
目录
在上篇《Java 网络编程原理 - 从输入域名到后端交互的全流程解析》文章中,我们探索了 “浏览器输入 www.taobao.com 回车之后发生了什么?” 从浏览器访问域名后出发,深入网络层面的数据传输,访问到 Web 服务器后进行响应。
接下来我们思考一下 “应用程序是如何建立 TCP 连接响应网络请求的?”,本文将带你从网络IO分析,了解不同的IO模型的实现,深入网络编程原理的实现。
实现一个简单的 TCP 服务器网络通信
TCP(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议,广泛应用于网络传输中。在Java编程中,我们通常会使用 TCP 连接来实现客户端和服务端之间的通信,在Java网络编程中,TCP 通信主要通过 Socket 和 ServerSocket 类实现。
Java 服务框架可以帮助我们快速构建 TCP 连接的服务器端和客户端,简化网络通信的实现。下面我们通过一个简单的示例来演示如何使用Java服务框架来创建TCP连接。
服务器端(Server)
服务器的主要任务是监听一个特定的端口,等待客户端的连接请求。一旦有客户端连接上来,它就接受这个连接,通过 accept() 方法阻塞等待客户端连接,然后与客户端进行数据交换。
javaimport java.io.*;
import java.net.*;
/**
* 同步阻塞服务器
*/
public class SimpleSyncBlockServer {
public static void main(String[] args) {
// 监听的端口
int port = 8080;
// 创建服务器Socket
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(port);
System.out.printf("服务器已启动,正在监听端口 %s\n", port);
// 等待客户端连接,阻塞等待
try (Socket clientSocket = serverSocket.accept()) {
try (
// 使用 try-with-resources 确保流自动关闭
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
// true表示自动刷新
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true)
) {
// 读取客户端消息
String clientMessage;
// 持续读取客户端消息,直到收到"bye"
while ((clientMessage = in.readLine()) != null) {
System.out.printf("收到客户端消息: %s\n", clientMessage);
// 回端复客户
out.println("服务器已收到: " + clientMessage);
// 客户端发送"bye"则结束通信
if ("bye".equalsIgnoreCase(clientMessage.trim())) {
break;
}
}
} catch (IOException e) {
System.err.printf("处理客户端连接时发生错误: %s\n", e.getMessage());
} finally {
try {
// 关闭客户端socket
clientSocket.close();
System.out.printf("客户端连接已关闭: %s\n", clientSocket.getInetAddress().getHostAddress());
} catch (IOException e) {
System.err.printf("关闭客户端socket时发生错误: %s\n", e.getMessage());
}
}
}
} catch (IOException e) {
System.err.printf("服务器启动或运行异常: %s\n", e.getMessage());
} finally {
// 关闭服务器socket
if (serverSocket != null && !serverSocket.isClosed()) {
try {
serverSocket.close();
System.out.println("服务器已关闭。");
} catch (IOException e) {
System.err.printf("关闭服务器socket时发生错误: %s\n", e.getMessage());
