
目录
作为一名深耕 Java 后端多年的技术人,我曾无数次被问到 “百万并发到底怎么落地”。尤其是抢券、秒杀、下单这类突发流量场景,很多同学一听到 “百万 QPS” 就觉得遥不可及,要么盲目堆机器,要么死磕单机优化却抓不住核心指标。
上一文我整理了 《支撑百万级并发:纵观微服务的全链路实战设计》,描述了全链路中提升 QPS 的手段,接下来我们进行具体的分析性能指标。其实百万并发的本质,是 “全链路指标的精细化管控” —— 从 URL 请求发起的那一刻起,每个环节的耗时、资源占用都有明确阈值;单机 QPS、集群扩容数量都能通过公式精准计算。本文就结合示例场景,把百万并发的核心指标、计算逻辑、落地方案掰开揉碎讲清楚。
题外话 —— 高并发的认知
如今,高并发似乎成了开发者们张口就来的话题。但究竟多高才算高?你能给出具体的数字吗?
很多人喜欢用 QPS/TPS 来标榜性能,声称自己的服务能达到几千 QPS。然而,这样的数字有时却会引来不屑一顾的反应。问题并不在于数字本身,而在于你谈论的是整个系统的吞吐量,还是单个接口的峰值?对应的是读操作还是写操作?是普通查询还是热点数据更新?这些都需要具象化的场景来支撑。
以双十一为例,峰值达到千万级 QPS。但你是否思考过,这是整个系统达到的,还是单个应用支撑的?是下单接口承接的流量,还是仅仅是一个查询接口?再具体到扣库存接口,到底是一个商品热点行的扣减,还是多行同时扣减?这里面的差异可谓天壤之别。
事实上,如果一个系统的整体 QPS 能达到几万甚至几十万,已经可以算是非常高了。而对于单个接口,如果每秒能处理几千个请求,这也不是一般小公司能够轻易达到的。如果是读接口还好,但如果是写接口,几千 TPS 持续一分钟,就会产生十几万甚至几十万的数据变更,这同样是非常惊人的。
具体到秒杀扣库存这种单个热点行的更新操作,如果 TPS 达到 300 左右,底层数据库 SQL 执行的锁等待时间可能就会超过20秒(这是压测得出的结论)。而当 TPS 超过 500 时,高并发的典型问题(如CPU争抢、线程池调优、锁竞争、慢SQL等)都会接踵而至。
因此,不要盲目追求所谓的高并发。一个依靠缓存支撑起几十万 QPS 的查询接口,其技术难度可能远低于一个 500 QPS 的秒杀扣减接口。脱离业务场景和技术上下文去谈论高并发,无异于建造空中楼阁。
接下来,本文将带你深入理解并发本质,掌握提升并发性能的实用方法,并学会计算高并发下的关键性能指标,从而有效提升系统的整体吞吐能力。
理解并发本质 —— QPS、RT与系统容量
我们首先明确 RT 和 QPS 的概念:
- RT(Response Time):响应时间,指从发送请求到接收到响应的时间间隔。
- QPS(Queries Per Second):每秒查询率,指系统每秒能够处理的请求数量。
QPS 公式的推导与实战计算
QPS 是 “每秒能成功处理的请求数”,是衡量系统吞吐量的核心指标,公式的推导完全基于 “并发能力” 和 “单请求耗时” 的逻辑。
