
目录
生产环境黄金法则:当JVM出现异常时,命令行工具是比可视化界面更可靠的诊断手段。本文将深入解析JVM核心命令行工具,助你成为线上问题排查专家。
JVM命令行工具全景图
不同的命令有不同的使用场景,根据要分析的内容选择合适的命令工具,注意其中的开销对性能的影响。
| JVM工具命令 | 使用场景 | 生产适用性 | 执行开销 |
|---|---|---|---|
| jcmd | 综合诊断 | ⭐⭐⭐⭐⭐ | 极低 |
| jstack | 线程分析 | ⭐⭐⭐⭐ | 低 |
| jmap | 内存分析 | ⭐⭐⭐ | 中高 |
| jstat | GC监控 | ⭐⭐⭐⭐⭐ | 极低 |
| jinfo | 参数查看 | ⭐⭐⭐ | 低 |
核心工具详解与实战示例
jcmd:全能诊断工具
jcmd 是 Oracle JDK(Java Development Kit)自 JDK 7 起引入的一个强大的诊断工具,用于与正在运行的 JVM(Java Virtual Machine)实例进行交互。它允许用户执行各种诊断命令,比如 线程堆栈分析、堆转储、GC 信息、类加载器统计 等,非常适合在生产环境中对 Java 应用程序进行调试和监控。
sh# 语法
jcmd <pid | main class> <command ...|PerfCounter.print|-f file>
<pid>: 目标 Java 进程的进程 ID。<main-class>: 目标 Java 应用的主类名(可以省略 jar 路径)。<command>: 具体的诊断命令,如 VM.version、Thread.print、GC.heap_info 等。[options]:命令附带的参数(具体取决于命令)。
sh# 查看所有支持的命令
jcmd <pid>
jcmd <pid> help
展示所有命令信息:

具体用法:
sh# 查看JDK版本
jcmd <pid> VM.version
# 查看启动参数
jcmd <pid> VM.command_line
# 强制触发 GC
jcmd <pid> GC.run
# 查看内存统计,显示堆占用情况(老年代、新生代等)。
jcmd <pid> GC.heap_info
# 检查是否发生了死锁,如果存在死锁,会提示 Found one Java-level deadlock
jcmd <pid> Thread.print
# 生成线程快照(替代jstack),用于诊断死锁或高 CPU 问题。
jcmd <pid> Thread.print > thread_dump.txt
# 生成堆转储文件(替代jmap),用于分析内存泄漏或对象分布。
jcmd <pid> GC.heap_dump ./dump.hprof
# 获取类加载统计,显示堆中存活对象的数量及内存占用,按类排序。
jcmd <pid> GC.class_histogram
提示
查询java进程信息
shjps -l
查找类加载统计,包含包路径的前10条记录
shjcmd 7 GC.class_histogram | grep 'com.liushigong' | head -n 10
查询死锁信息
shjcmd 7 Thread.print | grep 'Found one Java-level deadlock' -A 20
查询状态为阻塞的线程
shjcmd 7 Thread.print | grep 'BLOCKED' -A 20
jstack:线程分析利器
jstack 是 JDK 提供的一个命令行工具,用于生成 Java 虚拟机(JVM)的线程转储(Thread Dump).通过分析线程转储,可以快速定位死锁、线程阻塞、CPU 占用过高等问题。
线程转储是 JVM 中所有线程状态的快照,包含以下关键信息:
- 线程的调用栈(Stack Trace)
- 线程的状态(RUNNABLE、BLOCKED、WAITING 等)
- 锁信息(持有的锁或等待的锁)
- 线程优先级和所属线程组
sh# 语法
jstack [options] <pid>
jstack [options] <executable> <core>
jstack [options] [server_id@] <remote server IP or hostname>
- -l 或 --long:输出详细的锁信息,包括哪些线程持有锁和哪些线程在等待锁。
- -F 或 --force:强制生成线程转储,适用于进程无响应的情况。
- -m 或 --mixed:显示混合模式的堆栈信息,即同时显示Java代码和本地代码的堆栈信息。
- -h 或 --help:显示帮助信息,列出所有可用的命令行选项。
- -V 或 --version:显示jstack的版本信息。
