
目录
之前我们了解到,Mysql中主流的存储引擎是 InnoDB 和 MyISAM,接下来本文将深入了解存储引擎机制,探索默认的存储引擎 InnoDB 是如何解决并发问题的,同时深入mvcc 与锁机制。在学习的过程中掌握 ACID,结合MVCC与锁机制,去探索可重复读与脏读的原理。
InnoDB 引擎
事务及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有4属性:
- 原子性(Actomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。
- 隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化( serializable).
- 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
事务的实现
事务分为两种实现方式,自动提交与手动提交,默认是自动提交的
- set autocommit-0: 禁止自动提交。
- set autocommit=1: 开启自动提交,
自动提交用 begin、rollback、commit 实现
- begin: 开始一个事务
- rollback: 事务回滚
- commit: 事务确认
隔离级别
我们已经知道事务有隔离性,而事务的隔离性又分为4大隔离级别
未提交读(read uncommitted)
事务A 对数据进行修改,但未提交。此时开启事务B,在事务B 中能读到
提交读(read committed)
事务A对数据进行修改,但未提交。此时开启事务 B,在事务 B中不能读到事务 A 中对数据库进行的未提交数据的修改。事务A 中对数据库的修改。在事务B还没有关闭时,事务A 提交对数据库的修改,这时,我们在事务 B 中可以査到事务A 对数据库的修改。不过这种提交读存在一个问题,即在同一个事务中对数据库查询两次,两次的结果不一样。
可重复读(repeatable read)
在同一个事务内对于同一条 SQL 语句在不同时刻査询返回的结果一致,这被称为可重复读,可重复读是 InnoDB 的默认级别。在 SQL 标准中,该隔离级别消除了不可重复读,但是还存在幻读(虽然rr的隔离级别下提供了解决幻读的机制,但是某些场景下并未完全解决幻读)。
串行化( serializable)
在开启事务 A 时会产生表级锁,此时别的事务会等待事务 A 结東后才会开启。一般数据库都不会采用串行化,因为无论进行什么操作都不会加锁,所以不具备可用性
MVCC
