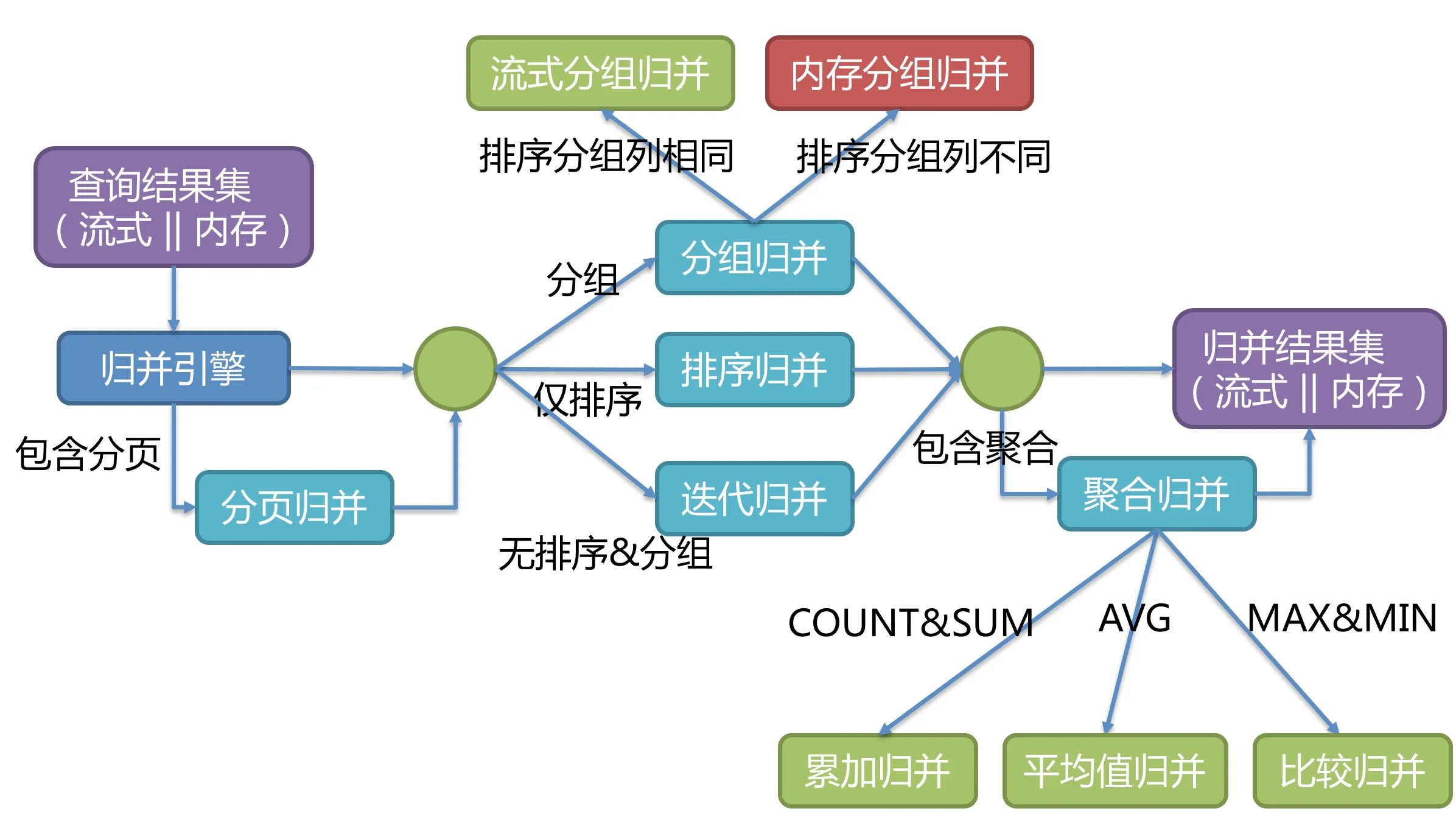
由于从数据库中返回的结果集是逐条返回的,并不需要将所有的数据一次性加载至内存中,因此,在进行结果归并时,沿用数据库返回结果集的方式进行归并,能够极大减少内存的消耗,是归并方式的优先选择。
遍历归并
没有想到合适的应用场景,属于流式归并的一种,只需将多个数据结果集合并为一个单向链表即可。在遍历完成链表中当前数据结果集之后,将链表元素后移一位,继续遍历下一个数据结果集即可。
排序归并 order by
在业务中按照创建时间倒叙都已成一种标准,而在分库分表中,我们需要对查询到的结果集进行汇总然后排序。本身每个结果集都是有序的,我们需要对多个有序的结果集进行排序,最适合的排序算法莫过于 归并排序。
在对排序的查询进行归并时,将每个结果集的当前数据值进行比较(通过实现 Java 的 Comparable 接口完成),并将其放入优先级队列。 每次获取下一条数据时,只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级排序队列找到自己的位置即可。
分库分表下 order by 的实现原理
每个数据结果集中的数据有序,而多数据结果集整体无序的情况下,ShardingSphere 无需将所有的数据都加载至内存即可排序。 它使用的是流式归并的方式,每次 next 仅获取唯一正确的一条数据,极大的节省了内存的消耗。
分组归并 group by
分组归并分为 流式分组归并 和 内存分组归并,流式分组归并要求 SQL 的排序项与分组项的字段以及排序类型(ASC 或 DESC)必须保持一致,否则只能通过内存归并才能保证其数据的正确性。