逻辑推导
我们假设一个简单的场景:当前系统的并发线程数(如 Tomcat 的 maxThreads=200,代表同一时间最多有 200 个请求在处理),每个请求的完整处理耗时 = RT(单位:秒,如 50ms=0.05 秒)。
- 1 个线程处理 1 个请求需要 T 秒,那么 1 个线程 1 秒能处理 1/T 个请求;
- N 个线程 1 秒能处理的请求数 = N × (1/T) = N / T → 这就是 QPS 的核心公式。
那么,在 200 个线程都被占用的情况下,每 50ms 可以处理一个请求,系统每秒钟能够处理的请求数量(QPS)为:
1s / 0.05s = 20 个请求,那么 200 个并发线程每秒可以处理的请求数就是 200(并发线程数)* 20(单个线程每秒处理请求数) = 4000 个请求,按照推导后的公式来算,就是 200(并发线程数)/ 0.05(秒) = 4000 QPS。
公式标准化
这个公式是在并发数固定的情况下,且系统能够稳定处理请求时的理想情况。但是,在实际情况中,系统的处理能力是有限的,当并发数增加时,RT 可能会增加,因此 QPS 并不完全随并发数线性增长。
所以说,这 4000 QPS 是理论峰值,实际上还要考虑网络传输时间、数据库处理时间、以及系统上下文切换等开销。
textQPS(理论值)= 最大并发线程数 / 平均RT(秒) QPS(实际有效值)= 理论QPS × 资源利用率(0.7~0.8)
资源利用率:实际场景中 CPU / 内存 / 网络不会 100% 利用,需预留 20%-30% 冗余,避免峰值过载。
百万并发 ≠ 同时处理百万请求
在正式的去聊指标之前,必须先纠正一个认知偏差:百万并发通常指峰值 QPS=100万,而非 “同时有 100 万个请求在服务器中处理”。
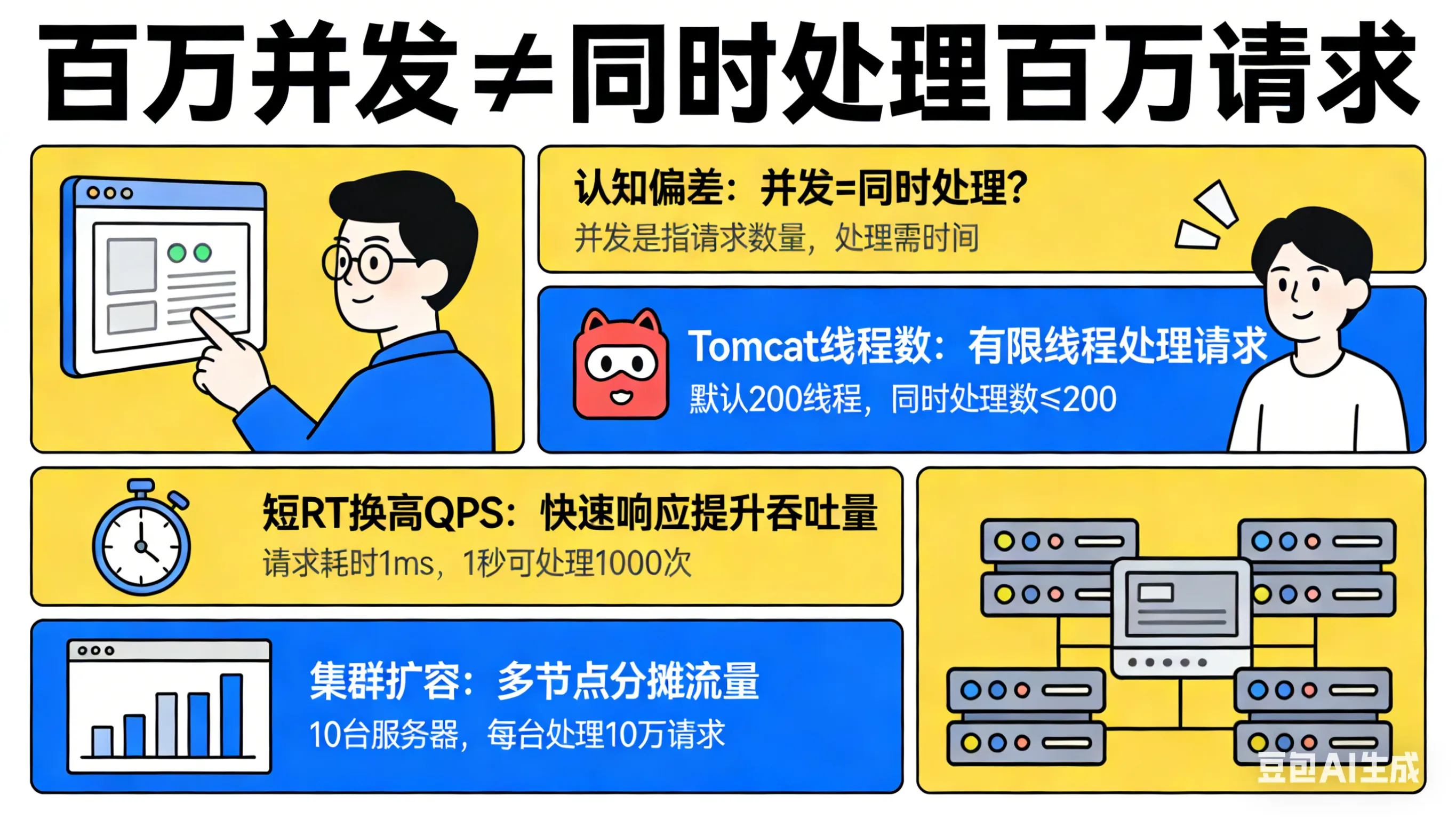
我有段时间的理解,就是两者之间是等同的,导致陷入到了一个瓶颈,那就是除了扩充机器,如何提升并发性能呢?后来深入学习了网络编程的知识,了解到了 HTTP1.1 的 TCP 连接复用,结合并发理论的知识,才发现系统的瓶颈原来是这样破解的。
按照上面推导公式的例子,我们常用的 Tomcat 的 maxThreads = 200,代表单机同一时间最多处理 200 个请求。但只要我们能把单个请求的响应时间(RT)压到毫秒级,再配合连接复用、集群扩容,200 线程的单机在1秒内也能支撑上千数万 QPS。
这就是百万并发的核心逻辑:用 “短 RT” 换 “高 QPS”,用 “集群扩容” 扛 “百万流量”。
全链路 RT 拆解与指标阈值
RT 的本质是 “请求从用户端发出,到接收到后端响应的全链路总耗时”,我们接下来去按照请求流向拆解每个环节,RT 的链路分析:
- 用户发起请求到 DNS 解析,获取负载均衡IP(如果有CDN,则获取CDN边缘节点IP)。