MVCC(Multi Version Concurrency Control),多版本并发控制。
它保留与己更改数据行旧版本的信息以支持事务功能,例如并发和回滚,该信息以回滚段的数据结构存储在撤销表的空间中。InnoDB 使用回滚段中的信息来执行事务回滚所需的撤销操作。这些信息还用来构建数据行的早期版本以实现一致读取。
本质
其本质就是基于乐观锁的思想,在不同事务当中进行版本控制,根据当前活跃的事务ID进行快照读。
MVCC在 提交读(Read Committed) 以及 可重复读(Repeatable Read) 中才会使用到。
实现原理
MVCC的实现是基于 隐藏字段、undo log、Read View 这三者配合实现的。
隐藏字段
在 InnoDB 内部,InnoDB 为存储在数据库中的每一行添加3个隐藏字段:
-
DB_TRX_ID: 标识最近一次对当前行数据做修改(Insert,Update)的事务ID。至于delete操作,属于Update。事务ID是递增的~~
-
DB_ROLL_PTR: 回滚指针,undo log中记录的多个版本之间,使用DB_ROLL_PTR来连接上。
-
DB_ROW_ID: 如果表里没有主键,没有非空唯一索引,那么这个隐藏字段 行ID 会作为聚簇索引存在。这玩意和MVCC关系不大,了解即可。
undo log 存储
在MVCC内部,是基于InnoDB通过 undo log 保存的数据记录的版本信息 来实现的。每个事务读到的数据版本可能会不一样。在同一个事务中,用户只能看到当前事务创建快照前就已经提供了的数据,以及事务本身操作的数据。
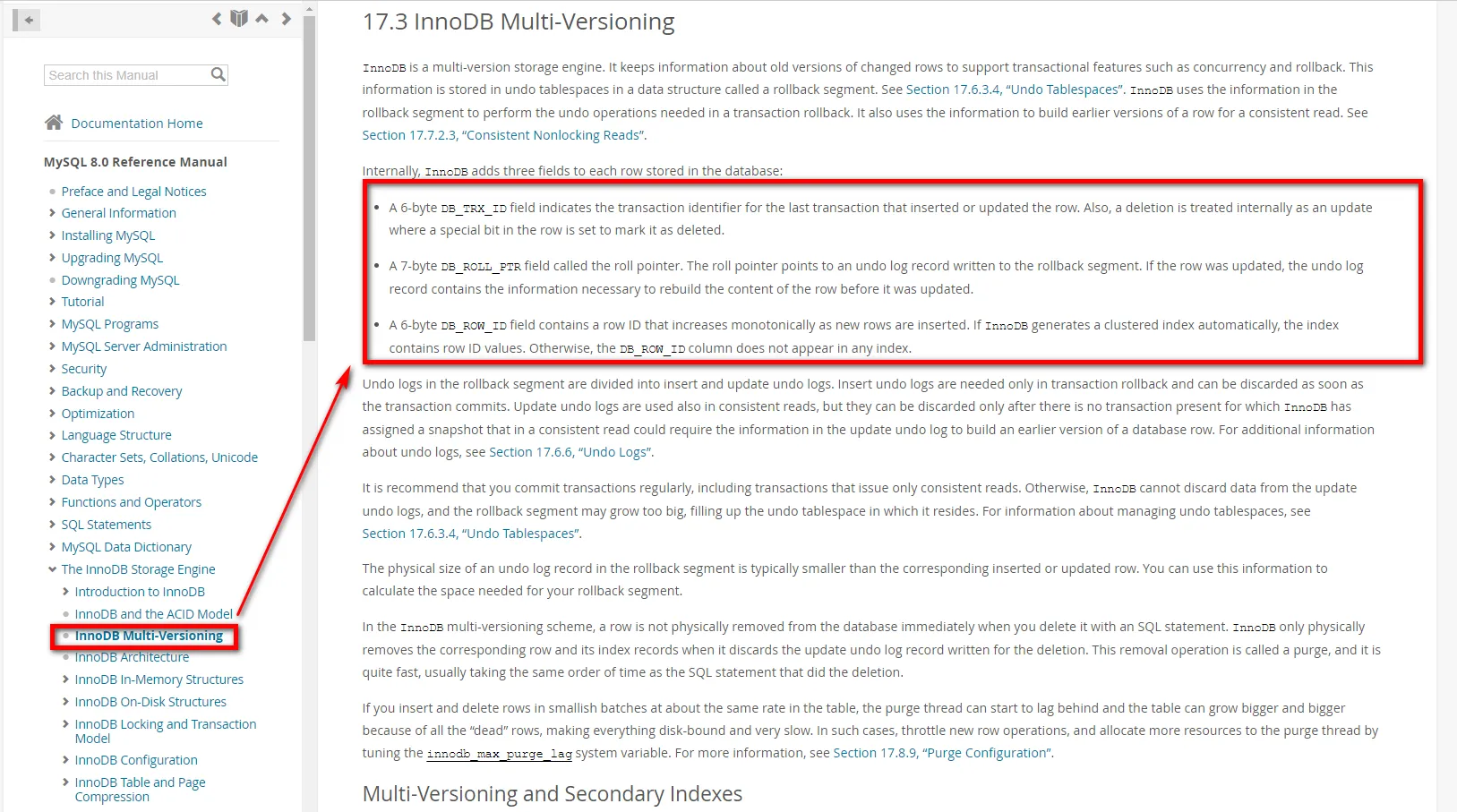
比如现在有一张user表,里面有id,name两个字段。现在数据存在一条,id = 1,name = 张三,现在长这样

现在有一个事务ID为2,要修改这个数据,将name修改为李四,内部处理如下
- 获取互斥锁
- 需要先将当前数据行复制到undo log中,作为旧版本。
- 复制完毕后,将张三修改为李四,并且将DB_TRX_ID修改为2,并且将回滚指针指向undo log里的旧版本
- 提交事务后,释放锁。
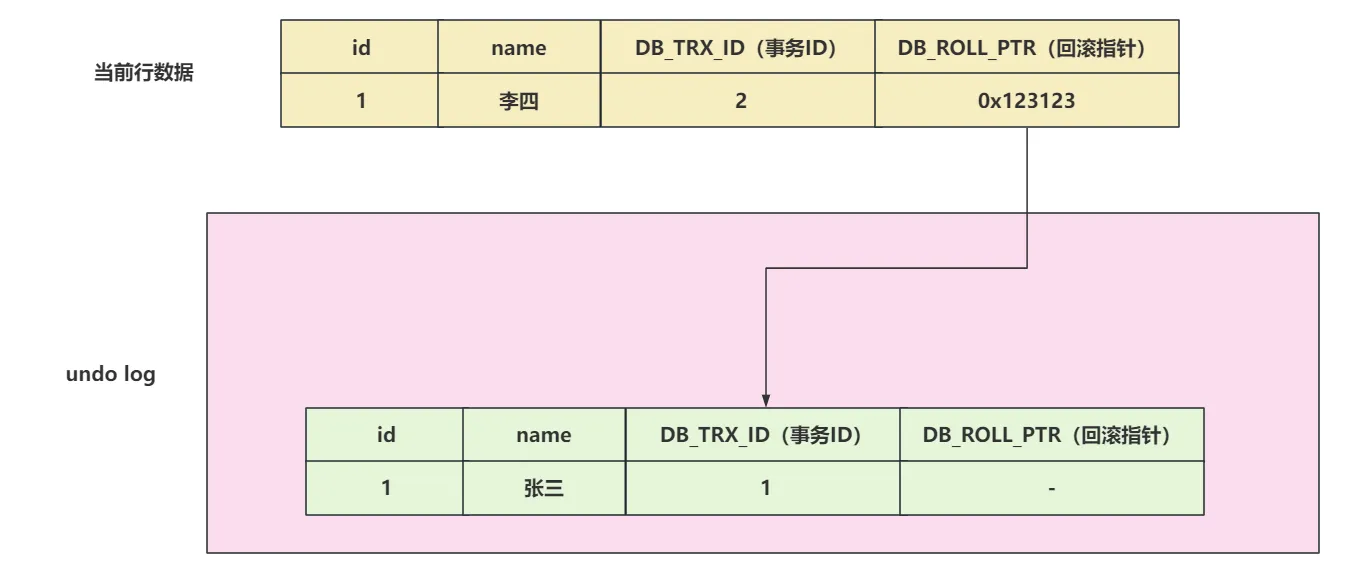
现在又来了一个事务ID为3,修改这行数据,将李四修改为王五
- 获取互斥锁
- 需要先将当前数据行复制到undo log中,作为旧版本。
- 复制完毕后,将李四修改为王五,并且将DB_TRX_ID修改为3,并且将回滚指针指向undo log里的旧版本
- 提交事务,释放锁
Read View
什么是Read View?