}
}
}
}
}
java.net.Socket:客户端通信端点java.net.ServerSocket:服务器监听套接字java.io.InputStream/OutputStream:数据传输流
ServerSocket 类的主要功能就是 监听套接字,通过指定的端口等待来自于网络中客户端的请求并且进行连接。
客户端(Client)
客户端相对简单,它需要知道服务器的IP地址和端口号,然后尝试连接。连接成功后,就可以向服务器发送数据,并接收服务器的回复。
javaimport java.io.*;
import java.net.*;
import java.util.Scanner;
public class SimpleTcpClient {
public static void main(String[] args) {
// 服务器IP地址,这里用本机
String serverIp = "127.0.0.1";
// 服务器端口
int port = 8080;
try (
// 尝试连接服务器
Socket socket = new Socket(serverIp, port);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// true表示自动刷新
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
// 用于从控制台读取用户输入
Scanner scanner = new Scanner(System.in)
) {
System.out.printf("已连接到服务器 %s:%s\n", serverIp, port);
String userInput;
String serverResponse;
while (true) {
System.out.println("请输入消息 (输入 'bye' 退出): ");
userInput = scanner.nextLine();
// 发送消息给服务器
out.println(userInput);
// 如果输入"bye",则退出循环
if ("bye".equalsIgnoreCase(userInput.trim())) {
break;
}
// 尝试读取服务器的回复,这里需要注意服务器端是否会立即回复
// 如果服务器是异步处理,或者回复有延迟,这里可能会阻塞
// 对于简单的请求-回复模式,readLine通常是可行的
if ((serverResponse = in.readLine()) != null) {
System.out.println("收到服务器回复: " + serverResponse);
}
}
} catch (UnknownHostException e) {
System.err.printf("未知主机: %s\n", serverIp);
} catch (IOException e) {
System.err.printf("无法连接到服务器或I/O错误: %s\n", e.getMessage());
} finally {
System.out.println("客户端已断开连接。");
}
}
}
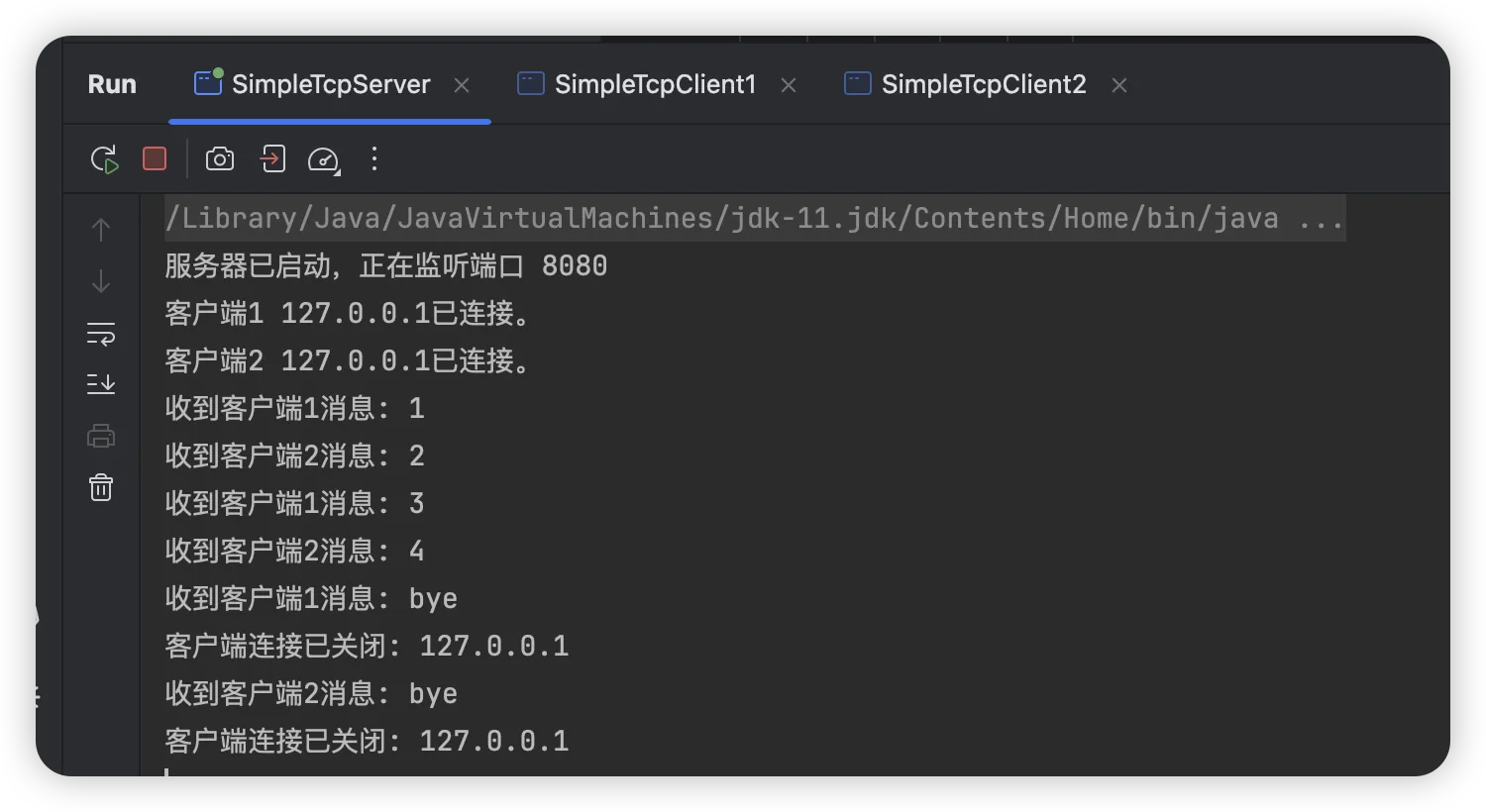
启动第一个客户端,输入数字1,然后启动第二个客户端,输入2,回到第一个客户端,输入3,依次输入,来看下服务端效果
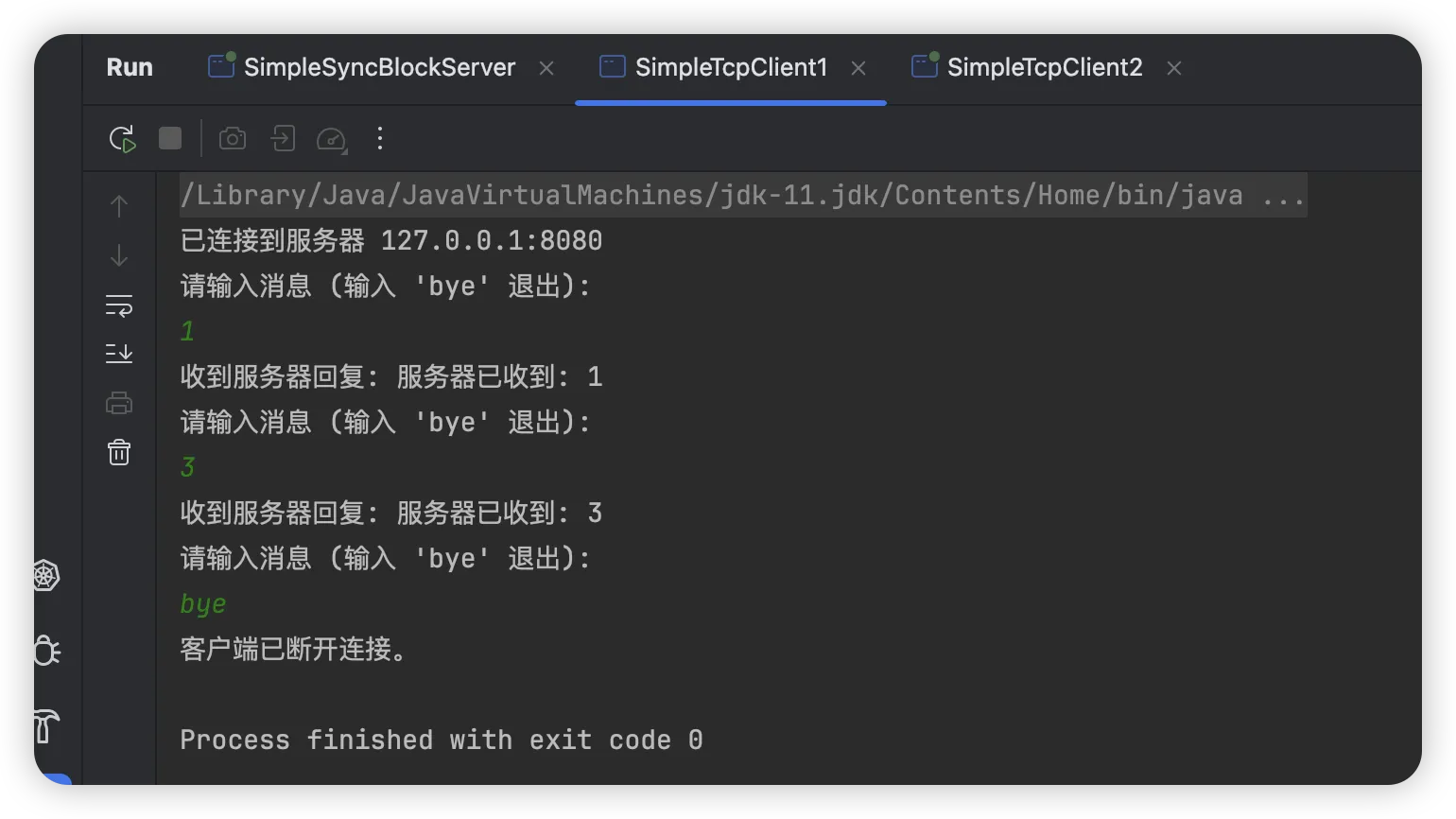

可以看到服务端只接收了数字 1,3,当第一个客户端输入‘bye’关闭后,服务端连接第二个客户端,开始输出第二个客户端的数字2,4
这是怎么回事呢?别着急,让我们来慢慢分析
服务端池化技术
上述示例中服务端的客户端连接是阻塞的,为了解决客户端阻塞问题,此处使用多个线程处理客户端:创建一个新的线程来处理其输入输出,这样,一个客户端的阻塞不会影响其他客户端。
javaimport java.io.*;
import java.net.*;
public class SimpleTcpServer {
public static void main(String[] args) {
// 监听的端口
int port = 8080;
// 创建服务器Socket
ServerSocket serverSocket = null;
AtomicInteger clientCount = new AtomicInteger(1);
try {
serverSocket = new ServerSocket(port);