- 与负载均衡器建立TCP连接(如果有负载均衡器)。
- 负载均衡器将请求转发到后端Tomcat服务器。
- Tomcat服务器接收请求,解析HTTP,交给业务逻辑处理。
- 业务逻辑可能包括:参数校验、缓存查询、数据库查询、业务计算等。
- 生成响应,返回给用户。
其中,每一步都会有时间消耗。我们先明确核心公式:全链路RT(响应时间)= 网络传输耗时 + 应用处理耗时 + 业务处理耗时,所有优化都围绕 “降低各环节 RT” 展开。
网络传输耗时
网络传输上,这是物理距离决定的,我们很难改变,但必须计入。
- T1 - DNS 解析: 本地缓存 → 运营商 DNS → 根DNS,获取服务 IP,通常 < 10ms(如果有缓存)。
- T2 - 建立连接: TCP 三次握手 + TLS 握手(如果是 HTTPS)。通常在 50ms - 200ms 之间(跨省或跨国会更久),可通过部署就近接入点优化。
- T3 - 请求传输: 请求数据包从用户端经 CDN / 专线传输到后端 Nginx(反向代理层)。
- T4 - 响应传输: 数据包从服务端发回客户端。
注意
对于服务端监控来说,不能只关注“服务端处理时间”,必须注意到 “端到端 RT”,因为那才是用户体验。我们需要对建立连接的时间,单独预估,例如连接数有100个,每个连接建立需要 100ms,那么就需要 10000ms,也就是 10s,在一段时间内的 QPS 结算时,需要将当前连接时间统计在内。
应用处理耗时
反向代理服务器 Nginx 也做常用的复杂均衡 ,Nginx 层处理需要 负载均衡、路由转发、限流校验、静态资源过滤等,不过配置过多规则(如复杂 rewrite)会增加耗时。
通过负载均衡器,将请求转发到后端 Tomcat 应用服务器当中(Nginx→Tomcat),请求转发到 Tomcat、Tomcat 线程池调度、参数解析,Tomcat 线程池满会导致排队,耗时陡增。
业务处理耗时
业务层的一个耗时场景是比较多的,例如接口验签、参数校验、核心业务逻辑的处理、RPC 调用、IO存储的操作等,在同步调用下,包含一些非核心逻辑(如日志、通知)会翻倍耗时,常用的解决手段就是需要异步化。
之前我得 《支撑百万级并发:纵观微服务的全链路实战设计》 一文中,都是为了解决业务处理的耗时,这也是整个链路中的瓶颈所在,具体实现高并发的手段在此处不过多展开描述,更多关注于优化后的效果与指标的控制。
指标明细
RT(响应时间)是贯穿所有高并发场景的 “第一指标” —— RT 越短,单机 QPS 越高,所需机器越少。从用户输入 URL 到接收响应,拆解全链路每个环节的耗时和指标阈值(内网环境,外网需额外增加公网传输耗时)。
| 链路环节 | 核心动作 | 典型耗时(ms) | 硬性阈值 | 优化手段 |
|---|---|---|---|---|
| DNS 解析 | 本地缓存→运营商 DNS 获取服务 IP | 0(缓存)-10 | ≤1ms(必须缓存) | 开启本地 DNS 缓存、接入 HTTPDNS |