说白了,Read View就是事务进行快照读操作的时候产生的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统数据以及当前活跃事务的ID(就是启动了还没提交的事务)。
什么是当前读和快照读
-
当前读:使用到当前读的场景有select lock in share mode(共享锁)、 select for update 、 update、insert、delete(排他锁)等,这些操作都是一种当前读,因为它需要读取记录的最新版本,而且读取时还有可能会通过加锁保证其他事务不能同时修改当前记录。
-
快照读:快照读一般指不加锁的select操作,当然如果MySQL数据库的事务隔离级别是串行隔离级别,串行级别下的快照读会退化成当前读。
Read View 其实和快照是一个意思。Read View 是 读操作中的可见性判断 的核心,也就是当前事务能不能读取 undo log 中的某行数据以及当前行数据的核心。
在开启事务后, 执行第一个select操作后 ,会创建一个Read View,也就是快照。
在 Read View 中会保存不应该被当前事务看到的,其他 活跃事务的列表 。
当用户在这个事务中要读取某行记录时,InnoDB会将该行的 DB_TRX_ID 和 Read View 中的一些变量去做比较,判断当前数据能否查看到。

这四个属性中,分别聊一下:
-
m_creator_trx_id: 当前事务的TRX_ID,也就是事务ID
当前事务的ID,当前事务要创建这个Read View快照。 -
m_ids: 创建快照时,处于活跃事务的ID集合。
未提交事务的事务的集合。因为事务没提交,所以这里的数据是不可见的。 并且活跃事务列表不会记录当前事务。 -
m_low_limit_id: 读取时不应看到任何trx id>=此值的事务。换句话说,这是“高水位线”
当前行数据的事务ID,大于等于m_low_limit_id,数据是不可见的。 说白了,当前事务在创Read View快照时,这个事务他还没开始呢,他的数据必然是不可见的。 通过查看m_low_limit_id的赋值,可以得知他是还未被分配的事务的最小事务ID, 其实就是最大活跃事务 + 1。 -
-
m_up_limit_id: 读取应该看到所有严格小于(<)此值的trx id。换句话说,这是低水位线”
他是活跃事务列表中的最小事务ID ,比这个事务ID还要小的值,他事务必然已经提交了,所以如果当前行数据的事务ID 小于 m_up_limit_id,我是可见的。 如果活跃事务列表为空,m_up_limit_id = m_low_limit_id。
-

在提交读RC的隔离级别下,每次执行select操作时,都会创建一个全新的 Read View。
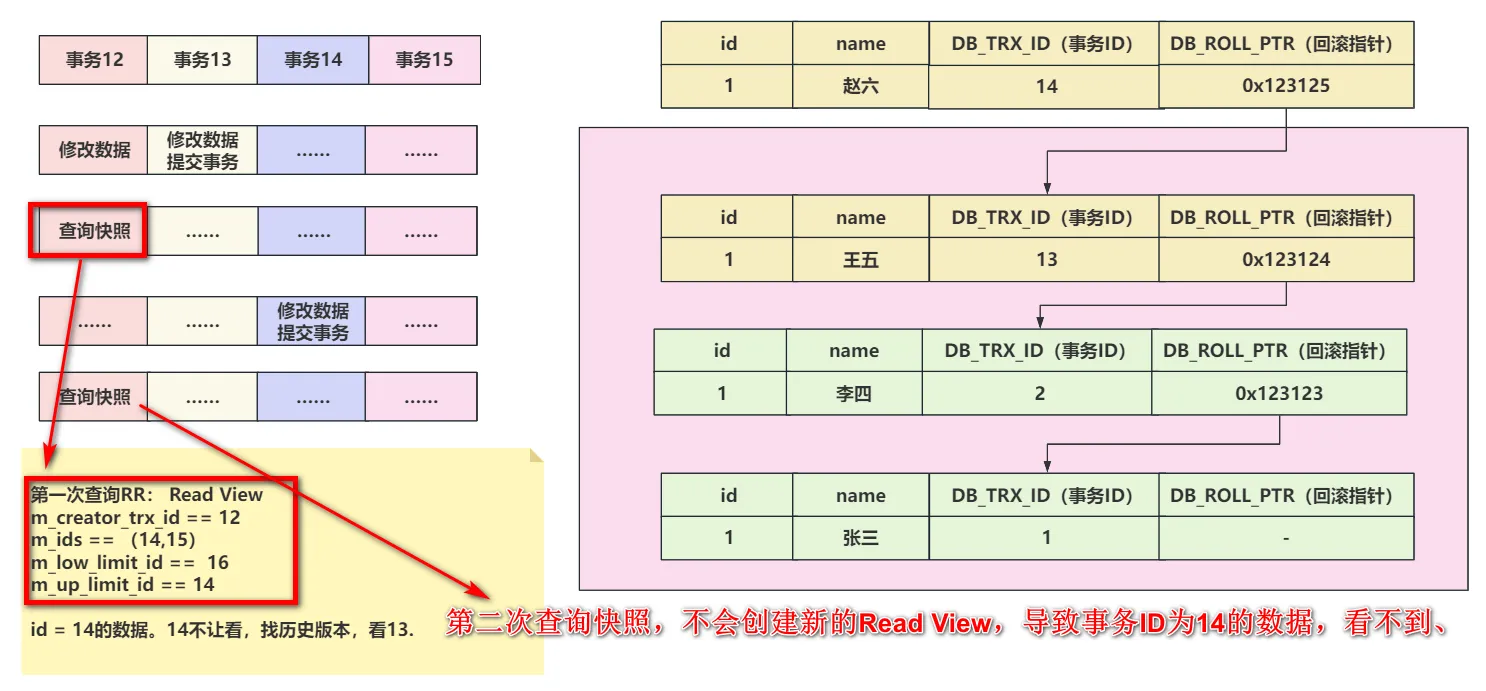
在可重复读RR的隔离级别下,只有第一次select操作时,会创建Read View,后续再查询,都基于第一次的Read View做可见性判断。
ReadView可见性判断的逻辑
在源码中,可以看到可见性判断的逻辑
C// id参数,是你想查看的那行数据的事务ID
bool changes_visible(
trx_id_t id, const table_name_t& name) const MY_ATTRIBUTE((warn_unused_result)){
ut_ad(id > 0);
// m_up_limit_id 是活跃事务的最小id,如果当前行的事务ID,小于m_up_limit_id,说明这个事务必然已经提交了,这个数据是可见的。
// 如果当前行的事务ID和当前创建ReadView的事务ID相等,说明就是当前事务修改的数据,必然可见。