也就是说流式分组的 select、group by、order by 的条件必须一致才行,例如:
sqlSELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
如果分组项和排序项不一致,由于需要获取分组的相关的数据值并非连续的,因此无法使用流式归并,需要将所有的结果集数据加载至内存中进行分组和聚合。 例如,若通过以下 SQL 获取每位考生的总分并按照分数从高至低排序:
sqlSELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY score DESC;
那么各个数据结果集中取出的数据与排序归并那张图的上半部分的表结构的原始数据一致,是无法进行流式归并的。
聚合归并 max/min/sum/avg/count
无论是流式分组归并还是内存分组归并,对聚合函数的处理都是一致的。 除了分组的 SQL 之外,不进行分组的 SQL 也可以使用聚合函数。 因此,聚合归并是在之前介绍的归并类的之上追加的归并能力,即装饰者模式。聚合函数可以归类为比较、累加和求平均值这 3 种类型。
-
比较类型的聚合函数是指
MAX和MIN。它们需要对每一个同组的结果集数据进行比较,并且直接返回其最大或最小值即可。 -
累加类型的聚合函数是指
SUM和COUNT。它们需要将每一个同组的结果集数据进行累加。 -
求平均值的聚合函数只有
AVG。它必须通过 SQL 改写的SUM和COUNT进行计算。
分页归并 limit
按照我们的理解,分页主要是物理分页和内存分页,那在分库分表中如何实现的呢?如果是内存分页,是否会将大量无意义的数据加载到内存中?
