
目录
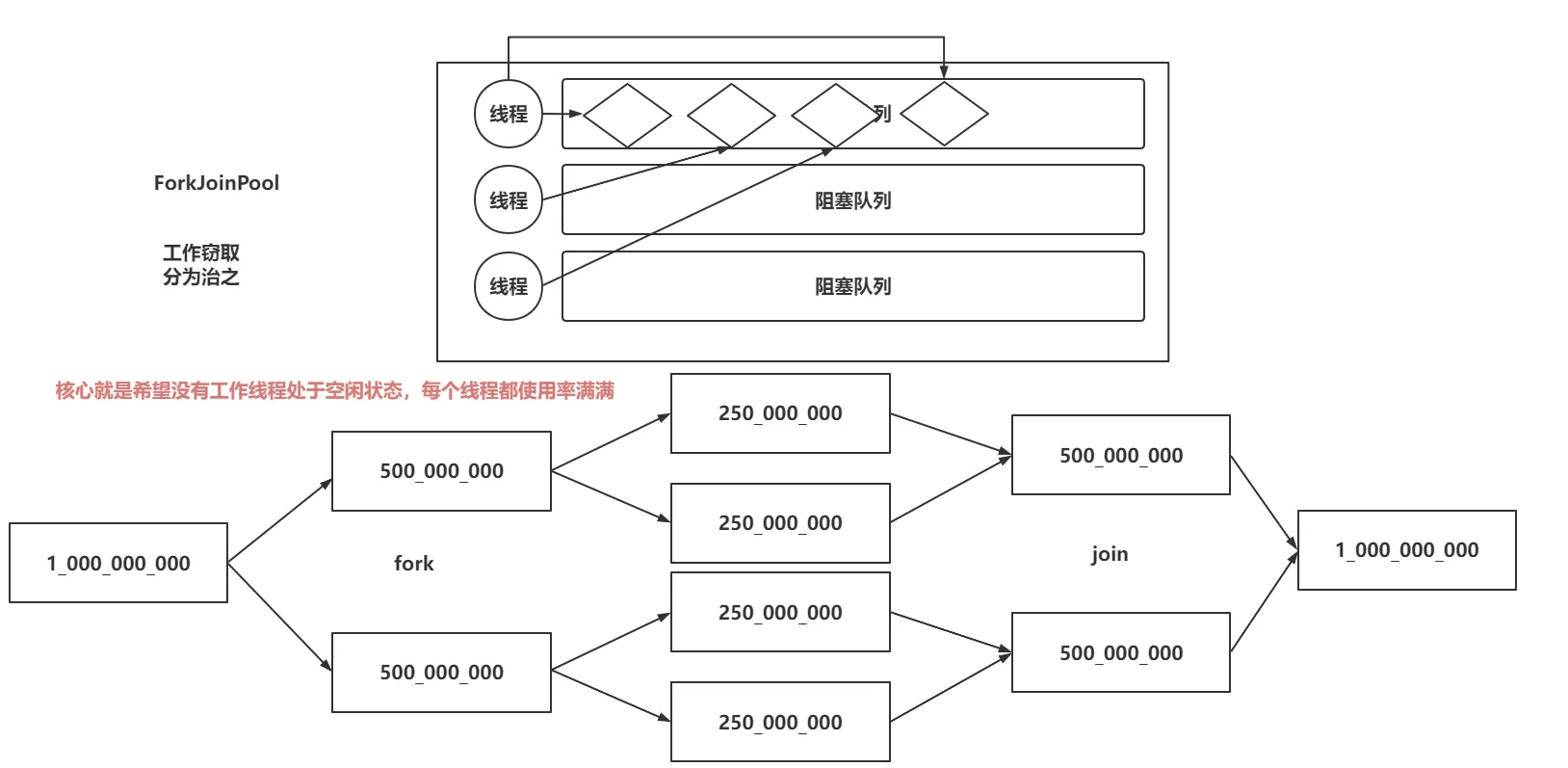
上文聊到 CompletableFuture 内置了 ForkJoinPool 线程池,我们推荐使用自定义线程池,那这两种有什么区别呢?接下来我将对 ForkJoinPool 架构揭秘包括工作窃取算法、核心组件和任务提交与执行过程,了解以下这个专为可分解任务设计的线程池。
ForkJoinPool
ForkJoinPool 是 Java 提供的一种特殊的线程池,专门用于处理可以分解成多个小任务的大任务。它的核心思想是“分而治之”(Divide and Conquer),即将一个复杂的问题拆分成多个小问题,并行解决后再合并结果,适用于处理那些可以被分解成多个子任务并且这些子任务的结果可以合并成最终结果的任务。
ForkJoinPool的工作原理
ForkJoinPool 是将一个大任务拆分成多个更小的任务,然后将小任务的结果合并起来,得到最终结果。
另外可以通过 工作窃取算法(Work-Stealing Algorithm)来提高线程池的效率。ForkJoinPool中内置了一个WorkQueue数组,每个线程都有自己的任务队列 WorkQueue,其中WorkQueue是一个双端队列,当前线程会从一端获取和添加任务,而其他线程会从队列的另一端来窃取任务,进一步降低了冲突,它会从其他线程的任务队列中“偷”任务来执行。这种机制可以减少线程空闲时间,提高资源利用率
ForkJoinPool的核心类和接口
-
ForkJoinPool:负责管理线程池和任务调度。默认情况下, JVM 提供了一个全局共享的线程池ForkJoinPool.commonPool() -
ForkJoinTask:表示一个可以被ForkJoinPool执行的任务。常见的子类包括RecursiveTask和RecursiveAction。 -
RecursiveTask<V>:表示有返回值的任务,需要实现compute()方法。 -
RecursiveAction:表示没有返回值的任务,同样需要实现compute()方法
javapublic class ForkJoinPool extends AbstractExecutorService {
volatile WorkQueue[] workQueues; // 任务队列数组
final ForkJoinWorkerThreadFactory factory; // 线程工厂
volatile int runState; // 运行状态
static final class WorkQueue {
ForkJoinTask<?>[] array; // 任务数组
int top; // LIFO压入位置
int base; // FIFO窃取位置
WorkQueue next; // 队列链表
}
}
构造函数
ForkJoinPool 提供了3个构造函数
java// 构造函数1
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
// 构造函数2
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
// 构造函数3
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(parallelism, factory, handler, asyncMode,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
- parallelism: 表示ForkJoinPool支持的最大并行度,最大不允许大于MAX_CAP。最小必须大于0
- factory:用于产生线程的工厂方法
- handler:用于异常处理的拒绝策略
- asyncMode:异步模式,如果为ture,则队列将采用FIFO_QUEUE,实现先进先出,反之则LIFO_QUEUE 实现后进先出