if (id < m_up_limit_id || id == m_creator_trx_id) {
return(true);
}
check_trx_id_sanity(id, name);
// 当前行的事务ID,大于了m_low_limit_id,必然不可见。创建Read View的时候,m_low_limit_id这个事务还没有呢。
if (id >= m_low_limit_id) {
return(false);
// 没有活跃事务,并且当前行数据的事务ID,还小于m_low_limit_id,那这个数据必然可见。
} else if (m_ids.empty()) {
return(true);
}
const ids_t::value_type* p = m_ids.data();
// 如果上述情况都不满足,无法判断可见还是不可见,此时需要拿着当前行的事务ID,以及活跃事务列表开始判断。
// 1、如果我发现当前行的事务ID,在活跃事务列表中。此时在Read View来说,这个事务没提交,不可见。
// 2、如果我发现当前行的事务ID,不在活跃事务列表中,说明创建Read View时候,你就提交了,可见。
return(!std::binary_search(p, p + m_ids.size(), id));
}
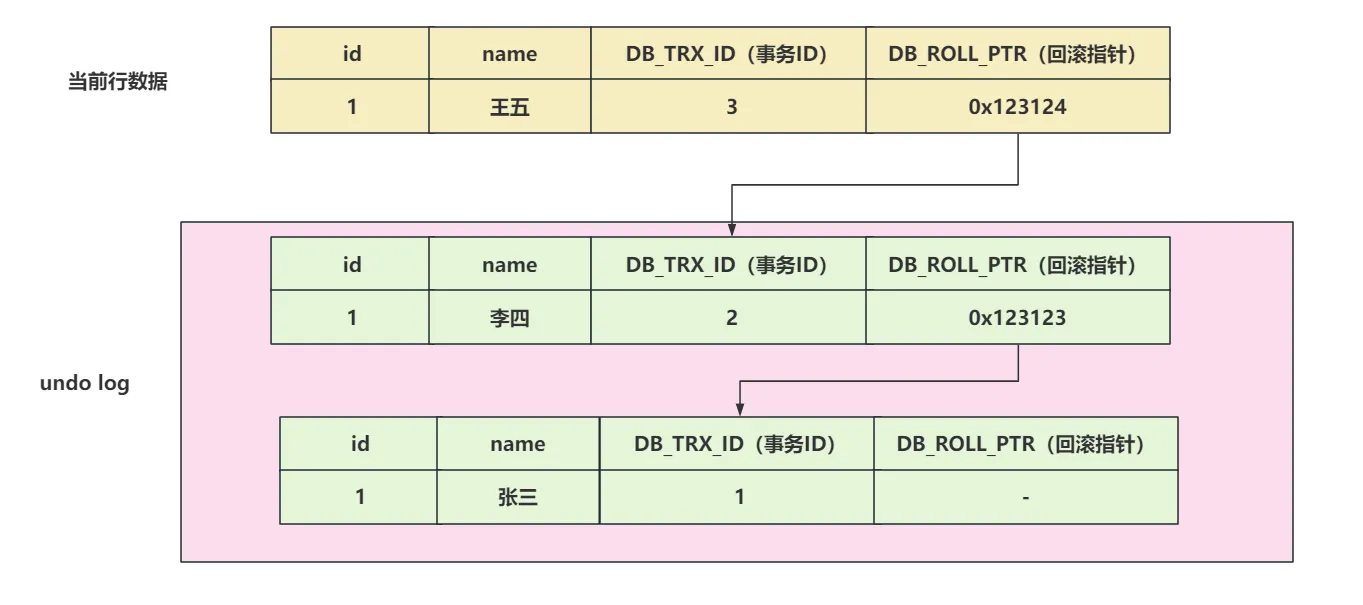
1、id < up_limit_id,直接可见。
2、RC隔离级别下,第二次查询会重新创建Read View,可以读取到刚刚提交事务的数据
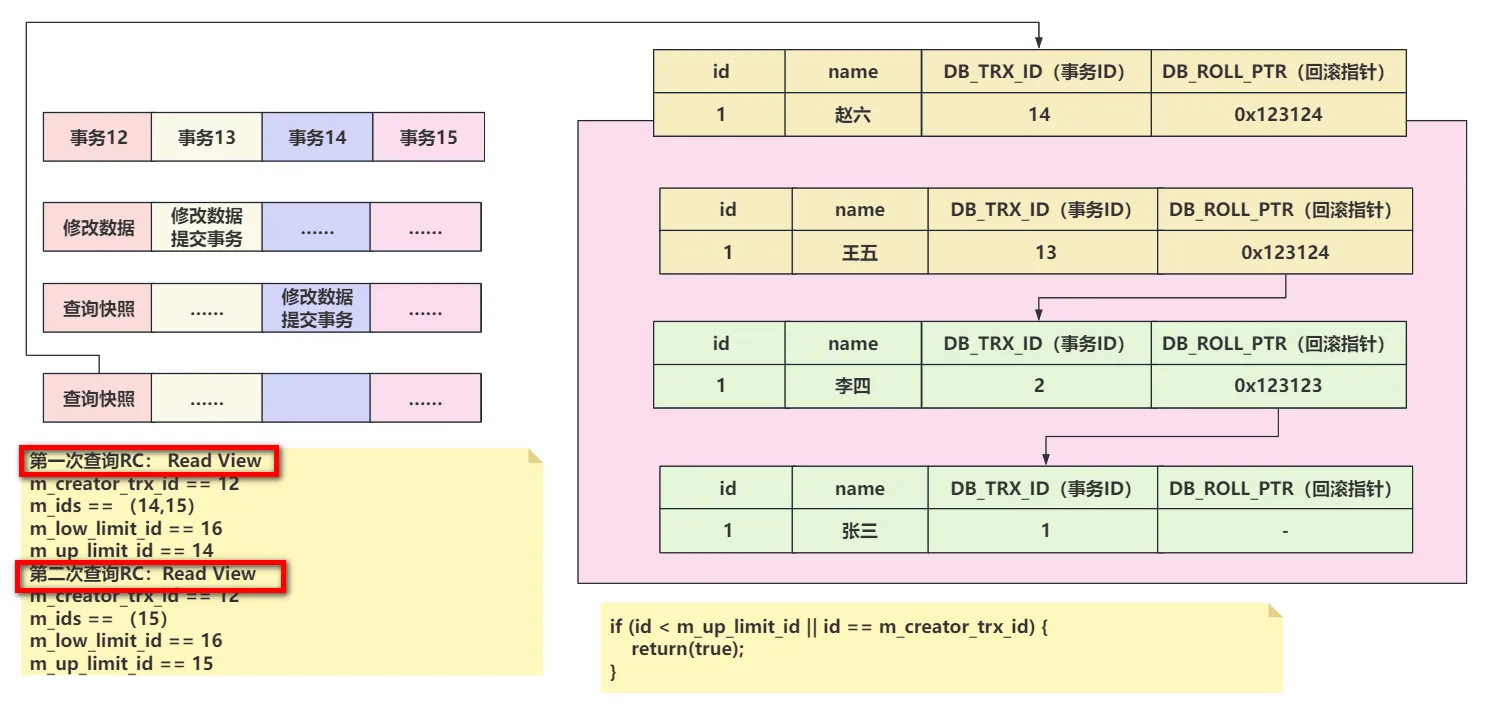
3、RR隔离级别下,第二次查询不会重新构建Read View,新数据不可见。
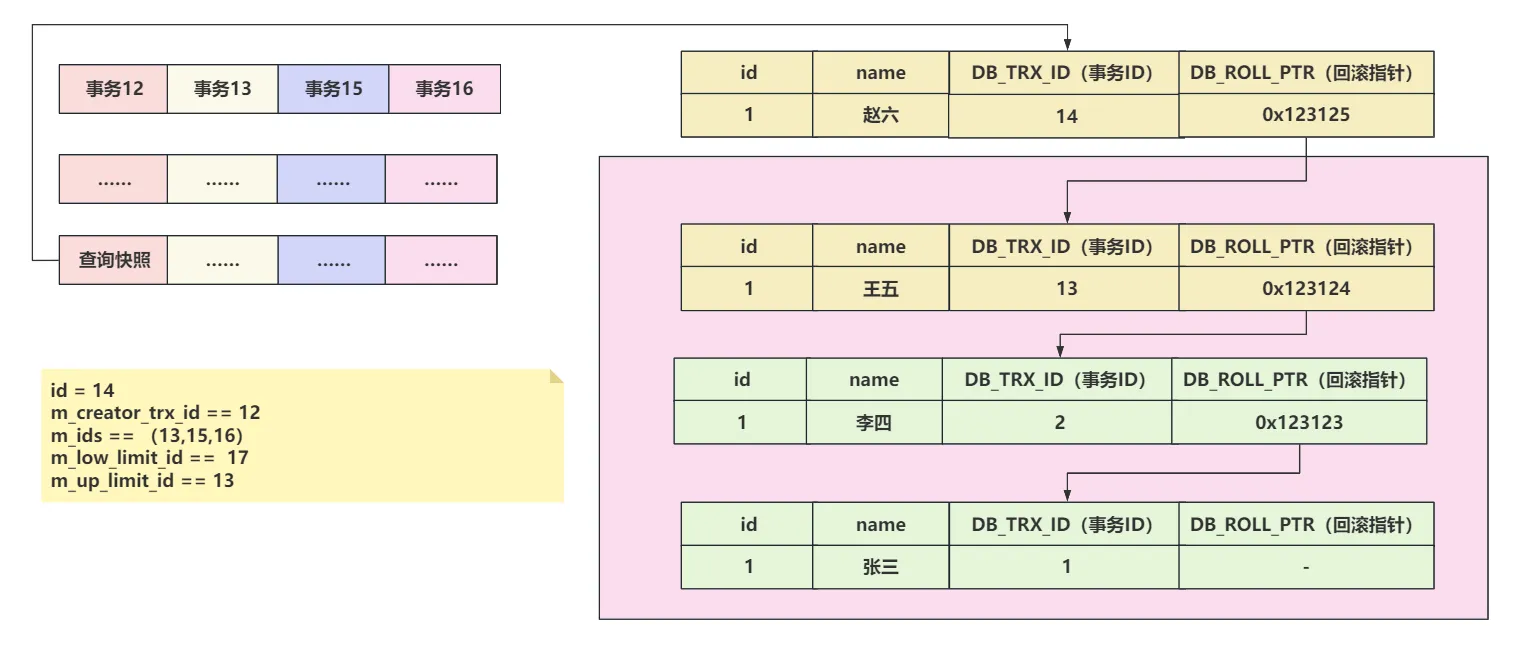
4、当前行事务ID不在活跃事务列表中。
总结一下
MVCC 的实现原理分为3部分
- 隐藏字段,核心是事务ID
- undo log,存储的快照记录
- read view,判断活跃事务的数据可见性
其实本质就是在每行数据提供了隐藏字段 - 事务ID,在并发事务进行 快照读 的时候产生的读视图 Read View,读视图快照中存储了当前活跃事务的ID,通过其事务ID来进行数据的可见性性判断,访问到 undo log 中对应事务ID版本的快照数据。
InnoDB 锁机制
数据是一种供许多用户共享访问的资源,如何保证数据库并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁的冲突也是影响数据库并发访问性能的一个重要因素。
相对其他数据库而言,MySQL的锁机制比较简单,其最 显著的特点是不同的存储引擎支持不同的锁机制。
比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
-
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
-
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
从上述特点可见,很难笼统地说哪种锁更好,只能就具体应用的特点来说哪种锁更合适!
仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
表锁
表级锁是 MySQL 锁中粒度最大的一种锁,表示当前的操作对整张数据表加锁,资源开销比行级锁少,不会出现死锁的情况,但是发生锁冲突的概率很大。
该锁的锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小,所以获取锁和释放锁的速度很快。由于表锁一次会将整张数据表锁定,因此可以很好地避免困扰我们的死锁问题。