sh# 基础线程快照
jstack <pid> > thread_dump.txt
# 包含锁信息(-l参数)
jstack -l <pid> > locked_threads.txt
# 追踪死锁(结合grep)
jstack <pid> | grep -A 1 deadlock
# 查找BLOCKED状态的线程,有助于快速定位可能存在线程阻塞或死锁的问题。
jstack -l [pid] | grep "BLOCKED"
# 远程调试,需要指定远程服务器的IP或主机名。
jstack [server_id@] <remote server IP or hostname>
关键信息解读:
java"main" #1 prio=5 os_prio=0 tid=0x00007f8b4800e800 nid=0x1a03 waiting on condition [0x00007f8b50a0e000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x000000076b8a1c98> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at com.example.MyService.doSomething(MyService.java:42) // 定位到源码行
适用场景:
- 诊断死锁:当Java应用程序出现死锁时,可以使用jstack命令打印线程堆栈信息,并分析哪些线程在等待哪些资源。通过分析这些信息,可以找出死锁的原因并解决它。
- 分析性能问题:当Java应用程序出现性能问题时(如响应时间过长、CPU使用率过高等),可以使用jstack命令获取线程堆栈信息,并查看哪些线程在执行哪些操作。这有助于找出性能瓶颈并进行优化。
- 监控线程状态:使用jstack命令可以实时监控Java应用程序的线程状态,包括正在运行的线程、等待的线程以及阻塞的线程等。这有助于了解应用程序的运行状态并进行相应的调整。
- 分析core dump文件:当Java应用程序崩溃并生成core dump文件时,可以使用jstack命令分析该文件并获取崩溃时的线程堆栈信息。这有助于找出崩溃的原因并进行修复。
注意
执行时 JVM 会有短暂停顿(Safepoint)
jmap:内存分析专家
sh# 堆直方图(安全)
jmap -histo:live <pid> > histo.txt
# 堆转储(谨慎使用)
jmap -dump:live,format=b,file=heap.hprof <pid>
# 内存使用概况
jmap -heap <pid>
注意
使用 jmap 命令时需要注意以下几点:
-dump:live会触发 Full GC- 大堆(>8GB)转储可能导致服务暂停,使用替代方案
jcmd <pid> GC.heap_dump ./dump.hprof
适用场景:
-
内存泄漏检测:使用 jmap 可以帮助识别内存泄漏。通过生成堆的内存映射,开发者可以查看哪些对象没有被垃圾回收器回收,从而确定内存泄漏的源头。
-
堆内存使用分析:分析堆内存的使用情况,包括各个对象的大小和数量,可以帮助开发者理解内存消耗的模式,并据此优化应用程序的内存使用。
-
对象分配统计:jmap 可以提供关于堆中对象分配的统计信息,这有助于了解哪些类的实例化最频繁,哪些类消耗了最多的内存。
-
堆转储:虽然 jmap 本身不直接支持实时堆转储(类似于
jmap -dump:live,format=b,file=heapdump.hprof),但可以通过 jmap 生成整个堆的快照(尽管这通常需要暂停应用程序的运行)。这对于后续使用如 Eclipse Memory Analyzer (MAT) 等工具进行详细分析非常有用。 -
类加载器统计:查看类加载器的统计信息,了解哪些类被加载,以及它们占用的内存量,有助于优化类的加载策略。
-
直方图生成:jmap -histo 命令可以生成一个堆中对象的直方图,显示每个类的实例数量和总大小,这对于识别占用大量内存的对象类型非常有帮助。
生产环境安全操作
随着 JDK 的发展,一些新的工具如 jcmd(通过 jcmd <pid> VM.native_memory 和 jcmd <pid> GC.class_histogram、jcmd <pid> GC.heap_dump ./dump.hprof)提供了类似的功能,且不会暂停应用程序运行。
sh# 1. 设置OOM自动转储(避免手动执行)
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path
# 2. 使用低开销替代方案
jcmd <pid> GC.class_histogram > histo.txt