成员变量
java// Instance fields
volatile long ctl; // 线程池的主要控制字段
volatile int runState; // 线程池的运行状态,值为常量中对应的值
final int config; // 将并行度和mode放到了一个int中,便于后续通过位操作计算
int indexSeed; // 随机种子,通过前面的魔数来实现
volatile WorkQueue[] workQueues; // 组成workQueue的数组。是线程池的核心数据结构
final ForkJoinWorkerThreadFactory factory; // 产生线程的工厂方法
final UncaughtExceptionHandler ueh; // 每个worker出现异常之后的处理办法,类似于前面ThreadPoolExecutor的拒绝策略
final String workerNamePrefix; // 创建线程名称的前缀
volatile AtomicLong stealCounter; // 用于监控steal的计数器
任务队列设计
ForkJoinPool采用分布式双端队列结构。
索引规则:
- 索引:工作线程私有队列(LIFO操作)
- 索引:共享队列(外部提交任务,FIFO操作)
容量:初始容量为1 << 13(8192),动态扩容
java// 队列初始化源码(ForkJoinPool构造函数)
this.workQueues = new WorkQueue[n];
for (int i = 0; i < n; i += 2) {
workQueues[i] = new WorkQueue(this, null);
}
ForkJoinPool执行流程分析
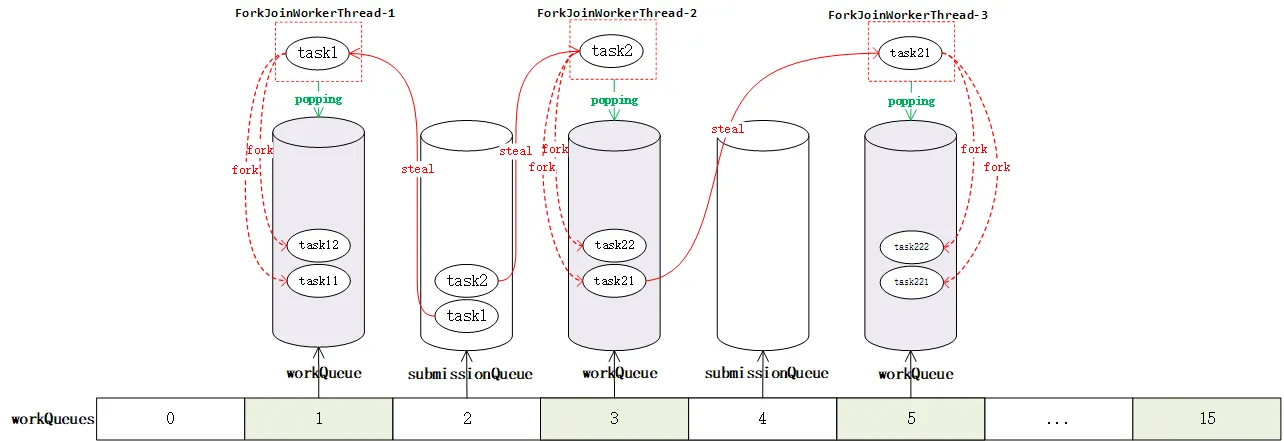
再了解了前面的变量之后,我们可以发现,ForkJoinPool的实际组成是,由一个WorkQueue的数组构成。但是这个数组比较特殊,在偶数位,存放外部调用提交的任务,如通过execute和submit等方法。这种队列称为SubmissionQueue。
而另外一种任务是前者在执行过程种通过fork方法产生的新任务。这种队列称为workQueue。
SubmissionQueue与WorkQueue的区别在于,WorkQueue的属性“final ForkJoinWorkerThread owner;”是有值的。也就是说,WorkQueue将有ForkJoinWorkerThread线程与之绑定。在运行过程中不断的从WorkQueue中获取任务。如果没有可执行的任务,则将从其他的SubmissionQueue和WorkQueue中窃取任务来执行。
前面学习过了工作窃取算法,实际上载WorkQueue上的ForkJoinWorkerThread就是一个窃取者,它从SubmissionQueue中或者去偷的WorkQueue中,按FIFO的方式窃取任务。之后也从自己的WorkQueue中安LIFO或者FIFO的方式执行任务。这取决于模式的设定。默认情况下是采用LIFO的方式在执行。组成如下图所示:
ForkJoinPool外部提交流程源码分析
externalPush
这是外部提交的唯一入口。
java/**
* 尝试将任务添加到提交者当前的队列中,此方法只处理大多数情况,实际上是根据随机数指定一个workQueues的槽位,如果这个位置存在WorkQueue,则加入队列,然后调用signalWork通知其他工作线程来窃取。反之,则通过externalSubmit处理。这只适用于提交队列存在的普通情况。更复杂的逻辑参考externalSubmit。
*
* @param task the task. Caller must ensure non-null.