System.out.printf("服务器已启动,正在监听端口 %s\n", port);
// 持续监听新的连接
while (true) {
// 阻塞,直到有客户端连接
Socket clientSocket = serverSocket.accept();
int clientId = clientCount.getAndIncrement();
System.out.printf("客户端%s %s已连接。\n", clientId, clientSocket.getInetAddress().getHostAddress());
// 为每个客户端连接创建一个新的线程来处理,避免阻塞主线程
new Thread(() -> {
try (
// 使用 try-with-resources 确保流自动关闭
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
// true表示自动刷新
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true)
) {
// 读取客户端消息
String clientMessage;
// 持续读取客户端消息,直到收到"bye"
while ((clientMessage = in.readLine()) != null) {
System.out.printf("收到客户端%s消息: %s\n", clientId, clientMessage);
// 回端复客户
out.println("服务器已收到: " + clientMessage);
// 客户端发送"bye"则结束通信
if ("bye".equalsIgnoreCase(clientMessage.trim())) {
break;
}
}
} catch (IOException e) {
System.err.printf("处理客户端%s连接时发生错误: %s\n", clientId, e.getMessage());
} finally {
try {
// 关闭客户端socket
clientSocket.close();
System.out.printf("客户端%s连接已关闭: %s\n", clientId, clientSocket.getInetAddress().getHostAddress());
} catch (IOException e) {
System.err.printf("关闭客户端socket时发生错误: %s\n", e.getMessage());
}
}
}).start();
}
} catch (IOException e) {
System.err.printf("服务器启动或运行异常: %s\n", e.getMessage());
} finally {
// 关闭服务器socket
if (serverSocket != null && !serverSocket.isClosed()) {
try {
serverSocket.close();
System.out.println("服务器已关闭。");
} catch (IOException e) {
System.err.printf("关闭服务器socket时发生错误: %s\n", e.getMessage());
}
}
}
}
}
代码调整完成以后,整个通信流程图如下:
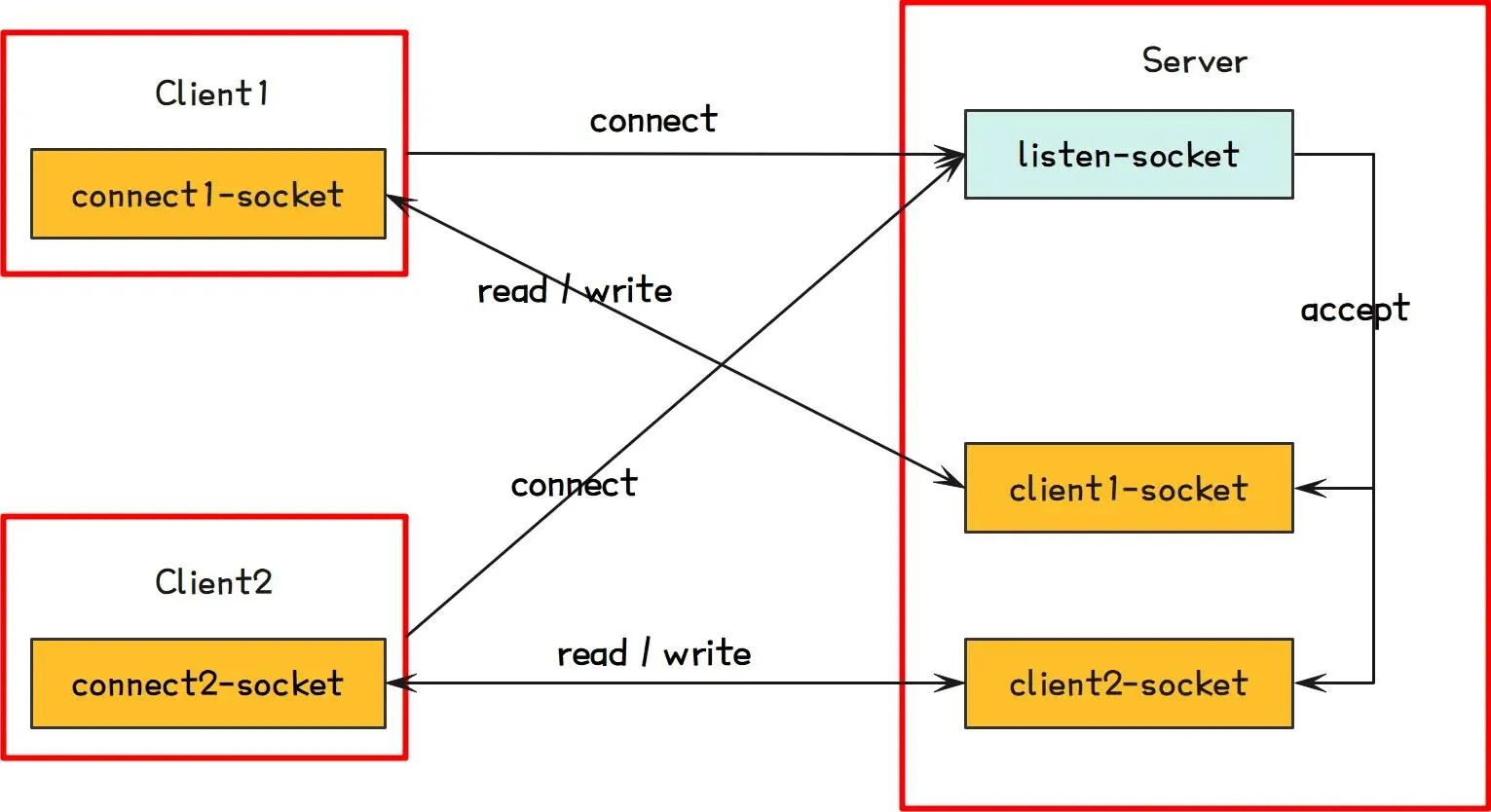
- 服务端启动后,会创建监听器
listen-socket,监听器会绑定端口号 port,然后服务端进入监听状态; - 客户端根据服务地址请求服务端时,会创建
connect-socket,客户端通过 “三次握手” 发起连接请求; connect-socket与listen-socket成功连接后(TCP 三次握手成功),服务端会为已连接的客户端创建一个代表该客户端的client-socket,用于后续和客户端进行通信;- 客户端与服务端通过 socket 进行网络IO操作,此时就实现了客户端和服务端中的不同进程的通信。
需要知道的就是,在客户端与服务端通信的过程中,出现了三种socket,分别是。
listen-socket:是服务端用于监听客户端建立连接的 socket;connect-socket:是客户端用于连接服务端的 socket;client-socket:是服务端监听到客户端连接请求后,在服务端生成的与客户端连接的 socket。
上述中的 socket,可以被称为套接字,也可以被称为文件描述符。
什么是套接字?