InnoDB 支持表级锁,但是默认使用的是行级锁,而且只有在査询或者其他 SOL 语句通过索引操作时才会使用行级锁。
行锁
行级锁是 MySQL 锁中粒度最小的一种锁,因为锁的粒度最小,所以发生资源争抢的概率 也最小,并发性能最大,但是也会造成死锁,每次加锁和释放锁的开销也会变大。目前主要是ImnoDB 使用行级锁。
根据锁的使用方式又将锁分为 共享锁(S 锁或者读锁) 和 排他锁(X锁或者写锁)
实现方式
InnoDB行锁是通过给 索引 上的索引项加锁来实现的,InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
1、在不通过索引条件查询的时候,innodb使用的是表锁而不是行锁
sqlcreate table tab_no_index(id int,name varchar(10)) engine = innodb;
insert into tab_no_index values(1,'1'),(2,'2'),(3,'3'),(4,'4');
| session1 | session2 |
|---|---|
set autocommit=0select * from tab_no_index where id = 1; | set autocommit=0select * from tab_no_index where id =2; |
| select * from tab_no_index where id = 1 for update | select * from tab_no_index where id = 2 for update; |
session1只给一行加了排他锁,但是session2在请求其他行的排他锁的时候,会出现锁等待。原因是在没有索引的情况下,innodb只能使用表锁。
2、创建带索引的表进行条件查询,innodb使用的是行锁
sqlcreate table tab_with_index(id int,name varchar(10)) engine=innodb;
alter table tab_with_index add index id(id);
insert into tab_with_index values(1,'1'),(2,'2'),(3,'3'),(4,'4');
| session1 | session2 |
|---|---|
set autocommit=0select * from tab_with_indexwhere id = 1; | set autocommit=0select * from tab_with_indexwhere id =2 |
| select * from tab_with_indexwhere id = 1 for update | select * from tab_with_indexwhere id = 2 for update; |
3、由于mysql的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是依然无法访问到具体的数据
sqlinsert into tab_with_index values(1,'4');
| session1 | session2 |
|---|---|
set autocommit=0 | set autocommit=0 |
| select * from tab_with_index where id = 1 and name='1' for update | select * from tab_with_index where id = 1 and name='4' for update |
虽然session2访问的是和session1不同的记录,但是因为使用了相同的索引,所以需要等待锁 .