*/
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws; WorkQueue q; int m;
//通过ThreadLocalRandom产生随机数
int r = ThreadLocalRandom.getProbe();
//线程池的状态
int rs = runState;
//如果ws已经完成初始化,且根据随机数定位的index存在workQueue,且cas的方式加锁成功
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
//此处先用随机数和wq的size取&,之后再取SQMASK,这些操作将多余的位的值去除
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
//cas的方式加锁 将q中位于QLOCK位置的内存的值如果为0,则改为1,采用cas的方式进行
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask<?>[] a; int am, n, s;
//判断q中的task数组是否为空,
if ((a = q.array) != null &&
//am为q的长度 这是个固定值,如果这个值大于n n就是目前队列中的元素,实际实这里是判断队列是否有空余的位置
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
//j实际上是计算添加到workQueue中的index
int j = ((am & s) << ASHIFT) + ABASE;
//将task通过cas的方式插入a的index为j的位置
U.putOrderedObject(a, j, task);
//将队列q的QTOP位置的内存加1,实际上就是将TOP增加1
U.putOrderedInt(q, QTOP, s + 1);
//以可见的方式将q的QLOCK改为0
U.putIntVolatile(q, QLOCK, 0);
//此处,如果队列中的任务小于等于1则通知其他worker来窃取。为什么当任务大于1的时候不通知。而且当没有任务的时候发通知岂不是没有意义?此处不太理解
if (n <= 1)
//这是个重点方法,通知其他worker来窃取
signalWork(ws, q);
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
externalSubmit(task);
}
实际上externalPush的逻辑只能处理简单的逻辑,对于其他复杂的逻辑,则需要通过externalPush提供,而这些简单的逻辑,实际上就是添加到任务队列。这个任务队列的索引一定是偶数:i = m & r & SQMASK。 这个计算过程,实际上由于SQMASK最后一位为0,因此计算的index的最后一位一定为0,这样导致这个值为偶数。也就是说,workQueues的偶数位存放的是外部提交的任务队列。之后提交成功之后,调用signalWork方法让其他的worker来窃取。
externalSubmit
这是提交过程中的分支逻辑处理的方法。
java/**
*externalPush的完整版本,处理哪些不常用的逻辑。如第一次push的时候进行初始化、此外如果索引队列为空或者被占用,那么创建一个新的任务队列。
*
* @param task the task. Caller must ensure non-null.
*/
private void externalSubmit(ForkJoinTask<?> task) {
//r是随机数,此处双重检测,确保r不为0
int r; // initialize caller's probe
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
//死循环
for (;;) {
WorkQueue[] ws; WorkQueue q; int rs, m, k;
//move默认为false
boolean move = false;
//如果runstate小于0 则线程池处于SHUTDOWN状态,配合进行终止
if ((rs = runState) < 0) {
//终止的方法 并抛出异常,拒绝该任务
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
//如果状态不为STARTED 说明此时线程池可用
else if ((rs & STARTED) == 0 || // initialize
//如果workQueues为null 或者其length小于1 则说明没用初始化
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
//对线程池以CAS的方式加锁,从RUNSTATE变为RSLOCK,如果不为RUNSTATE则自旋
rs = lockRunState();
try {
//如果状态为 RSIGNAL RSLOCK 说明加锁成功
if ((rs & STARTED) == 0) {
//用cas的方式初始化STEALCOUNTER
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
// create workQueues array with size a power of two
//创建workQueues的数组
//根据并行度计算得到config,此处确保p在SMASK范围内,即2个字节
int p = config & SMASK; // ensure at least 2 slots
//n判断p是否大于1,反之则默认按1处理
int n = (p > 1) ? p - 1 : 1;
//下列过程是找到大于n的最小的2的幂 这个过程之前在HashMap中演示过
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
//根据并行度计算得到了n,之后根据n确定workQueues的array的大小,这个数组的大小不会超过2^16
workQueues = new WorkQueue[n];
//将ns的值修改为STARTED
ns = STARTED;
}
} finally {
//最后将状态解锁 此时改为STARTED状态,这个计算过程有一点绕
unlockRunState(rs, (rs & ~RSLOCK) | ns);
}
//实际上这个分支只是创建了外层的workQueues数组,此时数组内的内容还是全部都是空的
}
//如果根据随机数计算出来的槽位不为空,即索引处的队列已经创建,这个地方是外层死循环再次进入的结果
//需要注意的是这个k的计算过程,SQMASK最低的位为0,这样就导致,无论随机数r怎么变化,得到的结果总是偶数。
else if ((q = ws[k = r & m & SQMASK]) != null) {
//如果这个槽位的workQueue未被锁定,则用cas的方式加锁 将其改为1
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
//拿到这个队列中的array
ForkJoinTask<?>[] a = q.array;
//s为top索引
int s = q.top;
//初始化submitted状态
boolean submitted = false; // initial submission or resizing
try { // locked version of push
//与上面的externalPush一致,此处push到队列中
//先判断 数组不为空且数组中有空余位置,能够容纳这个task