套接字(Socket)是计算机网络中 进程间通信的端点,本质是操作系统提供的网络通信编程接口(API),用于实现不同主机或同一主机上进程间的数据交换。它屏蔽了底层网络协议的复杂细节,为应用程序提供统一的通信接口。
本质作用:套接字作为应用层与网络协议栈之间的桥梁,抽象了网络通信的细节(如TCP/IP协议的数据封装),使开发者能专注于业务逻辑。它通常被实现为操作系统内核的文件描述符(File Descriptor),支持类似文件的操作(如读、写、关闭)。
套接字通信遵循客户端-服务器模型,典型流程如下:
- 服务器端:
创建套接字 → 绑定IP/端口 → 监听连接 → 接受客户端请求 → 数据传输 → 关闭连接。 - 客户端:
创建套接字 → 连接服务器 → 数据传输 → 关闭连接。
具体系统调用包括 socket()(创建)、bind()(绑定)、listen()(监听)、accept()(接受连接)、connect()(发起连接)、send()/recv()(数据传输)。
服务器套接字一次只能与一个客户端套接字进行连接,因此如果存在多台客户端同时发送连接请求,则服务器套接字就会将请求的客户端存放到队列中去,然后从中取出一个套接字与服务器建立的套接字进行连接。这也是之前示例中客户端阻塞的原因。
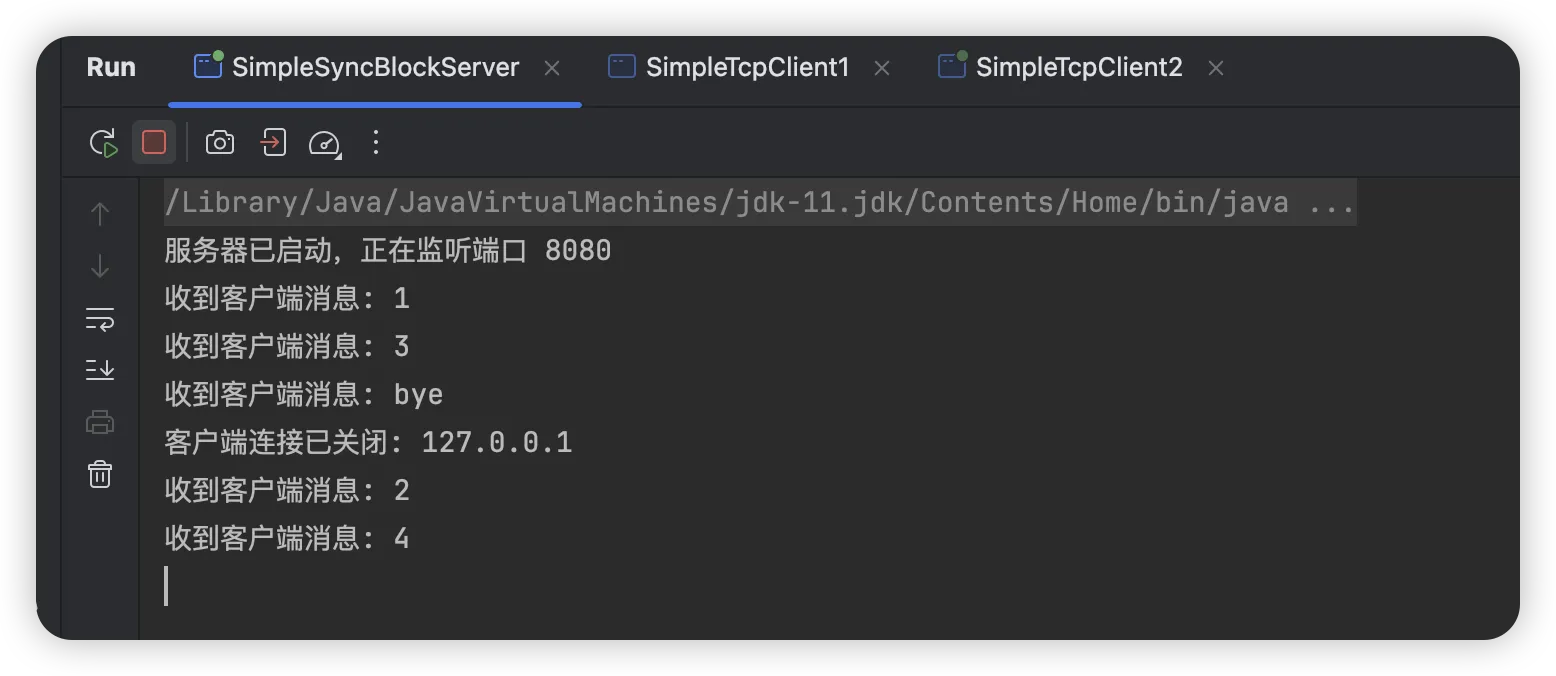
回头来看,我们的问题是否已经得到了解决呢?来看下实际效果
虽然我们通过多线程实现了多个连接的建立与通信,提高了并发性能,但实际上每个线程还是处于阻塞状态,并没有从根本上得到解决,当前的实现,其实就是我们常说的 BIO 模型,接下来让我们来深入了解下网络 I/O 的模型。
网络 I/O 模型
IO(Input/Output,输入输出)即数据的读取(接收)或写入(发送)操作,通常用户进程中的一个完整IO分为两个阶段:用户进程空间 <-> 内核空间 <-> 设备空间(磁盘,网卡等)。
IO 分为 内存IO、网络IO 和 磁盘IO 三种,接下来我们要说的就是 网络IO。
网络IO 的本质就是对套接字的读取,套接字在 Liunx 系统中被抽象为流,IO 可以被理解为对流的操作。对于一次IO的访问,数据会先被复制到操作系统内核的缓存区中,然后才会从操作系统内核的缓冲区复制到应用进程空间。
网络IO的模型可分为两种:
- 异步IO:发出的请求无需等待响应结果,可发起其他请求
- 同步IO:发出的请求在没有得到响应之前,不会发起其他请求
接下来我们描述的所有 IO 其实都是同步IO,同步IO模型下又包括:
- 阻塞IO
- 非阻塞IO
- 多路复用IO
BIO(Blocking I/O,阻塞式I/O)
BIO 是 Java 早期的 I/O模型,基于流(Stream)的概念实现数据读写。当进行I/O操作时,线程会被阻塞,直到操作完成。例如,使用 InputStream 从文件或网络连接中读取数据时,线程会一直等待,直到有数据可读或读取操作完成。从操作系统角度,这意味着线程会进入等待状态,不会占用 CPU 资源,直到 I/O 设备准备好数据或完成数据传输。
在Linux系统中,BIO 底层可能会调用 poll 函数等进行I/O事件监听。poll 函数会阻塞直到其中任何一个文件描述符(fd)发生事件。当有新连接时,抛出新线程处理连接,然后继续 poll 阻塞等待其他连接。
了解了 BIO 以后,当前是否就没有问题了呢?其实在上面的示例中,虽然给每个客户端都分配了一个线程进行处理,但还有不少“陷阱”:
-
每个线程处理一个网络请求,1000个并发请求就开1000个线程,每个线程占用一定内存做为线程栈,默认是1M,1000个就是1G,占用了大量内存,在没有数据的时候,这1000个线程闲着,造成了资源的浪费。
-
其中
socket.getInputStream().read()和socket.getOutputStream().write()在数据传输时实际上都是阻塞的。这意味着如果一方没有数据可读或可写,对应的线程就会一直等待,造成资源的浪费。
提示
这种阻塞特性在高并发场景下会导致严重问题:每处理一个连接都需要一个独立线程,当连接数激增(如10万用户同时访问),线程数量会爆炸式增长,最终耗尽CPU和内存资源。
这又是怎么回事呢?要如何解决呢?我们接下来继续来看
NIO(New IO,非阻塞式I/O)
为解决 BIO 的性能瓶颈,Java 1.4 引入了 NIO(New IO,也称为 Non-blocking IO)。NIO 的设计理念更像"监控多个电话线路的总机接线员" ——— 一个人(线程)可以同时监控多个线路(连接),只有当某个线路有信号(数据就绪)时才去处理,期间可以做其他事情。
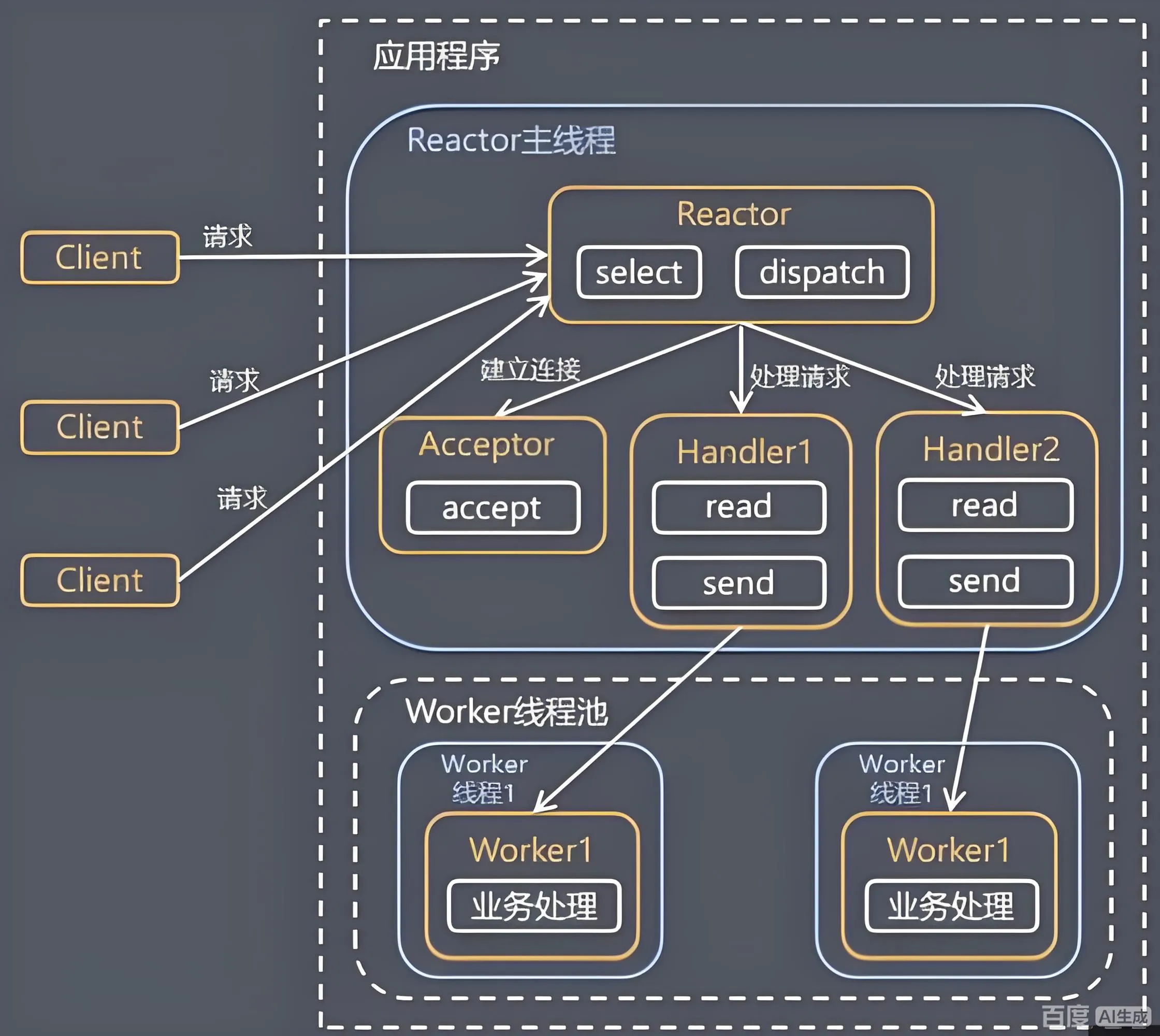
NIO 的强大源于三个核心组件的协同工作:Selector(选择器)、Channel(通道)、Buffer(缓冲区)。通过核心组件,构建了基于事件驱动的非阻塞I/O模型。与BIO不同,NIO 中的I/O操作不会阻塞线程,线程可以在等待I/O操作完成的过程中执行其他任务。
Selector:NIO的"大脑"
Selector(选择器)也被称为多路复用器,是 NIO 实现单线程处理多连接的核心。它可以同时监控多个 Channel 的状态(如"连接就绪"、“读就绪”、“写就绪”),当某个 Channel 状态满足时,Selector 会通知线程处理该 Channel。
Selector 的工作流程:
- 创建
Selector并注册 Channel(需设置为非阻塞); - Selector 可以监听 Channel 的四种状态(Connect、Accept、Read、Write)
- 调用
selector.select()阻塞等待 Channel 就绪(可设置超时); - 监听到某一 Channel 的某个状态时,才对 Channel 进行相应的操作(如读数据、接受连接)

IO 多路复用
在 BIO 中无法预知通道的读写状态,因此只能采用等待即阻塞的方式直到通道就绪,然后进行数据传输;而在 NIO 中选择器是核心组件之一,通道会向选择器注册,选择器就成了检测通道状态是否 I/O 就绪的实现。