上文所述的所有归并类型都可能进行分页。 分页也是追加在其他归并类型之上的装饰器,ShardingSphere 通过 装饰者模式来增加对数据结果集进行分页的能力。 分页归并负责将无需获取的数据过滤掉。
通过流式归并的原理可知,会将数据全部加载到内存中的只有内存分组归并这一种情况。 而通常来说,进行 OLAP 的分组 SQL,不会产生大量的结果数据,它更多的用于大量的计算,以及少量结果产出的场景。 除了内存分组归并这种情况之外,其他情况都通过流式归并获取数据结果集,因此 ShardingSphere 会通过结果集的 next 方法将无需取出的数据全部跳过,并不会将其存入内存。
但同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到 ShardingSphere 的内存空间。 因此,采用 LIMIT 这种方式分页,并非最佳实践。 由于 LIMIT 并不能通过索引查询数据,因此如果可以保证 ID 的连续性,通过 ID 进行分页是比较好的解决方案,例如:
sqlSELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
或通过记录上次查询结果的最后一条记录的 ID 进行下一页的查询,例如:
sqlSELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
分布式序列算法
在我们的日常开发中,大多数采用MySQL 的自增主键,在数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题,自增主键无法标识数据的唯一性。
为了方便用户使用、满足不同用户不同使用场景的需求,Sharding JDBC 提供了2种内置的分布式主键生成器:
- SNOWFLAKE 雪花算法
- UUID
SNOWFLAKE 配置规则:
yamlrules:
sharding:
key-generators:
# 此处必须要配置,否则会导致报错,因为shardingsphere-jdbc-core-spring-boot-starter需要加载此项配置,官网的demo例子有错
# 分布式序列算法:https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/builtin-algorithm/keygen/
snowflake:
type: SNOWFLAKE
props:
# 在单机模式下支持用户自定义配置,如果用户不配置使用默认值为0。
# 在集群模式下会由系统自动生成,相同的命名空间下不会生成重复的值。
worker-id: 0
# 最大抖动上限值,范围[0, 4096)。注:若使用此算法生成值作分片值,建议配置此属性。此算法在不同毫秒内所生成的 key 取模 2^n (2^n一般为分库或分表数) 之后结果总为 0 或 1。为防止上述分片问题,建议将此属性值配置为 (2^n)-1
max-vibration-offset: 1
# 最大容忍时钟回退时间,默认10,单位:毫秒
max-tolerate-time-difference-milliseconds: 10
除了内置的生成器以外,还抽离出分布式主键生成器的接口,方便我们自行实现自定义的自增主键生成器,例如结合 Leaf 实现的生成器。
数据分片算法应用实战
ShardingSphere 内置提供了多种分片算法,按照类型可以划分为
- 自动分片算法
- 标准分片算法
- 复合分片算法
- Hint 分片算法
自动分片算法
取模分片算法 - 类型:MOD
顾名思义就是通过数据取模来分片,只需要指定分片算法类型和分片的数量,就会自动根据分片键的数据 % 分片的数量 完成分片
分片算法只需要指定类型,和配置一个几个分片的属性即可
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: MOD
# 分片属性
props:
sharding-count: 2
哈希取模分片算法 - 类型:HASH_MOD
和取模算法相同,唯一的区别是针对分片键得到哈希值之后再取模
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: HASH_MOD
# 分片属性
props:
sharding-count: 2
基于分片容量的范围分片算法 - 类型:VOLUME_RANGE
分片容量范围,简单理解就是按照某个字段的数值范围进行分片,比如存在下面这样一个需求,怎么配置呢?
(0~199)保存到表0[200~399]保存到表1[400~599)保存到表2
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: VOLUME_RANGE
# 分片属性
props:
# 最小的范围,0-200
range-lower: 200
# 最大的范围,600 ,如果超过600,会报错
range-upper: 600
# 表示每张表的容量为200
sharding-volume: 200
基于分片边界的范围分片算法 - 类型:BOUNDARY_RANGE
前面讲的分片容量范围分片,是一个均衡的分片方法,如果存在不均衡的场景,比如下面这种情况
(0~1000)保存到表0[1000~20000]保存到表1[20000~300000)保存到表2[300000~无穷大)保存到表3
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: BOUNDARY_RANGE
# 分片属性
props:
# 分片的范围边界,多个范围边界以逗号分隔
sharding-ranges: 1000,20000,300000
自动时间段分片算法 - 类型:AUTO_INTERVAL
根据时间段进行分片,如果想实现如下功能
(1970-01-01 23:59:59 ~ 2020-01-01 23:59:59)表0[2020-01-01 23:59:59 ~ 2021-01-01 23:59:59)表1[2021-01-01 23:59:59 ~ 2021-02-01 23:59:59)表2[2022-01-01 23:59:59 ~ 2024-01-01 23:59:59)表3
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: AUTO_INTERVAL