if ((a != null && a.length > s + 1 - q.base) ||
//或者通过初始化的双端队列的数组不为null
(a = q.growArray()) != null) {
//计算数组的index
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
//在索引index处插入task
U.putOrderedObject(a, j, task);
//将队列的QTOP加1
U.putOrderedInt(q, QTOP, s + 1);
//将提交成功状态改为true
submitted = true;
}
} finally {
//最终采用cas的方式进行解锁 将队列的锁定状态改为0
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
//如果submitted为true说明数据添加成功,此时调用其他worker来窃取
if (submitted) {
//调用窃取的方法
signalWork(ws, q);
//退出
return;
}
}
//move状态改为true
move = true; // move on failure
}
//如果状态不为RSLOCK 上面两个分支都判断过了,那么此处说明这个索引位置没有初始化
else if (((rs = runState) & RSLOCK) == 0) { // create new queue
/new一个新队列
q = new WorkQueue(this, null);
//hint 记录随机数
q.hint = r;
//计算config SHARED_QUEUE 将确保第一位为1 则这个计算出来的config是负数,这与初始化的方法是一致的
q.config = k | SHARED_QUEUE;
//将scan状态改为INCATIVE
q.scanState = INACTIVE;
//用cas的方式加锁
rs = lockRunState(); 将创建的workQueue push到workQueues的数组中
// publish index
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
//赋值
ws[k] = q; // else terminated
//解锁
unlockRunState(rs, rs & ~RSLOCK);
}
else
//将move改为true
move = true; // move if busy
if (move)
//重新计算r
r = ThreadLocalRandom.advanceProbe(r);
}
}
这个地方将产生的无owoner的workQueue放置在索引k的位置,需要注意的是k的计算过程,k= r & m & SQMASK。r是随机数,m是数组的长度,而SQMASK:
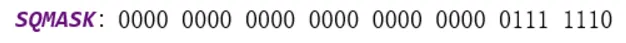
最后一位不为1,这就导致不管r如何变化,得到的k最后一位都不为1,这就构造了一个偶数k最后一位为0,k不可能是奇数。
signalWork
上述两个方法如果提交成功,那么调用signalWork,通知工作线程运行。
java/**
* 此处将激活worker Thread。如果工作线程太少则创建,反之则来进行窃取。
*
* @param ws the worker array to use to find signallees
* @param q a WorkQueue --if non-null, don't retry if now empty
*/
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c; int sp, i; WorkQueue v; Thread p;
//如果ctl为负数 ctl初始化的时候就会为负数 如果小于0 说明有任务需要处理
while ((c = ctl) < 0L) { // too few active
//c为long,强转int 32位的高位都丢弃,此时如果没有修改过ctl那么低位一定为0 可参考前面ctl的推算过程,所以此处sp 为0 sp为0则说明每月空闲的worker
if ((sp = (int)c) == 0) { // no idle workers
//还是拿c与ADD_WORKER取& 如果不为0 则说明worker太少,需要新增worker
if ((c & ADD_WORKER) != 0L) // too few workers
//通过tryAddWorker 新增worker
tryAddWorker(c);
break;
}
//再次缺认ws有没有被初始化 如果没有 退出
if (ws == null) // unstarted/terminated
break;
//如果ws的length小于sp的最低位 退出
if (ws.length <= (i = sp & SMASK)) // terminated
break;
//如果index处为空 退出
if ((v = ws[i]) == null) // terminating
break;
//将sp的低32位取出
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
//计算用sp减去 scanState
int d = sp - v.scanState; // screen CAS
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
//采用cas的方式修改ctl 实际上就是加锁 由于ctl的修改可能会导致while循环退出
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // activate v
//如果p被park wait中
if ((p = v.parker) != null)
//将worker唤醒
U.unpark(p);
//退出
break;
}
//如果此队列为空或者没有task 也退出
if (q != null && q.base == q.top) // no more work
break;
}
}
可以看到,实际上signalWork就做了两件事情,第一,判断worker是否充足,如果不够,则创建新的worker。第二,判断worker的状态是否被park了,如果park则用unpark唤醒。这样worker就可以取scan其他队列进行窃取了。
tryAddWorker
此方法是在worker不足的时候,添加一个worker来执行的具体类。
java/**
* 尝试新增一个worker,然后增加ctl中记录的worker的数量
*
* @param c incoming ctl value, with total count negative and no
* idle workers. On CAS failure, c is refreshed and retried if
* this holds (otherwise, a new worker is not needed).
*/
private void tryAddWorker(long c) {
//传入的c为外层调用方法的ctl add标记为false
boolean add = false;
do {
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
//如果此时ctl与外层传入的ctl相等 说明没有被修改
if (ctl == c) {
int rs, stop; // check if terminating
//用cas的方式加锁
if ((stop = (rs = lockRunState()) & STOP) == 0)