这里主线程不需要以 for 循环的方式来检查每个注册通道是否有数据可以读取或者写出,而是由操作系统底层作为通知器来通知 JVM,对应的,主线程中可以通过调用选择器 select() 方法来检测这种就绪通知。
当已注册的某个通道出现了 I/O 就绪状态时,主线程则会终止 select() 方法的阻塞状态,继续执行处理通道数据。因为主线程进行 I/O 操作时通道已经就绪,即读操作时已有数据等待读取,写操作时通道已处于可写状态,所以不会发生 I/O 阻塞,提高了 CPU 的使用效率;通过一个线程就足以操作多个通道,减少了 CPU 在不同线程间非常耗时的切换动作,这种机制在 NIO 中被称为 “I/O多路复用”。
多路复用的出现是为了进一步优化 NIO,不需要用户扫描所有连接,而是由内核给出哪些连接有数据,然后应用从有数据的连接读取数据。在Linux系统中,常见的多路复用函数有 select、poll 和 epoll,Java 中IO 多路复用主要通过 Selector 基于这些函数实现。
select/poll:跨平台,适合小规模连接。epoll(Linux):高性能,适合大规模并发。kqueue(macOS/BSD):类似 epoll 的高效实现。IOCP(Windows):完成端口机制。
I/O 多路复用底层主要用的 Linux 内核的函数(select,poll,epoll)来实现
- NIO 底层在 JDK1.4 版本是用 linux 的内核函数
select()或poll()来实现。 - NIO 底层在 JDK1.5 版本是用 linux 的内核函数
epoll()基于事件响应机制来优化NIO。
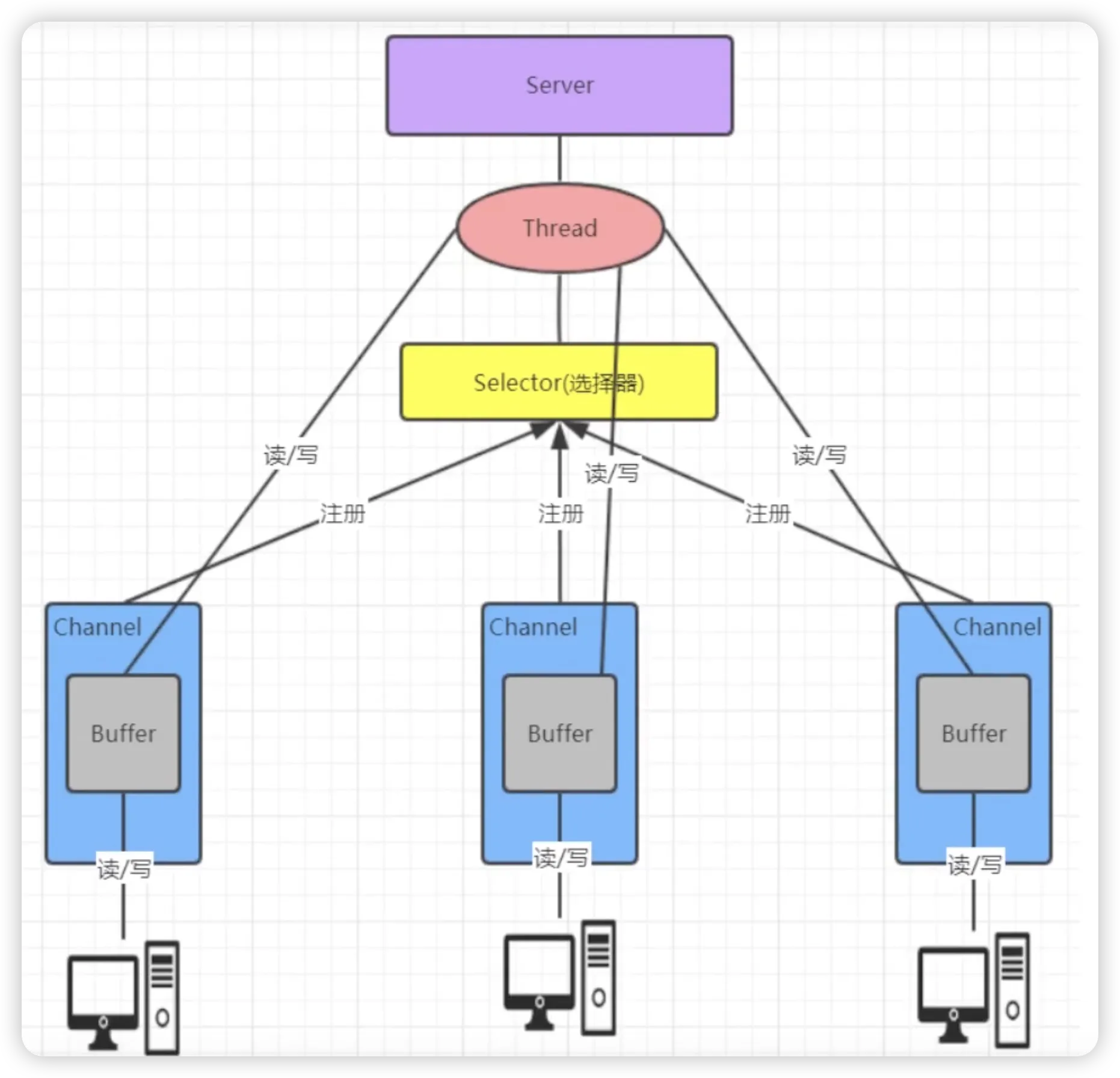
用一张图来描述一下三大核心组件之间的关系:
NIO实战:简单的非阻塞服务器
下面是一个基于 NIO 的TCP服务器示例,展示如何用单线程处理多个客户端连接:
javapublic class NIOTcpServer {
// 端口号
private static int port = 8080;
public static void main(String[] args) throws IOException {
// 选择器,事件驱动
Selector selector = Selector.open();
// 连接通道
ServerSocketChannel serverChannel = ServerSocketChannel.open();
// 绑定端口
serverChannel.bind(new InetSocketAddress(port));
// 设置非阻塞
serverChannel.configureBlocking(false);
// 注册事件驱动器
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 阻塞等待就绪的通道(可设置超时时间)
selector.select();
// 处理就绪的事件
Iterator<SelectionKey> keys = selector.selectedKeys().iterator();
while (keys.hasNext()) {
// 选择键
SelectionKey key = keys.next();
// 移除已处理的key
keys.remove();
// 接受新连接
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel clientChannel = server.accept();
clientChannel.configureBlocking(false);
// 注册读事件
clientChannel.register(selector, SelectionKey.OP_READ);
System.out.println("新客户端连接:" + clientChannel.getRemoteAddress());
}
// 处理读事件
else if (key.isReadable()) {
SocketChannel clientChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int len = clientChannel.read(buffer);
if (len > 0) {
buffer.flip();
String request = new String(buffer.array(), 0, len);
System.out.printf("收到客户端消息: %s\n", request);
// 响应客户端
String response = "服务端已收到:" + request;
clientChannel.write(ByteBuffer.wrap(response.getBytes()));
} else if (len == -1) {
// 连接关闭
clientChannel.close();
System.out.println("客户端断开连接");
}
}
}
}
}
}
代码中通过 Selector 实现多路复用,监听 ServerSocketChannel 的连接事件和 SocketChannel 的读取事件,同时 socketChannel.read(buffer) 为非阻塞读取操作,用单线程即可处理所有客户端连接,仅在通道有数据时才处理,大幅减少线程数量。
Channel:双向的"通道"
Channel(通道)是 NIO 中数据传输的载体,一个单独的线程现在可以管理多个输入和输出通道(channel)。与 BIO 的"流"相比,有两个关键区别:
- 双向性:既可读又可写(如
SocketChannel既可以读网络数据,也可以写数据到网络); - 非阻塞支持:可以设置为非阻塞模式
configureBlocking(false),配合Selector实现高效处理。