jcmd <pid> GC.heap_dump ./dump.hprof
jstat:GC监控神器
jstat (Java Virtual Machine Statistics Monitoring Tool) 是用于监控和分析 Java 虚拟机 (JVM) 性能的工具。它提供了 JVM 的运行时信息,比如垃圾收集的状态、内存使用情况、类加载信息等。jstat 是 JDK 中自带的命令行工具,可以帮助开发者和运维人员排查和优化 JVM 性能问题。
sh# 语法
jstat [option] [vmid] [interval] [count]
- option:指定要查看的统计信息类型。
- vmid:JVM实例的进程ID(PID)。
- interval(可选):每次输出的时间间隔,单位为毫秒。
- count(可选):输出的次数。
sh# 每2秒打印GC情况(持续监控)
jstat -gcutil <pid> 2000
# 每2秒打印GC原因
jstat -gccause <pid> 2000
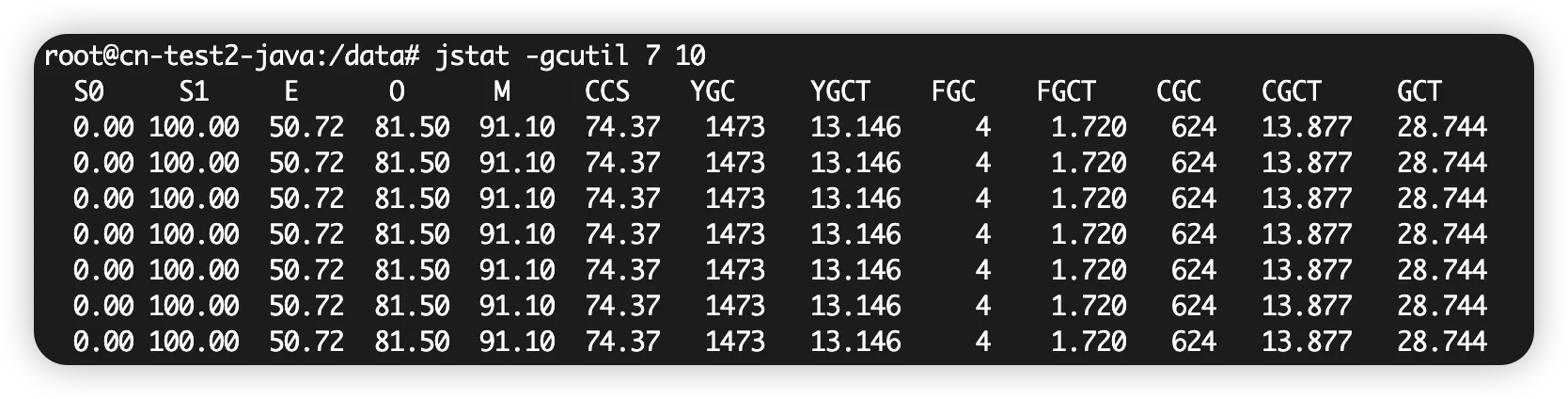
-
S0 — Heap上的 Survivor space 0 区已使用空间的百分比
-
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
-
E — Heap上的 Eden space 区已使用空间的百分比
-
O — Heap上的 Old space 区已使用空间的百分比
-
P — Perm space 区已使用空间的百分比
-
YGC — 从应用程序启动到采样时发生 Young GC 的次数
-
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
-
FGC — 从应用程序启动到采样时发生 Full GC 的次数
-
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
-
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
-
LGCC - 进行GC的原因(低版本jdk可能没有这一列)
关键指标解读:
- O:Old 区使用率 >80% 需告警
- FGC:Full GC次数,每小时>2次异常
- FGCT:Full GC耗时,>1秒需优化
适用场景:
-
监控垃圾收集性能:使用 jstat 可以查看垃圾收集器的行为,包括垃圾收集的次数、垃圾收集花费的时间等。这对于优化垃圾收集器的选择和配置非常有用。
-
监控堆内存使用情况:查看堆内存的使用情况,包括年轻代、老年代的大小和已使用量,这对于诊断内存泄漏和调整堆大小非常关键。
-
分析 JVM 的总体性能:结合多个 jstat 选项,可以获取 JVM 的多方面性能数据,如 CPU 使用率、内存使用情况、垃圾收集活动等。
-
GC参数调优验证:通过监控和分析 jstat 提供的数据,开发者可以调整 JVM 的参数,如堆大小、垃圾收集策略等,以优化应用程序的性能。
-
故障诊断:当应用程序遇到性能问题或内存泄漏时,jstat 可以帮助确定问题的根源,例如是否是由于垃圾收集频繁导致的问题,或者是内存泄漏导致的问题。
jinfo:JVM 参数查看与调整
查看当前 JVM 参数或动态修改部分参数(如日志级别)。
shjinfo [option] <pid>
-flag <name>: 获取指定参数的值。-flag [+|-]<name>: 打开或关闭指定参数。-flag <name>=<value>: 设置指定参数的值。-flags: 打印所有JVM参数。-sysprops: 显示JVM的系统属性
sh# 查看所有参数
jinfo -flags <pid>
# 查看单个参数值
jinfo -flag MaxHeapSize <pid>
# 动态修改参数(仅支持部分)
jinfo -flag +HeapDumpOnOutOfMemoryError <pid>
查看这个JVM进程查看和修改虚拟机的参数,但是修改的有限制的,只有manageble的参数才可以动态修改。其他的必须重启的时候设置修改。
shjava -XX:+PrintFlagsFinal –version
适用场景:
-
监控和调试:在开发和调试阶段,jinfo可以帮助开发者了解JVM的配置情况,确保应用程序能够正常运行。通过查看JVM参数和系统属性,可以快速定位问题并进行调整
-
性能优化:在生产环境中,jinfo可以用于监控和诊断JVM的性能问题。通过分析JVM参数和系统属性,可以优化内存使用、线程管理和垃圾回收等,从而提高应用程序的性能和稳定性
-