共享锁(S锁或读锁)
共享锁的具体逻辑为: 若事务A 对数据对象o加上S锁,则事务 A 可以读数据对象。但不能修改,其他事务只能再对数据对象o加S锁,而不能加X锁,直到事务 A释放数据对象o上的S锁。
这样保证了其他事务可以读数据对象 o,但在事务 A 释放数据对象o上的s锁之前,不能对数据对象o进行任何修改。
排他锁(X锁或写锁)
排他锁的具体逻辑为: 若事务 A对数据对象o加上X锁,事务A可以读数据对象o,也可以修改数据对象 o,其他事务则不能再对数据对象o加任何锁,直到事务A释放数据对象o上的锁。
这样保证了其他事务在事务 A释放数据对象o上的锁之前不能再读取和修改数据对象。
Mysql InnoDB 引擎默认的修改数据语句:update,delete,insert 都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果查询要加排他锁可以使用select …for update 语句,加共享锁可以使用 select … lock in share mode 语句。
加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过 for update 和 lock in share mode 锁的方式查询数据,但可以直接通过 select …from… 查询数据,因为普通查询没有任何锁机制。
间隙锁(Gap Lock)
间隙锁(Gap Lock)是 InnoDB 在提交时为了解决幻读问题而引入的锁机制,幻读问题的存在是因为新增或者更新操作时如果进行范围査询(加锁查询),就会出现数据不一致的问题,这时使用不同的行级锁已经过如办法满足要求了,需要对一定范围内的数据进行加锁,间隙锁就用于解决这类问题。
在可重复读的隔离级别下,数据库是通过行级锁和间隙锁共同组成的 next-key lock 来类现的。加锁规则具备以下特性:
- 加锁的基本单位是next-keylock,使用前开后闭原则。
- 数据插入过程中访问的对象会增加锁。
- 索引上的等值查询:给唯一索引加锁时,nextkeylock 升级为行级锁。
- 索引上的等值查询:向右遍历时,最后一个值不满足查询需求时,nextkeylock 退化为间隙锁。
- 唯一索引上的范围查询会访问到不满足条件的第一个值为止。
记录锁(Record Lock)
记录锁强制锁定索引记录(作用于唯一索引)。
如果执行 select * from userinfo where id=4 for update; 这条语句,就会在 id=4 的索引记录上加锁,以阻止其他事务插入、更新、删除 id=4 的这一行数据。
也就是说,当一个会话执行这条语句之后,其他会话执行下面这几种语句都会处于阻塞状态:
sqlselect * from userinfo where id=l for update;
delete from userinfo where id=4;
insert into userinfo values(4,'hh',18);
阻塞时间过长可能出抛出如下异常:
sqlERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
Next-Key Locking (临键锁)
InnoDB在 可重复读(REPEATABLE READ)隔离级别下使用这种锁组合:
- 间隙锁(Gap Lock):锁定索引记录之间的间隙
- 记录锁(Record Lock):锁定索引中的记录
临键锁(Next-Key Lock):前两者的组合,锁定记录及其前面的间隙,这种锁机制可以防止其他事务在查询范围内的间隙中插入新记录,从而避免幻读。
临键锁(Next-Key Lock)作用于非唯一索引,是记录锁与间隙锁的组合。临键锁的封锁范围既包含索引记录,又包含索引之前的区间。
临键锁的封锁范围既包含索引记录,又包含索引之前的区间,即(-∞,5](5,10](10,15](15,20](20,25](25,+∞)。
在事务中执行如下语句:
sqlUpdate userinfo set age=19 where id= 10;Select * from userinfo where id=10 FoR update;
这两个语句都会锁定(5,10]、(10,15]这两个区间,即 ImnoDB 会获取该记录行的临键锁,并同时获取该记录行下一个区间的间隙锁。
总结一下
InnoDB 中锁分为 表锁、行锁、间隙锁、记录锁、临键锁,其中行锁又分为共享锁和排他锁。
对于锁的应用,平常使用的 update,delete,insert 语句都是排他锁,select 不上锁,也可以通过 select ... for update 强行加上排他锁,或者使用 select … lock in share mode 加上共享锁。
为了防止幻读,在MVCC的基础上使用临键锁,也就是间隙锁+记录锁的组合,防止其他事务在查询范围内的间隙中插入新记录,从而避免幻读。
死锁
死锁是指两个或两个以上的事务在执行过程中因争抢锁资源而造成的互相等待的现象。
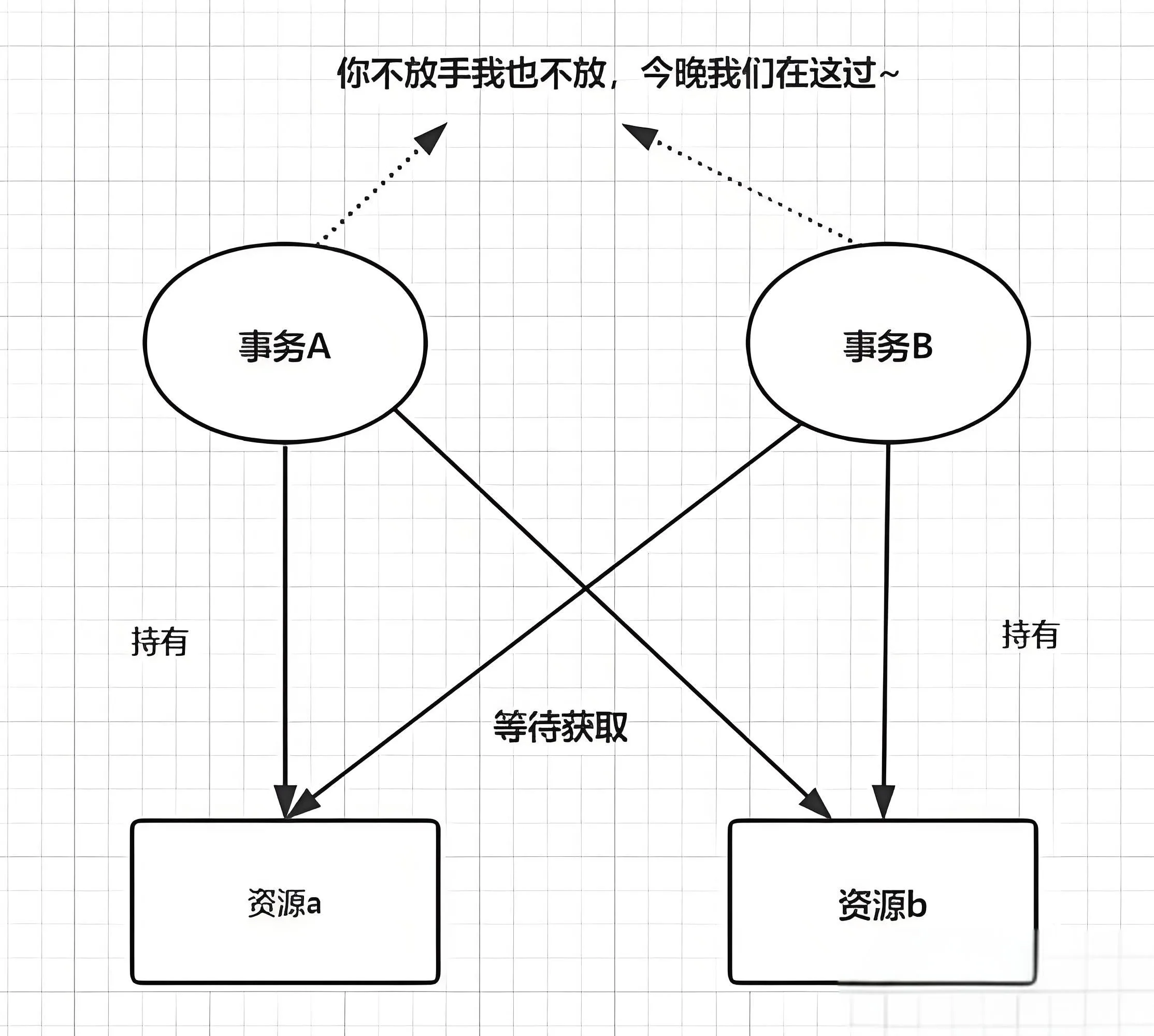
图中的两种情况即为死锁产生的常规情景。事务A等着事务B释放锁,事务B等着事务A释放锁,就会出现两个事务相互等待且一直等待下去。
避免死锁的方法有两种:
- 第一种是等待事务超时主动回滚;
- 第二种是进行死锁检查,主动回滚某条事务,让别的事务能继续走下去。
相关命令如下:
sql-- 查看正在被锁的事务
select *from information schema.innodb trx;
-- 通过如下命令杀死当前事务进程来释放锁
kill trx id;