常用的 Channel 类型:
ServerSocketChannel:TCP 协议的服务端通道;SocketChannel:TCP 协议的客户端连接听通道,连接到套接字;DatagramChannel:UDP 数据传输通道。FileChannel:文件数据读写的通道(支持零拷贝);

从上面类图中可以看到,ServerSocketChannel、SocketChannel、DatagramChannel 都是继承自 SelectableChannel,即他们可配置为非阻塞的,这意味着线程在读写这些通道时不会进入阻塞状态,对应的就是非阻塞 I/O 模型。
SelectionKey:表示通道与 Selector 的注册关系,记录关注的事件类型:
OP_ACCEPT:服务器接受连接,isAcceptable()表示是否有连接请求事件发生。OP_CONNECT:客户端连接完成,isConnectable()表示是否有连接完成的事件。OP_READ:通道有数据可读,isReadable()表示是否有读数据事件发生。OP_WRITE:通道可写数据,isWritable(),表示是否有写数据事件发生。
零拷贝
在大文件传输场景(如视频点播、文件服务器),数据拷贝的开销往往成为性能瓶颈。NIO 通过 FileChannel 的transferTo/transferFrom 方法支持零拷贝技术,可大幅提升传输效率。
传统IO的拷贝流程(4次拷贝,2次CPU参与)
传统IO(包括BIO和NIO的普通Buffer操作)传输文件时,数据需经过4次拷贝:
- 磁盘 → 内核缓冲区(DMA拷贝,无需CPU);
- 内核缓冲区 → 用户缓冲区(CPU拷贝);
- 用户缓冲区 → Socket 缓冲区(CPU拷贝);
- Socket 缓冲区 → 网卡(DMA拷贝)。
其中步骤2和3是CPU拷贝,占比大量计算资源,尤其在大文件传输时耗时严重。
零拷贝的优化(2-3次拷贝,0次CPU参与)
NIO 的 transferTo 方法通过调用操作系统的零拷贝接口(如 Linux 的 sendfile),跳过用户缓冲区,直接在内核空间完成数据传输:
- 磁盘 → 内核缓冲区(DMA拷贝);
- 内核缓冲区 → 网卡(DMA拷贝,无需CPU)。
整个过程无CPU拷贝,效率提升30%-50%(取决于文件大小)。
零拷贝实战:高效文件传输
java// 用 NIO 零拷贝实现文件传输(本地文件复制)
public class ZeroCopyDemo {
public static void main(String[] args) throws IOException {
String sourcePath = "large_file.mp4"; // 大文件(如1GB视频)
String destPath = "copied_file.mp4";
try (FileChannel sourceChannel = new FileInputStream(sourcePath).getChannel();
FileChannel destChannel = new FileOutputStream(destPath).getChannel()) {
long start = System.currentTimeMillis();
// 零拷贝传输:sourceChannel → destChannel
long transferred = sourceChannel.transferTo(0, sourceChannel.size(), destChannel);
long end = System.currentTimeMillis();
System.out.println("传输字节数:" + transferred + ",耗时:" + (end - start) + "ms");
}
}
}
在实际测试中,传输1GB文件,零拷贝比传统IO快约40%,且文件越大,优势越明显。
Buffer:数据的"容器"
Buffer 也叫做缓冲区,是 NIO 操作数据的基本单位,本质是一块可读写的内存区域(类似数组),但比数组多了读写模式切换和位置标记等功能。缓冲区主要用于和 NIO 通道进行交互,数据从通道内读入缓冲区,再从缓冲区写入通道的。缓冲区本质上是一块可以写入数据,然后从中读取数据的内存,这块内存就被封装成 NIO Buffer 对象。
NIO 使用通道读取数据,与传统IO不同的是,它无法通过通道直接读写数据,而是必须经过缓冲区。缓冲区是临时存储数据的容器,常用的 Buffer 类型:
ByteBuffer:处理字节数据(最常用,如文件、网络传输);CharBuffer:处理字符数据;IntBuffer/LongBuffer:处理基本类型数据。

Buffer 的核心操作:
java// Buffer基本操作示例
ByteBuffer buffer = ByteBuffer.allocate(1024); // 分配1024字节缓冲区
// 写数据(写模式)
buffer.put("hello".getBytes()); // 向缓冲区写入数据
buffer.flip(); // 切换到读模式(limit=position,position=0)
// 读数据(读模式)
byte[] data = new byte[buffer.remaining()]; // remaining()=limit-position
buffer.get(data); // 从缓冲区读取数据到数组
System.out.println(new String(data)); // 输出"hello"
buffer.clear(); // 清空缓冲区(切换回写模式,数据未真正删除)
向缓冲区写入数据时,缓冲区会记录下写了多少数据。一旦读取数据,需要通过调用 flip() 方法将缓冲区从写模式切换到读模式。在读模式下,可以读取之前写入缓冲区的所有数据。一旦读完了所有的数据,就需要清空缓冲区,让他可以在次被写入。
清空缓冲区的方式有两种:
- 调用
clear()方法,会清空整个缓冲区 - 或者