| TCP 三次握手 | 建立用户端与 Nginx 的连接 | 1-2 | ≤2ms | 开启 TCP Fast Open、长连接复用 |
| HTTPS 握手(可选) | 证书校验、密钥交换 | 2-5 | ≤3ms | 开启会话复用(Session Resumption) |
| 用户端→Nginx 传输 | 请求数据包跨网络传输 | 1-2 | ≤2ms | 部署就近接入点、CDN 边缘节点 |
| Nginx 层处理 | 限流、路由转发、静态过滤 | 0.1-0.3 | ≤0.5ms | 简化 Nginx 配置、禁用不必要的 rewrite 规则 |
| Nginx→Tomcat 传输 | 反向代理请求转发 | 0.1-0.5 | ≤0.5ms | 内网专线部署、关闭 Nginx 慢日志 |
| Tomcat 容器调度 | 线程池分配、参数解析 | 0.1-0.3 | ≤0.3ms | 调优maxThreads/acceptCount、禁用 AccessLog |
| Java 业务逻辑 | 验签、资格判断、参数校验 | 1-2 | ≤2ms | 异步化非核心逻辑(日志 / 通知)、消除锁竞争 |
| Redis 库存扣减 | Lua 脚本原子操作(查库存 + 扣减) | 0.1-0.5 | ≤0.5ms | 集群部署、开启管道、避免跨节点访问 |
| Mysql 订单落库(下单场景) | 连接池获取、SQL 执行、事务提交 | 1-3 | ≤3ms | 异步、分库分表、索引优化、小事务设计 |
| 响应回传 | 结果组装 + 反向传输到用户端 | 1-2 | ≤2ms |
集群扩容与吞吐量控制
搞懂了 RT,在回过头来看,我们通过公式精准计算单机 QPS,这是百万并发的 “量化基础”。而要实现百万并发,在我看来只有两个解法:
极力缩短 RT:
- 如果 RT 是 1秒,200线程只能抗 200 QPS。
- 如果 RT 能压到 10ms,200线程就能抗 2万 QPS。
- 手段: 缓存(Redis)、异步化(MQ)、无锁设计(CAS/ThreadLocal)。
增加“线程数”的概念:
这里的“线程”不能是传统的阻塞线程,必须是轻量级的。
- 手段 A (技术): 使用 Netty / WebFlux。它们用少量的线程(EventLoop)通过 NIO 非阻塞模型,可以支撑海量的连接。此时公式里的“线程数”不再是 200,而是几千甚至几万(文件描述符限制)。
- 手段 B (架构): 横向扩展。单机扛不住,就加机器。1台抗 1万 QPS,100台就能抗 100万 QPS。
单机 QPS 实战计算
首先定义处单机的上限,以最大并发线程数 200 为例,代表单机同一时间能处理的请求数,平均 RT:全链路响应时间,需换算成秒(如 5ms=0.005s);资源利用率:CPU / 内存 / 网络不会 100% 利用,预留 20%-30% 冗余避免峰值过载。从已知条件计算:
text理论QPS = 200 / 0.005 = 40000(4w QPS/单机) 实际有效QPS = 40000 × 0.8 = 32000(3.2w QPS/单机)
这个结果意味着:一台配置合理的 Java 服务器,200 线程就能支撑 3.2w QPS 的流量。
单机瓶颈的指标判断
单机 QPS 能否达到理论值,取决于是否触达资源瓶颈,我们可以通过以下指标快速判断:
- CPU 瓶颈:CPU 使用率持续 > 80% → 优化业务逻辑(如消除循环计算)、开启多核并行;
- 网络瓶颈:1G 网卡吞吐量 > 80%(≈100MB/s) → 压缩响应体、升级万兆网卡;
- 存储瓶颈:Redis 耗时 > 1ms/Mysql 耗时 > 5ms → 优化缓存策略、分库分表;
- 线程瓶颈:Tomcat 线程池满,acceptCount队列持续积压 → 调优线程池参数,或扩容机器。
集群扩容与吞吐量控制
单机 3.2w QPS,要达到百万 QPS 目标,集群扩容和吞吐量控制是关键。
那所需的集群机器数精准计算核心公式如下:
text所需机器数 = 目标QPS / 单机有效QPS × 峰值冗余系数
参数说明:
- 目标 QPS:100 万;
- 单机有效 QPS:3.2 万;
- 峰值冗余系数:场景的流量突发,通常取 2-3(避免峰值过载)。
计算过程:
text所需机器数 = 1000000 / 32000 × 3 ≈ 94台 → 取整100台(留足容错)
注意
这只是应用层机器数,存储层(Redis/Mysql)需要单独扩容:
- Redis:单机 QPS≈10-15 万,百万 QPS 需 10-15 台(主从 + 分片);
- Mysql:单机写 QPS≈1-2 万,需分库分表(如 16 库 16 表),搭配 16 台主库 + 16 台从库。
熔断、降级与限流策略
百万并发场景的核心特点是流量突发、链路复杂、依赖众多(如 Tomcat、Redis、Mysql、第三方服务),而每个环节的资源都是有限的,如果没有防护策略,系统会面临三种致命风险:
- 流量过载风险:突发百万请求直接打满 Tomcat 线程池、网卡带宽,核心接口无法响应;
- 依赖雪崩风险:若 Redis 故障(如宕机、响应超时),应用层线程会因等待 Redis 返回而阻塞,最终耗尽所有线程,导致整个应用不可用;
- 资源竞争风险:非核心功能(如用户积分查询、日志统计)占用大量 CPU / 内存,挤压核心功能(库存扣减、订单创建)的资源,导致核心链路 RT 飙升。
而限流、熔断、降级就是为了针对性解决这三类风险。
在高并发系统(如抢券、下单场景)中,熔断、降级与限流策略是保障系统稳定性的三大核心防护手段,三者各司其职、相互配合,本质是为了解决 「资源有限」与「流量无限」的矛盾,避免系统因过载、依赖故障而发生雪崩。
为什么需要限流?