//增加ctl的数量,如果成功 add为ture
add = U.compareAndSwapLong(this, CTL, c, nc);
//解锁
unlockRunState(rs, rs & ~RSLOCK);
//如果stop不为0 则说明线程池停止 退出
if (stop != 0)
break;
//如果前面增加ctl中的数量成功,那么此处开始创建worker
if (add) {
createWorker();
break;
}
}
//这个while循环, 前半部分与ADD_WORKER取并,最终只会保留第48位,这个位置为1,同时c的低32为为0,
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
实际上这个类中,只是做了一些准备过程,增加count,以及加锁判断,最终还是通过createWorker来进行。
createWorker
创建worker的具体方法。
java// Creating, registering and deregistering workers
/**
* 创建并启动一个worker,因为前面已经做了增加count,如果此处出现异常,创建worker不成功,则在deregisterWorker中会判断如果ex不为空,且当前为创建状态的话,会重新进入tryAddWorker方法。
*
* @return true if successful
*/
private boolean createWorker() {
//创建线程的工厂方法
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
//如果工厂方法不为空,则用这个工厂方法创建线程,之后再启动线程,此时newThread将与workQueue绑定
if (fac != null && (wt = fac.newThread(this)) != null) {
wt.start();
return true;
}
//如果创建失败,出现了异常 则ex变量有值
} catch (Throwable rex) {
ex = rex;
}
deregisterWorker(wt, ex);
return false;
}
此方法只是创建了一个ForkJoinThread,实际上worker还是没有创建。实际上这个创建过程是再newThread(this)中来进行的。
javaForkJoinWorkerThread(ForkJoinPool pool, ThreadGroup threadGroup,
AccessControlContext acc) {
super(threadGroup, null, "aForkJoinWorkerThread");
U.putOrderedObject(this, INHERITEDACCESSCONTROLCONTEXT, acc);
eraseThreadLocals(); // clear before registering
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
再线程创建成功之后调用registerWorker与之绑定。如果线程创建失败或者出现异常就要调用deregisterWorker对count进行清理或者解除绑定。
registerWorker
实际上是这个方法,完成worker的创建和绑定。
java/**
* 创建线程,并建立线程与workQueue的关系,此处只会在workQueues数组的奇数位操作
*
* @param wt the worker thread
* @return the worker's queue
*/
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
//将线程设置为守护线程
wt.setDaemon(true); // configure thread
//如果没有handler则抛出异常
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
//创建一个workQueue,此时owoner为当前输入的ForkJoinThread
WorkQueue w = new WorkQueue(this, wt);
//定义i为0
int i = 0; // assign a pool index
//定义mode
int mode = config & MODE_MASK;
//加锁
int rs = lockRunState();
try {
WorkQueue[] ws; int n; // skip if no array
//如果workQueues存在,且长度大于0
if ((ws = workQueues) != null && (n = ws.length) > 0) {
//通过魔数计算
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
//m为n-1,而n为数组的初始化长度,第一次创建的时候,n=16,那么m为15
int m = n - 1;
//将s左移然后最后一位补上1,之后与奇数m求并集,那么得到的结果必然是奇数
i = ((s << 1) | 1) & m; // odd-numbered indices
//判断i位置是否为空 如果为空,出现了碰撞,则计算步长向后移动 这个步长一定是偶数
if (ws[i] != null) { // collision
int probes = 0; // step by approx half n
//最小步长为2 n是数组长度,比为偶数,那么如果n小于等于4,则步长为2,反之,则将n右移,将偶数最后一位的0清除,之后再和EVENMASK求并,这样就相当于将原来的长度缩小2倍,并确保是偶数。之后再加上2。那么假定n为16的话,此处计算的step就为10
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
//之后再通过while循环,继续判断增加步长之后是否碰撞,如果碰撞,则继续增加步长
while (ws[i = (i + step) & m] != null) {
//如果还是碰撞,且probes增加1之后大于长度n,则会触发扩容,workQueues会扩大2倍 这个probes感觉意义不大
if (++probes >= n) {
workQueues = ws = Arrays.copyOf(ws, n <<= 1);
m = n - 1;
//将probes置为0
probes = 0;
}
}
}
//设置随机数seed
w.hint = s; // use as random seed
//修改config
w.config = i | mode;
//修改scanState为i
w.scanState = i; // publication fence
//将w设置到i处
ws[i] = w;
}
} finally {
//cas的方式进行解锁
unlockRunState(rs, rs & ~RSLOCK);
}
//此处设置线程name
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
再registerWorker中,对工作线程和workQueue进行绑定,并设置到workQueues的奇数索引处。注意这里计算得到奇数索引的算法。 //将s左移然后最后一位补上1,之后与奇数m求并集,那么得到的结果必然是奇数。 i = ((s << 1) | 1) & m; 这个位操作,是我们非常值得注意的地方。
deregisterWorker
如果线程创建没有成功,那么count需要回收。以及进行一些清理工作。
java/**