compact()方法,只会清除 已经读过的数据。
AIO(Asynchronous I/O,异步非阻塞I/O)
AIO 的核心思想是异步非阻塞。它允许应用程序发起IO操作后,无需等待IO完成,可以立即执行其他任务。当IO操作完成后,操作系统会通过回调函数或者事件通知的方式,告知应用程序IO操作已经完成。
工作原理
- 异步非阻塞机制:用户线程发起I/O请求后,可立即执行其他任务;内核在后台完成数据读取或写入后主动通知线程,整个过程(数据准备和复制)用户线程均不阻塞。
- 操作系统依赖:需底层操作系统支持(如Linux 2.6+的AIO特性),性能受系统实现影响较大
实际上在 Java 中是有对异步IO(AIO)做支持,但是 AIO 依赖操作系统的底层实现,而目前 Linux 对 AIO 的支持不成熟,所以 AIO 的使用并不多,像主流的网络应用框架 Netty 也都没有使用到 AIO,有兴趣的小伙伴可以自行研究。
通信中数据的序列化与反序列化
在 TCP 通信中,数据总是以字节流的形式传输的。这意味着如果你想发送一个Java对象,或者更复杂的数据结构,你需要把它们转换成字节序列,然后在接收端再把字节序列还原成原来的数据。这个过程就是序列化(Serialization)和反序列化(Deserialization)。
序列化在我们网络传输中也占用非常高的地位,网络IO的设计高性能服务器的基础,那序列化机制就是高性能的架构支撑。
Java 内置的对象序列化
Java 提供了一套非常方便的机制来序列化Java对象。只要你的类实现了 java.io.Serializable接口(它的存在纯粹是为了在运行时通过反射机制标识类的属性),你就可以使用 ObjectOutputStream 将对象写入到输出流,使用 ObjectInputStream 从输入流中读取对象。
实现 Serializable 接口后,你的对象就获得了两种能力:
- 序列化(Serialize):将对象的状态(即属性值)转换为字节流。这使得对象可以被保存到文件(持久化)、存储到数据库,或者通过网络发送出去。
- 反序列化(Deserialize):将字节流重新读取并还原成原来的对象。
将上述代码中的流传输调整为 ObjectOutputStream 与 ObjectInputStream
javapublic class SimpleTcpServer1 {
static class server{
public static void main(String[] args) {
// 监听的端口
int port = 8080;
// 创建服务器Socket
ServerSocket serverSocket = null;
AtomicInteger clientCount = new AtomicInteger(1);
try {
serverSocket = new ServerSocket(port);
System.out.printf("服务器已启动,正在监听端口 %s\n", port);
// 持续监听新的连接
while (true) {
// 阻塞,直到有客户端连接
Socket clientSocket = serverSocket.accept();
int clientId = clientCount.getAndIncrement();
System.out.printf("客户端%s %s已连接。\n", clientId, clientSocket.getInetAddress().getHostAddress());
// 为每个客户端连接创建一个新的线程来处理,避免阻塞主线程
new Thread(() -> {
try (
// 使用 try-with-resources 确保流自动关闭
ObjectInputStream in = new ObjectInputStream(clientSocket.getInputStream());
) {
// 读取客户端消息
Object clientMessage;
// 持续读取客户端消息,直到收到"bye"
while ((clientMessage = in.readObject()) != null) {
System.out.printf("收到客户端%s消息: %s\n", clientId, clientMessage);
}
} catch (IOException | ClassNotFoundException e) {
System.err.printf("处理客户端%s连接时发生错误: %s\n", clientId, e.getMessage());
} finally {
try {
// 关闭客户端socket
clientSocket.close();
System.out.printf("客户端%s连接已关闭: %s\n", clientId, clientSocket.getInetAddress().getHostAddress());
} catch (IOException e) {
System.err.printf("关闭客户端socket时发生错误: %s\n", e.getMessage());
}
}
}).start();
}
} catch (IOException e) {
System.err.printf("服务器启动或运行异常: %s\n", e.getMessage());
} finally {
// 关闭服务器socket
if (serverSocket != null && !serverSocket.isClosed()) {
try {
serverSocket.close();
System.out.println("服务器已关闭。");
} catch (IOException e) {
System.err.printf("关闭服务器socket时发生错误: %s\n", e.getMessage());
}
}
}
}
}
static class client {