参数调整:在需要对JVM参数进行调整时,jinfo可以提供当前进程的配置信息,帮助用户判断哪些参数需要调整以及如何调整。虽然jinfo不支持动态修改某些重要参数,但它仍然是调优过程中的重要工具
注意
注意生产环境慎用写操作
实战问题排查流程
案例1:CPU飙升200%
bash# 1. 定位高CPU线程
top -H -p <pid> # 记录线程ID(十进制)
# 2. 转换线程ID为十六进制
printf "%x\n" 11542 # -> 2d16
# 3. 抓取线程栈
jstack <pid> | grep -A 20 'nid=0x2d16'
# 4. 分析栈轨迹(发现死循环)
while (true) { calculate(); } // 定位问题代码
案例2:内存泄漏排查
bash# 1. 监控GC趋势(发现Old区持续增长)
jstat -gcutil <pid> 1000 10
# 2. 获取堆直方图
jcmd <pid> GC.class_histogram > histo_day1.txt
# 3. 对比数据(8小时后再次抓取)
diff histo_day1.txt histo_day2.txt
# 4. 发现MyObject数量从1k增至5k
# 5. 生成堆转储分析引用链
堆转储深度分析指南
分析工具选择
| 工具 | 优势 | 适用场景 |
|---|---|---|
| Eclipse MAT | 内存泄漏检测强大 | 复杂内存泄漏 |
| VisualVM | 直观易用 | 快速对象分析 |
| JDK Mission Control | 低开销采样 | 生产环境实时分析 |
MAT分析实战步骤
泄漏嫌疑分析:
- 打开histogram视图
- 按Retained Heap排序
- 筛选项目自定义类
定位GC Roots:
java// 示例:ThreadLocal泄漏
Thread @ 0x7fe45b88d
-> ThreadLocalMap @ 0x7fe4a3f1021
-> MyObject @ 0x7fe4a3f1045 (1000个实例)
以上简述了分析流程,我将写一篇专门的MAT工具实战分析。
高级技巧:工具组合拳
内存泄漏终极排查
bash# 1. 实时监控GC
watch "jstat -gcutil <pid> 1000 1"
# 2. 发现Old区增长后立即抓取
jcmd <pid> GC.heap_dump filename=leak.hprof
# 3. 同时获取线程栈
jstack <pid> > thread_state.log
# 4. 分析对象与线程关联
grep 'MyObject' thread_state.log -A 5
安全防护配置
bash# 启动时预置诊断参数
java -XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/logs/heapdumps \
-XX:ErrorFile=/logs/hs_err_pid%p.log \
-Xlog:gc*:file=/logs/gc.log
避坑指南:生产环境注意事项
堆转储安全操作:
- 使用jcmd代替jmap减少影响,
- 同时要避免在业务的高峰时段操作
- 限制转储文件大小:
-XX:HeapDumpMaxFileSize=1g
容器环境特殊处理:
bash# 进入容器执行命令,查看服务的 pid
docker exec -it <container> jcmd
# 分析堆信息
docker exec -it <container> jcmd <pid> GC.heap_info
# Kubernetes诊断Pod
kubectl exec <pod> -- jstack 1 > thread.log
权限管理
- 使用相同用户运行JVM和工具
- 开启-XX:+PerfDataSaveToFile允许只读访问
工具组合建议与踩坑经验
| 问题类型 | 推荐工具组合 |
|---|---|
| CPU 飙高 | top + jstack + Arthas trace |
| 接口卡顿 | Arthas tt/watch/trace |
| 内存泄漏 | jmap + MAT + jstat |
| 类加载冲突 | jad, sc, classloader |
| 容器内调试 | Arthas 支持 docker 内 attach |
经验总结
线上性能问题,无非就2种,一种是CPU飙升,另一种就是内存打满,根据不同的问题类型使用不同的命令工具分析。90%的JVM问题可通过 jcmd+jstack+jstat 组合定位。
记住:优秀的开发者能写代码,卓越的工程师能救火!


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!