# 分片属性
props:
# 分片的起始时间范围,时间戳格式:yyyy-MM-dd HH:mm:ss
datetime-lower: '2010-01-01 23:59:59'
# 分片的结束时间范围,时间戳格式:yyyy-MM-dd HH:mm:ss
datetime-upper: '2021-01-01 23:59:59'
# 单一分片所能承载的最大时间,单位:秒,下面的数字表示1年
sharding-seconds: '31536000'
注意
需要注意,如果是基于时间段来分片,那么在查询的时候不能使用函数查询,否则会导致全路由。
sqlselect * from t_order where to_date(create,'yyyy-mm-dd')=''
标准分片算法
标准分片策略 tandardShardingStrategy,它只支持对单个分片健(字段)为依据的分库分表,Sharding-JDBC提供了两种算法实现
行表达式分片算法 - 类型:INLINE
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: INLINE
# 分片属性
props:
# 算法表达式
algorithm-expression: ds_${customer_id % 2 + 1}
时间范围分片算法 - 类型:INTERVAL
和前面自动分片算法的自动时间段分片算法类似,此算法主动忽视了 datetime-pattern 的时区信息。 这意味着当 datetime-lower, datetime-upper 和传入的分片键含有时区信息时,不会因为时区不一致而发生时区转换。
当传入的分片键为 java.time.Instant 或 java.util.Date 时存在特例处理, 其会携带上系统的时区信息后转化为 datetime-pattern 的字符串格式,再进行下一步分片。
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
datetime-pattern | String | 分片键的时间戳格式必须遵循 Java DateTimeFormatter 的格式。例如: yyyy-MM-dd HH:mm:ss,yyyy-MM-dd 或 HH:mm:ss 等。但不支持与 java.time.chrono.JapaneseDate 相关的 GGGGy-MM 等 | |
datetime-lower | String | 时间分片下界值,格式与 datetime-pattern 定义的时间戳格式一致 | |
datetime-upper (?) | String | 时间分片上界值,格式与 datetime-pattern 定义的时间戳格式一致 | 当前时间 |
sharding-suffix-pattern | String | 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM | |
datetime-interval-amount (?) | int | 分片键时间间隔,超过该时间间隔将进入下一分片 | 1 |
datetime-interval-unit (?) | String | 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS | DAYS |
复合分片算法
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片健操作。
Sharding-JDBC内置了一种复合分片算法的实现。
复合行表达式分片算法 - 类型:COMPLEX_INLINE
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: COMPLEX_INLINE
# 分片属性
props:
# 分片列名称,多个列用逗号分隔。如不配置无法则不能校验
sharding-columns: order_id,user_id
# 分片算法的行表达式
algorithm-expression: ds_${order_id % 2 + 1}_${user_id % 2 + 1}
Hint 分片算法
Hint 行表达式分片算法 - 类型:HINT_INLINE
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: HINT_INLINE
# 分片属性
props:
# 分片算法的行表达式
algorithm-expression: customer_id > 8
自定义类分片算法
除了默认提供了分片算法之外,我们可以根据实际需求自定义分片算法,Sharding-JDBC 根据不同的 分片策略 提供了对应类型的扩展实现
自定义类分片算法 - 类型:CLASS_BASED
yaml# 数据分片规则配置
rules:
- !SHARDING
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
database_inline:
# 分片算法类型
type: CLASS_BASED
# 分片属性
props:
# 分片策略类型,支持 STANDARD、COMPLEX 或 HINT(不区分大小写)
strategy: STANDARD
algorithmClassName: cn.liushigong.CustomStandardShardingAlgorithm
总结
ShardingSphere 作为一套成熟的分布式数据库中间件,将复杂的分库分表技术封装成对开发者友好的接口。通过合理的分片策略、绑定表、广播表等机制,它解决了分片后的大多数痛点问题。
在架构选型时,如果你的系统是纯 Java 技术栈且追求极致性能,Sharding-JDBC 是最佳选择;如果需要支持多语言或希望集中管理配置,Sharding-Proxy 更合适;而混合部署则能兼顾二者的优势。
无论选择哪种方式,都要记住:分库分表是解决数据量增长的手段,而不是架构设计的目标。在实施前,请先评估是否真的需要分片——或许优化索引、引入缓存或读写分离就能解决问题。
当数据洪流不可避免地到来时,希望这篇指南能帮助你借助 ShardingSphere 构建出稳定、高性能的分布式数据库架构。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!