*此方法的主要目的是在创建worker或者启动worker失败之后的回调方法,此时将之前的ctl中增加的count减去。
*
* @param wt the worker thread, or null if construction failed
* @param ex the exception causing failure, or null if none
*/
final void deregisterWorker(ForkJoinWorkerThread wt, Throwable ex) {
WorkQueue w = null;
//如果workQueue和thread不为空
if (wt != null && (w = wt.workQueue) != null) {
WorkQueue[] ws; // remove index from array
//根据config计算index
int idx = w.config & SMASK;
//加锁
int rs = lockRunState();
如果ws不为空且length大于idx同时idx处的worker就是workerQueue 则将该idx处的worker移除
if ((ws = workQueues) != null && ws.length > idx && ws[idx] == w)
ws[idx] = null;
//解锁 修改rs状态
unlockRunState(rs, rs & ~RSLOCK);
}
//后续对count减少
long c; // decrement counts
//死循环 cas的方式将ctl修改
do {} while (!U.compareAndSwapLong
(this, CTL, c = ctl, ((AC_MASK & (c - AC_UNIT)) |
(TC_MASK & (c - TC_UNIT)) |
(SP_MASK & c))));
//入果workQueue不为空 将其中的task取消
if (w != null) {
w.qlock = -1; // ensure set
w.transferStealCount(this);
w.cancelAll(); // cancel remaining tasks
}
//死循环 如果为停止状态则配合停止
for (;;) { // possibly replace
WorkQueue[] ws; int m, sp;
if (tryTerminate(false, false) || w == null || w.array == null ||
(runState & STOP) != 0 || (ws = workQueues) == null ||
(m = ws.length - 1) < 0) // already terminating
break;
if ((sp = (int)(c = ctl)) != 0) { // wake up replacement
if (tryRelease(c, ws[sp & m], AC_UNIT))
break;
}
else if (ex != null && (c & ADD_WORKER) != 0L) {
tryAddWorker(c); // create replacement
break;
}
else // don't need replacement
break;
}
//异常处理
if (ex == null) // help clean on way out
ForkJoinTask.helpExpungeStaleExceptions();
else // rethrow
ForkJoinTask.rethrow(ex);
}
提交过程总结
上述代码调用的过程,我们可以形象的用如下图进行表示:

最开始,workQueues是null状态。在第一次执行的时候,externalSubmit方法中会初始化这个数组。
在这之后,还是在externalSubmit方法的for循环中,完成对任务队列的创建,将任务队列创建在偶数索引处。之后将任务写入这个队列:
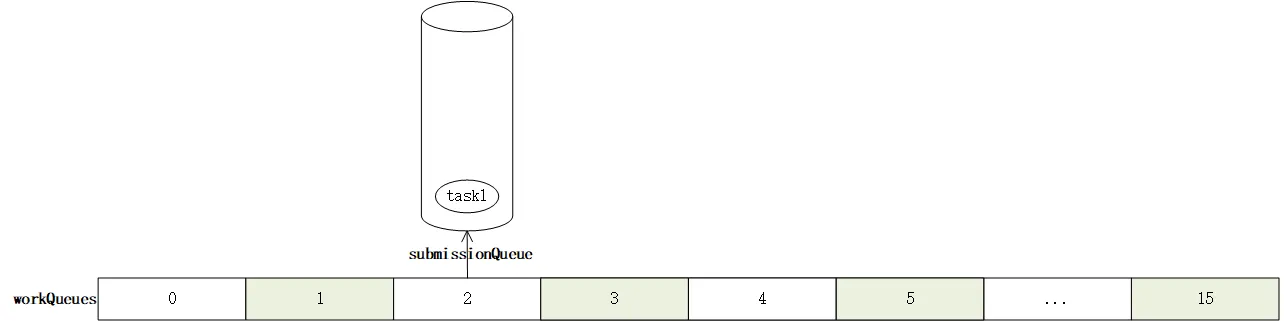
此后,任务添加完成,但是没有工作队列进行工作。因此在这之后调用signalWork,通知工作队列开始干活。但是在这个方法执行的过程中,由于工作队列并不存在,没有worker,所以调用tryAddWorker开始创建worker。在createWorker会创建一个worker线程:
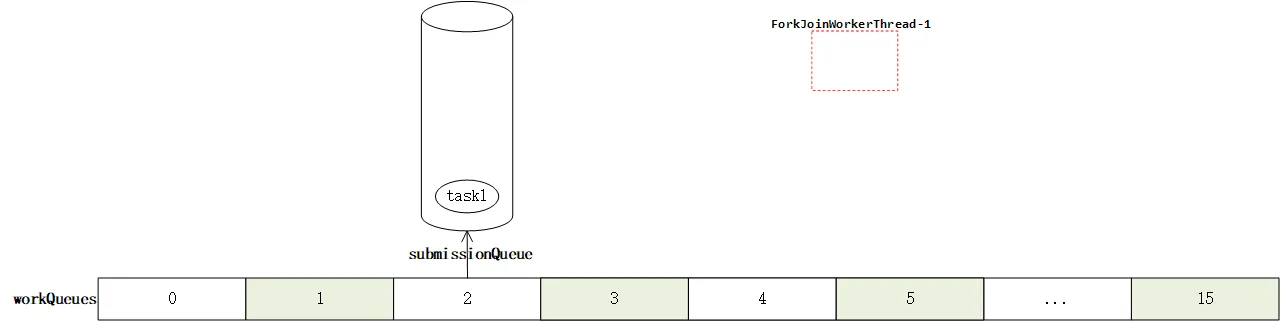
但是workQueue还没创建。这是在newthread之后,通过registerWorker创建的,在registerWorker方法中,会在奇数位创建一个workQueue,并将此前创建的线程与之绑定。这样一个worker就成功创建了。
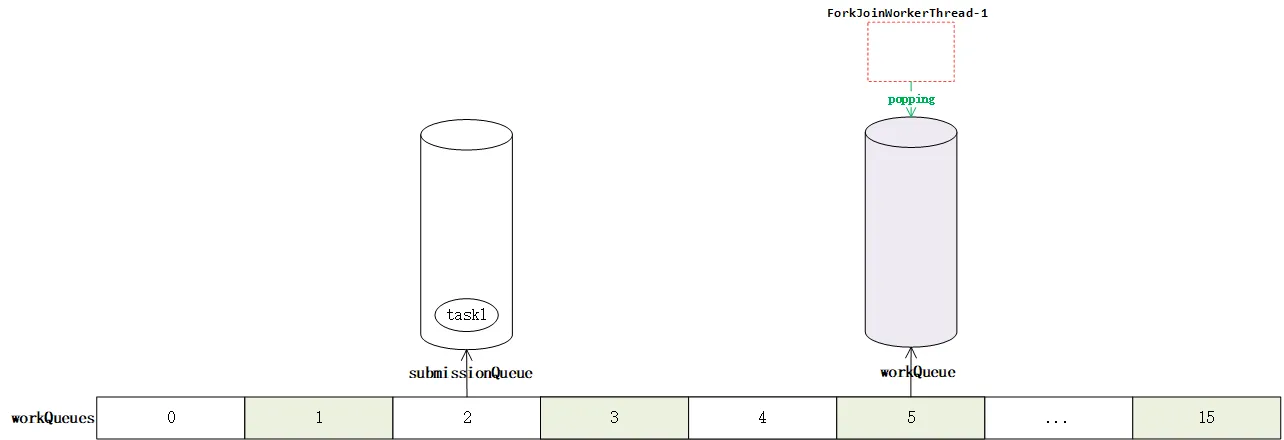
这样就完成了worker创建的全过程。
workQueue的工作过程源码分析
在workQueue创建完成之后,下一步,这些线程的run方法调用后被启动。之后就进入了worker线程的生命周期了。实际上run方方法如下:
javapublic void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart();
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);
}
}
}
}
重点执行的式runWorker,此时一旦出错,可以调用deregisterWorker方法进行清理。下面来看看runWorker的详细过程。
runWorker
这是worker工作线程的执行方法。通过死循环,不断scan是否有任务,之后窃取这个任务进行执行。
java/**
* 通过调用线程的run方法,此时开始最外层的runWorker
*/
final void runWorker(WorkQueue w) {
//初始化队列,这个方法会根据任务进行判断是否需要扩容
w.growArray(); // allocate queue
//hint是采用的魔数的方式增加
int seed = w.hint; // initially holds randomization hint
//如果seed为0 则使用1
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
//死循环
for (ForkJoinTask<?> t;;) {
//调用scan方法 对经过魔数计算的r 之后开始进行窃取过程 如果能够窃取 则task不为空
if ((t = scan(w, r)) != null)
//运行窃取之后的task
w.runTask(t);
//反之则当前线程进行等待
else if (!awaitWork(w, r))
break;
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}
scan
通过scan方法从其他队列获得任务。
java/**
* 通过scan方法进行任务窃取,扫描从一个随机位置开始,如果出现竞争则通过魔数继续随机移动,反之则线性移动,直到所有队列上的相同校验连续两次出现为空,则说明没有任何任务可以窃取,因此worker会停止窃取,之后重新扫描,如果找到任务则重新激活,否则返回null,扫描工作应该尽可能少的占用内存,以减少对其他扫描线程的干扰。
*
* @param w the worker (via its WorkQueue)
* @param r a random seed
* @return a task, or null if none found
*/