系统的处理能力是有上限的,限流的目的是「拒绝超过上限的请求」,避免流量过载拖垮系统。
举个例子:我们之前计算过,单机 Tomcat 的有效 QPS 是 3.2 万,集群 100 台机器的总 QPS 是 320 万。但如果突发 500 万 QPS 的抢券请求,超出的 180 万请求会导致:
- Tomcat 的
acceptCount队列堆满,请求等待时间超过用户容忍阈值(如 500ms); - Redis/Mysql 被压垮,响应时间飙升,进而导致 Tomcat 线程阻塞;
- 整个集群的 RT 从 5ms 涨到 500ms,最终全部请求超时失败。
此时限流就是在入口处把流量控制在 320 万 QPS 以内,超出的请求直接返回「系统繁忙,请稍后再试」,既保证了系统不被压垮,也让大部分用户能正常抢券。
以此可以看出,限流解决的核心问题:
- 防止流量峰值击穿系统处理上限;
- 保证流量在系统可承载范围内平稳流转;
- 避免非目标用户(如刷单脚本)占用核心资源。
为什么需要熔断?
当依赖服务(如 Redis、Mysql、第三方支付接口)出现故障时,熔断会「切断故障链路」,避免故障扩散导致系统雪崩。
举个例子:抢券场景中,Redis 负责库存扣减,若 Redis 集群中有 1 个节点宕机,导致部分库存 key 的请求响应超时(从 0.5ms 涨到 100ms)。此时如果没有熔断:
- 应用层的线程会等待 Redis 返回,每个线程阻塞 100ms;
- Tomcat 的 200 个线程很快被全部阻塞,无法处理新请求;
- 整个应用从「部分不可用」演变为「完全不可用」,这就是雪崩效应。
而熔断的作用是:当 Redis 的失败率 / 超时率超过阈值(如 50%)时,自动切断对 Redis 的调用,直接返回「库存不足」的默认结果。这样 Tomcat 线程不会阻塞,核心接口依然能正常响应,只是部分用户看到「库存不足」,但系统不会雪崩。
以此可以看出,熔断解决的核心问题:
- 防止依赖服务故障扩散,避免雪崩效应;
- 给故障服务留出恢复时间(熔断后不会持续请求,故障节点可以慢慢重启);
- 保障系统的部分可用性(即使依赖故障,核心流程也能降级运行)。
为什么需要降级?
当系统过载时,降级会「牺牲非核心功能,保障核心功能」,把有限的资源留给最关键的业务流程。
抢券场景的核心流程是:查库存→扣库存→标记用户已抢,非核心流程是:用户积分查询→优惠券详情展示→抢券成功通知。当系统 CPU 使用率超过 90% 时:
- 如果继续执行所有流程,CPU 会被非核心逻辑占用,核心流程的 RT 会从 5ms 涨到 50ms;
- 而降级策略会关闭非核心流程:积分查询返回缓存数据、通知改为异步发送、详情展示返回简化版,这样 CPU 资源全部留给核心流程,保证抢券功能的稳定性。
降级的核心思想是 「舍小保大」—— 系统可以损失部分功能,但不能损失核心功能。
以此可以看出,降级解决的核心问题:
- 缓解系统资源紧张,优先保障核心业务的资源需求;
- 保证核心功能的高可用性,提升用户的核心体验;
- 实现系统的柔性可用(不是非黑即白,而是「核心可用,非核心不可用」)。
熔断、降级、限流的关系
其是三位一体的防护体系,三者不是孤立的,而是 事前预防(限流)→ 事中止损(熔断)→ 事中保障(降级) 的完整防护链:
- 限流是第一道防线:在流量入口控制请求数量,避免系统过载;
- 熔断是第二道防线:当依赖故障时,切断故障链路,防止雪崩;
- 降级是第三道防线:当系统资源紧张时,牺牲非核心功能,保障核心流程。
反过来看那就是:
- 没有限流,再完善的熔断和降级也挡不住洪水般的流量;
- 没有熔断,一个依赖故障就会拖垮整个系统;
- 没有降级,系统资源会被非核心功能耗尽,核心功能无法保障。
全链路压测与指标监控
百万并发的方案好不好,压测是唯一的检验标准。压测的核心目标实际上就是为了验证系统在 100 万 QPS 下的稳定性,去找出 RT 瓶颈点,甚至包括一些验证限流、降级策略有效性。