并发事务带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多用户的并发操作,但与此同时,会带来以下问题:
脏读:
是指一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另一个事务也访问这个数据,然后读取到了这个数据。
不可重复读(主要针对修改)::
在一个事务内多次读取同一数据,当这个事务还没有结束时,另一个事务也访问该数据,那么在第一个事务中的两次读数据之间,由于第二个事务的修改可能导致第一个事务两次读到的数据是不一样的,因此称为不可重复读。
幻读(主要针对新增和删除):
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据。
第一个事务对一张数据表中的数据进行了修改,这种修改涉及表中的全部数据行。同时,第二个事务也修改这张表中的数据,这种修改是向表中插入了一行新数据。第一个事务的用户会发现表中还有未修改的数据行,就好像产生了幻觉一样。
不同的隔离级别可能会出现的问题
上述出现的问题都是数据库读一致性的问题,可以通过事务的隔离机制来进行保证。
数据库的事务隔离越严格,并发副作用就越小,但付出的代价也就越大,因为事务隔离本质上就是使事务在一定程度上串行化,需要根据具体的业务需求来决定使用哪种隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(read uncommitted) | ✅ | ✅ | ✅ |
| 提交读(read committed) | ✅ | ✅ | |
| 可重复读(repeatable read) | ✅ | ||
| 串行化( serializable) |
不同的数据库采用的隔离级别也会不一样。MySOL 默认的存储引擎 mnoDB 采用的是 可重复读。MySQL 采用了以乐观锁为基础的 MVCC 来解决幻读。
可以通过检查 InnoDB_row_lock 状态变量来分析系统上的行锁的争夺情况:
sqlmysql> show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 18702 |
| Innodb_row_lock_time_avg | 18702 |
| Innodb_row_lock_time_max | 18702 |
| Innodb_row_lock_waits | 1 |
+-------------------------------+-------+
--如果发现锁争用比较严重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高
如何解决可重复读级别隔离的幻读问题
按照锁的理论知识来说,如果执行 updale senin6o sance=18 whee id=1; 时肯定会给 id=1 这行数据添加一个X锁,当我们再执行 seledt* fom userinfo whcre id=1;时肯定处阻塞状态,但是为什么实际我们能够査询到数据呢?
这是因为在 InnoDB 中给每行增加了3个隐藏字段来实现 MVCC,其中有一个是事务的版本号,每开启一个新事务,事务的版本号的递增。
在可重复读级别下,select 读取的创建版本号小于或等于当前事务版本号,并且删除版本号为空或大于当前事务版本号的记录,这样可以保证在读取之前记录是存在的。
- 当执行 insent 命令时,当前事务的版本号保存至行的创建版本号;
- 当执行 update 命令修改一行数据时,以当前事务的版本号作为新行的创建版本号,同时将原记录行的删除版本号设置为当前事务版本号;
- 当执行 delete 命令时,将当前事务的版本号保存至删除行的版本号。
所以当A事务在操作时,在这期间其他事务对A事务相关的数据进行任何操作(增、刪、改), MySQL 都会保证 A 事务在开始事务和提交事务期间査询的数据永远是一致的。
MySQL通过 MVCC(多版本并发控制)和临键锁来解决幻读问题,通过间隙锁锁定索引中的记录及其前面的间隙,从而防止其他事务在查询范围内的间隙中插入新记录,避免幻读。以下是详细的解释和操作指南:
- 原理:MVCC通过为每条记录维护多个版本来实现并发控制。每个事务在开始时获取一个“快照”,事务只能看到在该快照之前提交的数据。
- 作用:在读已提交(Read Committed)和可重复读(Repeatable Read)隔离级别下,MVCC可以避免脏读和不可重复读,但在可重复读级别下,MVCC本身无法完全解决幻读。
间隙锁(Gap Lock)
- 原理:间隙锁是InnoDB特有的一种锁机制,用于锁定索引记录之间的“间隙”,防止其他事务在间隙中插入新数据。
- 作用:在可重复读(Repeatable Read)隔离级别下,InnoDB不仅会锁定查询条件匹配的记录,还会锁定记录之间的间隙,从而防止其他事务插入新数据,彻底解决幻读问题。
实际应用
- 当前读:通过使用SELECT ... FOR UPDATE语句,可以锁定特定的记录,并阻止其他事务在这些记录之间插入新数据。
- 快照读:在读取数据时,可以使用MVCC来获取数据的快照版本,这样即使其他事务在数据之间插入新数据,当前事务也能读取到一致的数据快照。
注意事项
- 在实际应用中,应该谨慎使用锁,以避免不必要的性能损失。
- 根据具体的业务需求和系统负载,选择合适的隔离级别和锁策略。
- 通过上述方法,MySQL能够有效地解决幻读问题,保证数据的一致性和完整性。
幻读真的被解决的了吗
通过MVCC + 临键锁确实可以解决大部分幻读问题。但某些情况下,还是会出现幻读的,详情查看 数据库 - Mysql 可重复读如何解决幻读?