private ForkJoinTask<?> scan(WorkQueue w, int r) {
WorkQueue[] ws; int m;
//如果workQueues不为空且长度大于1,当前workQueue不为空
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
//ss为扫描状态
int ss = w.scanState; // initially non-negative
//for循环 这是个死循环 origin将r与m求并,将多余位去除。然后赋值给k
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0;;) {
WorkQueue q; ForkJoinTask<?>[] a; ForkJoinTask<?> t;
int b, n; long c;
//如果k处不为空
if ((q = ws[k]) != null) {
//如果task大于0
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) { // non-empty
//计算i
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
//得到i处的task
if ((t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i))) != null &&
q.base == b) {
//如果扫描状态大于0
if (ss >= 0) {
//更改a中i的值为空 也就是此处将任务窃取走了
if (U.compareAndSwapObject(a, i, t, null)) {
//将底部的指针加1
q.base = b + 1;
//如果n小于-1 则通知工作线程工作
if (n < -1) // signal others
signalWork(ws, q);
//将窃取的task返回
return t;
}
}
//如果 scan状态小于0 则调用tryRelease方法唤醒哪些wait的worker
else if (oldSum == 0 && // try to activate
w.scanState < 0)
//调用tryRelease方法 后续详细介绍
tryRelease(c = ctl, ws[m & (int)c], AC_UNIT);
}
//如果ss小于0
if (ss < 0) // refresh
//更改ss
ss = w.scanState;
r ^= r << 1; r ^= r >>> 3; r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;
}
//此处判断k,k在此通过+1的方式完成对原有workQueues的遍历
if ((k = (k + 1) & m) == origin) { // continue until stable
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
oldSum == (oldSum = checkSum)) {
if (ss < 0 || w.qlock < 0) // already inactive
break;
int ns = ss | INACTIVE; // try to inactivate
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));
w.stackPred = (int)c; // hold prev stack top
U.putInt(w, QSCANSTATE, ns);
if (U.compareAndSwapLong(this, CTL, c, nc))
ss = ns;
else
w.scanState = ss; // back out
}
checkSum = 0;
}
}
}
return null;
}
此方法最大的特点就是,根据随机数计算一个k,然后根据k去遍历workQueues,之后看看这个位置是否有数据,如果不为空,则检查checkSum,根据checkSum的状态缺认是否从这个队列中取数据。按之前约定的FIFO或者LIFO取数。这意味着,工作队列对窃取和是否获得本队列中的任务之间并没有优先级,而是根据随机数得到的index,之后对数组进行遍历。
tryRelease
对于执行完成的worker,则需要进行释放。
java/**
* 如果worker处于空闲worker Stack的workQueue的顶部。则发信号对其进行释放。
*
* @param c incoming ctl value
* @param v if non-null, a worker
* @param inc the increment to active count (zero when compensating)
* @return true if successful
*/
private boolean tryRelease(long c, WorkQueue v, long inc) {
//sp取c的低位,计算vs
int sp = (int)c, vs = (sp + SS_SEQ) & ~INACTIVE; Thread p;
//如果v不为空 且v的sancState为sp
if (v != null && v.scanState == sp) { // v is at top of stack
//计算nc
long nc = (UC_MASK & (c + inc)) | (SP_MASK & v.stackPred);
//采用cas的方式 将ctl改为nc
if (U.compareAndSwapLong(this, CTL, c, nc)) {
//修改scanState的状态
v.scanState = vs;
//如果此时这线程为park状态,则调用unpark
if ((p = v.parker) != null)
U.unpark(p);
return true;
}
}
return false;
}
awaitWork
如果上述scan不到任务呢?也就是说,scan方法没有拿到task,则会调用awaitWork。将当前的线程进行阻塞。
java/**
*如果不能窃取到任务,那么就将worker阻塞。如果停用导致线程池处于静止状态,则检查是否要关闭,如果这不是唯一的工作线程,则等待给定的持续时间,达到超时时间后,如果ctl没有更改,则将这个worker终止,之后唤醒另外一个其他的worker对这个过程进行重复。
*
* @param w the calling worker
* @param r a random seed (for spins)
* @return false if the worker should terminate
*/
private boolean awaitWork(WorkQueue w, int r) {
//如果w不为空切w的qlock小于0 则直接返回false
if (w == null || w.qlock < 0) // w is terminating
return false;
//for循环,这是个死循环,定义pred
for (int pred = w.stackPred, spins = SPINS, ss;;) {
//如果ss大于0 则返回
if ((ss = w.scanState) >= 0)
break;
//如果spins大于0
else if (spins > 0) {
//计算r
r ^= r << 6; r ^= r >>> 21; r ^= r << 7;
//如果r大于0 且spins为0
if (r >= 0 && --spins == 0) { // randomize spins