压测工具与策略
我们需要构建 “单节点→集群→峰值” 的三级压测体系,核心原则是
- 安全性第一:隔离压测流量,防止影响生产
- 循序渐进:从小流量开始,逐步增加
- 数据驱动:基于监控数据做决策
- 持续改进:压测不是一次性的,而是持续过程
单节点压测 → 微观调优
常用工具:JMH、JMeter、ApiFox
核心验证:单机 QPS 是否达标、RT 是否稳定、瓶颈在哪里
集群压测 → 中观容量
常用工具:JMeter集群、Locust、nGrinder、Tsung 核心验证:集群 QPS 是否线性增长(如 10 台机器是否 ≈ 32 万 QPS)
峰值压测 → 宏观峰值
常用工具:阿里云 PTS、K6
核心验证:1.5 倍目标 QPS 下,系统是否会雪崩、限流是否生效
对现有系统的压测方案
1. 工具选择:JMeter + Gatling 混合压测
2. 流量染色:在请求头注入 X-Load-Test: true,确保压测流量不写入真实数据库
3. 影子库:MySQL 使用独立实例,避免数据污染
4. 监控联动:压测期间实时观察 SkyWalking、Prometheus、Arthas
全链路压测的实现
压测内容比较多,后续我将写一篇全链路压测的文章
核心监控指标
压测和线上运行时,必须监控以下指标,形成闭环:
- 应用层:QPS、RT、线程池活跃数、错误率;
- 资源层:CPU 使用率、网卡吞吐量、内存占用;
- 存储层:Redis/Mysql 的 QPS、响应时间、连接数。
同时需要对压测后进行结果分析:
- 目标达成:95% 请求 RT < 200ms,错误率 < 0.01%
- 瓶颈定位:某次压测发现 MySQL 主从延迟达 800ms,导致 RT 暴涨
- 优化措施:引入读写分离 + 从库扩容,解决瓶颈问题
系统瓶颈的发现
当线程数过多时,系统上下文切换增加,或者数据库等资源成为瓶颈,RT 会增加,从而 QPS 可能不会继续增加。所以,我们需要通过压测找到系统的最大 QPS,以及此时对应的 RT 和并发数。
总结
简单来说,高并发的本质是“时间管理”。百万并发不是靠一台服务器硬扛,而是“全链路配合+精细化控制”,全程就像一条高效运转的生产线,每一步都不能慢、不能乱,掌握此全流程,你就会对系统中的 QPS 指标有了清晰的认知。
像最常见的秒杀场景,总结下来就5步,每一步都有硬要求:
-
用户发请求:你点“抢券”,请求先经过Nginx(相当于大门卫),先拦掉恶意请求、控制总流量,不让多余的请求冲进后面的服务器;
-
请求到Tomcat:大门卫把合法请求转给Tomcat(相当于车间),Tomcat只有200个“工人”(线程),不能让工人闲着,也不能让工人累倒,所以每个请求必须快进快出;
-
核心业务处理:Tomcat的工人不做复杂活,只做核心操作——调用Redis(相当于临时仓库),用Lua脚本快速查库存、扣库存(全程不能超过0.5ms),避免多个人抢同一份库存;
-
数据落地(下单场景):抢券成功后,订单数据再异步写到Mysql(相当于永久仓库),不耽误用户拿券的响应速度;
-
返回结果:所有操作做完,快速把“抢券成功/失败”返回给用户,全程必须控制在5ms以内(慢了用户就会退出去,还会拖垮整个系统)。
另外,还要加3个“防护措施”:
- 限流(拦掉多余请求)
- 熔断(某个环节出问题,比如Redis卡了,就暂时切断它,不让它拖垮所有)
- 降级(系统忙的时候,先关掉积分查询、消息通知这些不重要的功能,把力气留给抢券、下单)。
最后,高并发并不是盲目加机器凑数量,而是通过前面的全流程优化、精准计算,知道如何稳稳扛住百万并发,又能最大限度节省公司的服务器成本,这就是咱们开发者的价值所在。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!