MyISAM 锁机制
MySQL的表级锁有两种模式:
- 表共享读锁(Table Read Lock)
- 表独占写锁(Table Write Lock)
对MyISAM表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;对 MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作;MyISAM表的读操作与写操作之间,以及写操作之间是串行的!
建表语句:
sqlCREATE TABLE `mylock` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`NAME` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('1', 'a');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('2', 'b');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('3', 'c');
INSERT INTO `mylock` (`id`, `NAME`) VALUES ('4', 'd');
MyISAM写锁阻塞读的案例
当一个线程获得对一个表的写锁之后,只有持有锁的线程可以对表进行更新操作。其他线程的读写操作都会等待,直到锁释放为止。
| session1 | session2 |
|---|---|
| 获取表的write锁定 lock table mylock write; | |
| 当前session对表的查询,插入,更新操作都可以执行 select * from mylock; insert into mylock values(5,'e'); | 当前session对表的查询会被阻塞 select * from mylock; |
| 释放锁: unlock tables; | 当前session能够立刻执行,并返回对应结果 |
MyISAM读阻塞写的案例
一个session使用lock table给表加读锁,这个session可以锁定表中的记录,但更新和访问其他表都会提示错误,同时,另一个session可以查询表中的记录,但更新就会出现锁等待。
| session1 | session2 |
|---|---|
| 获得表的read锁定 lock table mylock read; | |
| 当前session可以查询该表记录: select * from mylock; | 当前session可以查询该表记录: select * from mylock; |
| 当前session不能查询没有锁定的表 select * from person Table 'person' was not locked with LOCK TABLES | 当前session可以查询或者更新未锁定的表 select * from mylock insert into person values(1,'zhangsan'); |
| 当前session插入或者更新表会提示错误 insert into mylock values(6,'f') Table 'mylock' was locked with a READ lock and can't be updated update mylock set name='aa' where id = 1; Table 'mylock' was locked with a READ lock and can't be updated | 当前session插入数据会等待获得锁 insert into mylock values(6,'f'); |
| 释放锁 unlock tables; | 获得锁,更新成功 |
注意:
MyISAM在执行查询语句之前,会自动给涉及的所有表加读锁,在执行更新操作前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此用户一般不需要使用命令来显式加锁,上例中的加锁时为了演示效果。
MyISAM的并发插入问题
MyISAM表的读和写是串行的,这是就总体而言的,在一定条件下,MyISAM也支持查询和插入操作的并发执行
| session1 | session2 |
|---|---|
| 获取表的read local锁定 lock table mylock read local | |
| 当前session不能对表进行更新或者插入操作 insert into mylock values(6,'f') Table 'mylock' was locked with a READ lock and can't be updated update mylock set name='aa' where id = 1; Table 'mylock' was locked with a READ lock and can't be updated | 其他session可以查询该表的记录 select* from mylock |
| 当前session不能查询没有锁定的表 select * from person Table 'person' was not locked with LOCK TABLES | 其他session可以进行插入操作,但是更新会阻塞 update mylock set name = 'aa' where id = 1; |
| 当前session不能访问其他session插入的记录; | |
| 释放锁资源:unlock tables | 当前session获取锁,更新操作完成 |
| 当前session可以查看其他session插入的记录 |
可以通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定争夺:
sqlmysql> show status like 'table%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Table_locks_immediate | 352 |
| Table_locks_waited | 2 |
+-----------------------+-------+
--如果Table_locks_waited的值比较高,则说明存在着较严重的表级锁争用情况。
总结
对于MyISAM的表锁,主要讨论了以下几点:
- 共享读锁(S)之间是兼容的,但共享读锁(S)与排他写锁(X)之间,以及排他写锁(X)之间是互斥的,也就是说读和写是串行的。
- 在一定条件下,MyISAM允许查询和插入并发执行,我们可以利用这一点来解决应用中对同一表查询和插入的锁争用问题。
- MyISAM默认的锁调度机制是写优先,这并不一定适合所有应用,用户可以通过设置LOW_PRIORITY_UPDATES参数,或在INSERT、UPDATE、DELETE语句中指定LOW_PRIORITY选项来调节读写锁的争用。
- 由于表锁的锁定粒度大,读写之间又是串行的,因此,如果更新操作较多,MyISAM表可能会出现严重的锁等待,可以考虑采用InnoDB表来减少锁冲突。
对于InnoDB表,本文主要讨论了以下几项内容:
- InnoDB的行锁是基于索引实现的,如果不通过索引访问数据,InnoDB会使用表锁。
- 在不同的隔离级别下,InnoDB的锁机制和一致性读策略不同。
在了解InnoDB锁特性后,用户可以通过设计和SQL调整等措施减少锁冲突和死锁,包括:
- 尽量使用较低的隔离级别; 精心设计索引,并尽量使用索引访问数据,使加锁更精确,从而减少锁冲突的机会;
- 选择合理的事务大小,小事务发生锁冲突的几率也更小;
- 给记录集显式加锁时,最好一次性请求足够级别的锁。比如要修改数据的话,最好直接申请排他锁,而不是先申请共享锁,修改时再请求排他锁,这样容易产生死锁;
- 不同的程序访问一组表时,应尽量约定以相同的顺序访问各表,对一个表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会;
- 尽量用相等条件访问数据,这样可以避免间隙锁对并发插入的影响; 不要申请超过实际需要的锁级别;除非必须,查询时不要显示加锁;
- 对于一些特定的事务,可以使用表锁来提高处理速度或减少死锁的可能。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!