WorkQueue v; WorkQueue[] ws; int s, j; AtomicLong sc;
//如果pred不为0 且ws不为空
if (pred != 0 && (ws = workQueues) != null &&
//j<ws.length
(j = pred & SMASK) < ws.length &&
//j位置处不为空
(v = ws[j]) != null && // see if pred parking
//并且没有park
(v.parker == null || v.scanState >= 0))
//继续在for循环中自旋
spins = SPINS; // continue spinning
}
}
//如果qlock小于0 返回false
else if (w.qlock < 0) // recheck after spins
return false;
//如果被中断
else if (!Thread.interrupted()) {
long c, prevctl, parkTime, deadline;
int ac = (int)((c = ctl) >> AC_SHIFT) + (config & SMASK);
//如果线程池停止
if ((ac <= 0 && tryTerminate(false, false)) ||
(runState & STOP) != 0) // pool terminating
return false;
//最后的等待 获取不到任务 此时采用超时等待 park的方式进行
if (ac <= 0 && ss == (int)c) { // is last waiter
prevctl = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & pred);
int t = (short)(c >>> TC_SHIFT); // shrink excess spares
if (t > 2 && U.compareAndSwapLong(this, CTL, c, prevctl))
return false; // else use timed wait
parkTime = IDLE_TIMEOUT * ((t >= 0) ? 1 : 1 - t);
deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP;
}
else
prevctl = parkTime = deadline = 0L;
//获取线程
Thread wt = Thread.currentThread();
//设置PARKBLOCKER
U.putObject(wt, PARKBLOCKER, this); // emulate LockSupport
w.parker = wt;
//调用park方法
if (w.scanState < 0 && ctl == c) // recheck before park
U.park(false, parkTime);
U.putOrderedObject(w, QPARKER, null);
U.putObject(wt, PARKBLOCKER, null);
//如果scanState大于0 退出
if (w.scanState >= 0)
break;
//如果已经达到deadline的时间 则返回false
if (parkTime != 0L && ctl == c &&
deadline - System.nanoTime() <= 0L &&
U.compareAndSwapLong(this, CTL, c, prevctl))
return false; // shrink pool
}
}
return true;
}
上述这些方法,如果返回了false,则会导致外层的阻塞不能阻塞住,在runWorker方法中,会退出循环,这个线程就会退出。只有返回了true,那么这个线程就会一直运行,获得任务,循环。
工作过程总结
当workQueue上的thread启动之后,这个线程就会调用runWorker方法。之后再runWorker方法中有一个死循环,不断的通过scan方法去扫描任务,实际上就是执行窃取过程。如下图所示,这样通过遍历外层workQueues的方式将会从任务队列中窃取任务进行执行。
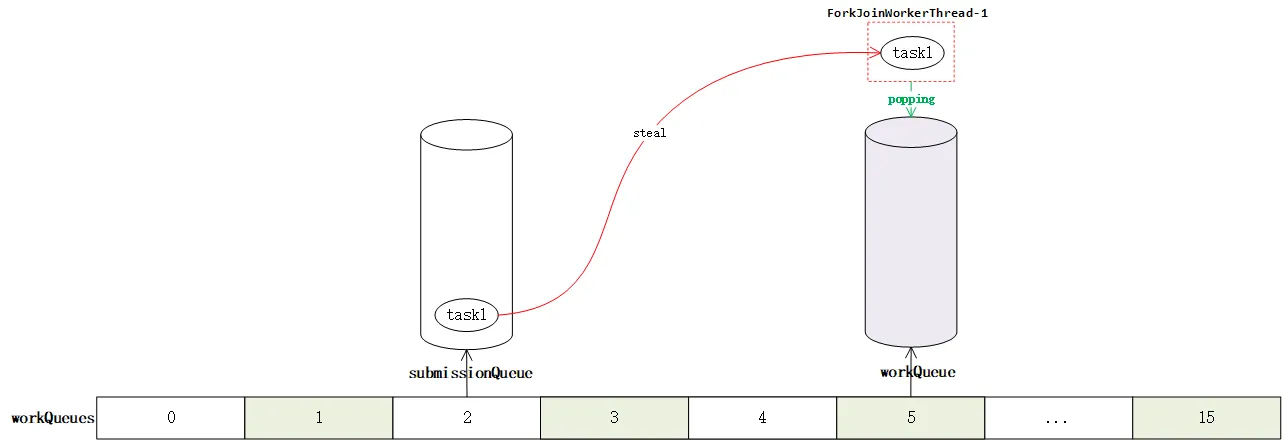
当执行之后,会通过fork产生新的任务,将这些任务任务添加到工作队列中去。其他线程继续scan,执行。这个过程不断循环,直到任务全部都执行完成,这样就完成了整个计算过程。
ForkJoinPool的使用场景和调优
ForkJoinPool 适用于需要高效管理大量细粒度任务的场景,尤其是在计算密集型任务中表现优异。通过递归拆分任务和合并结果,它可以充分利用多核处理器的性能,提高程序的并发能力,它特别适用于递归任务,如排序算法(快速排序、归并排序)、文件搜索、大数据计算等
使用调优:
| 参数 | 默认值 | 优化建议 |
|---|---|---|
| 并行度 (parallelism) | Runtime.availableProcessors() | 计算密集型:=CPU核心数 |
| 异步模式 (asyncMode) | false | true启用FIFO模式 |
| 任务阈值 (THRESHOLD) | 无默认值 | 经验值:5000-50,000 |
| 队列初始大小 | 1 << 13 (8192) | 大型任务可设为1 << 16 |
代码示例
javaclass SumTask extends RecursiveTask<Long> {
private final int[] array;
private final int start, end;
private static final int THRESHOLD = 1000;
SumTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 达到阈值直接计算
if (end - start <= THRESHOLD) {
long sum = 0;
for (int i = start; i < end; i++) sum += array[i];
return sum;
}
// 拆分任务
int mid = (start + end) >>> 1;
SumTask left = new SumTask(array, start, mid);
SumTask right = new SumTask(array, mid, end);
left.fork(); // 异步执行左半部分
long rightResult = right.compute(); // 同步计算右半部分
long leftResult = left.join(); // 获取左半结果
return leftResult + rightResult;
}
}
// 使用
ForkJoinPool pool = new ForkJoinPool();
long result = pool.invoke(new SumTask(largeArray, 0, largeArray.length));
总结
ForkJoinPool 作为Java并发计算的基石,其核心设计基于两大创新:
- 工作窃取(Work-Stealing)算法:空闲线程从其他线程队列尾部"窃取"任务
- 递归任务分解:大任务自动拆分为子任务并行处理
通过精妙的工作窃取算法和递归任务分解,实现了近乎线性的加速比,成为现代Java高性能计算的引擎。理解其源码实现,是掌握Java并发编程高级技巧的关键一步。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!