public static void main(String[] args) {
// 服务器IP地址,这里用本机
String serverIp = "127.0.0.1";
// 服务器端口
int port = 8080;
try (
// 尝试连接服务器
Socket socket = new Socket(serverIp, port);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// true表示自动刷新
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
// 用于从控制台读取用户输入
Scanner scanner = new Scanner(System.in)
) {
System.out.printf("已连接到服务器 %s:%s\n", serverIp, port);
String userInput;
String serverResponse;
while (true) {
System.out.println("请输入消息 (输入 'bye' 退出): ");
userInput = scanner.nextLine();
if ("user".equalsIgnoreCase(userInput.trim())) {
ObjectOutputStream oos = new ObjectOutputStream(socket.getOutputStream());
oos.writeObject(new Tuser("张三", 18));
}else {
// 发送消息给服务器
out.println(userInput);
}
// 如果输入"bye",则退出循环
if ("bye".equalsIgnoreCase(userInput.trim())) {
break;
}
// 尝试读取服务器的回复,这里需要注意服务器端是否会立即回复
// 如果服务器是异步处理,或者回复有延迟,这里可能会阻塞
// 对于简单的请求-回复模式,readLine通常是可行的
if ((serverResponse = in.readLine()) != null) {
System.out.println("收到服务器回复: " + serverResponse);
}
}
} catch (UnknownHostException e) {
System.err.printf("未知主机: %s\n", serverIp);
} catch (IOException e) {
System.err.printf("无法连接到服务器或I/O错误: %s\n", e.getMessage());
} finally {
System.out.println("客户端已断开连接。");
}
}
}
@Data
@AllArgsConstructor
static class Tuser implements Serializable {
private String name;
private int age;
}
}
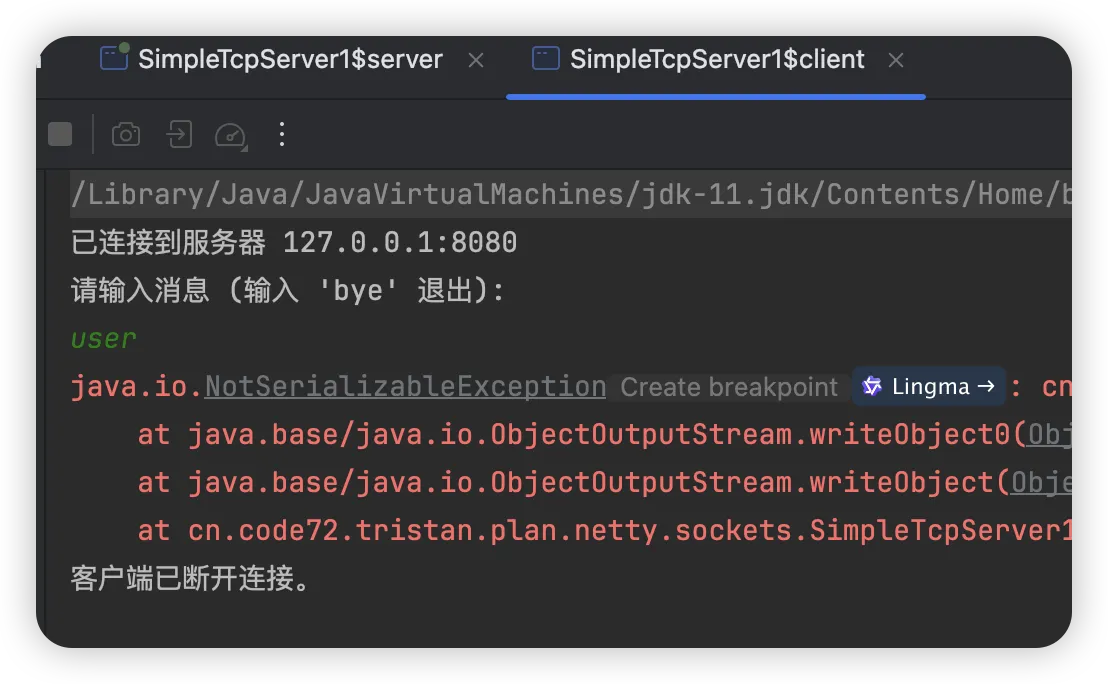
如果不实现这个接口,当你尝试使用 ObjectOutputStream 等工具进行上述操作时,Java 会直接抛出 NotSerializableException 异常。
基于文本的序列化
将对象转换成 JSON 字符串或 XML 字符串进行传输。这些格式都是人类可读的,并且有大量的库支持,方便跨语言使用,应用性广泛。像我们 Http 协议就使用 JSON 和 Form Data (表单数据) 两种方式。不过此方式也有缺点,相比二进制协议,通常数据量会稍大,解析也需要额外开销。
一个简单的示例如下:
javapublic class SimpleTcpServer2 {
@Data
@AllArgsConstructor
static class Tuser {
private String name;
private int age;
}
public static void main(String[] args) {
// 发送消息给服务器
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
String user = JSONUtil.toJsonStr(new Tuser("张三", 18));
out.println(user);
// 读取客户端消息
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
String clientMessage;
// 持续读取客户端消息
while ((clientMessage = in.readLine()) != null) {
Tuser tuser = JSONUtil.toBean(clientMessage, Tuser.class);
System.out.printf("收到客户端消息: %s\n", tuser);
}
}
}
基于二进制的序列化
当对性能、传输体积或传输速度有极高要求时,通常会使用二进制格式,像 Protocol Buffers / Apache Avro / Thrift 等。这些是更高级的序列化框架,它们通常需要你定义一个Schema(数据结构),然后根据Schema生成对应语言的代码,进行高效的二进制序列化和反序列化。
其优点是性能极高,序列化后的数据量小,跨语言支持良好,并且有严格的版本控制和向后兼容性,对于追求高性能的服务器实现,这些序列化方式都是首选,大多数的高性能服务器都采用 Protocol Buffers 的方式。不过它也有其缺点,那就是学习成本和使用复杂性相对较高,需要额外定义Schema文件。
粘包、拆包
在 HTTP/1.1 中,当服务器无法预先知道响应体的总长度(例如动态生成的网页、大文件流式下载)时,它不能使用 Content-Length 头部。这时,分块传输编码(Chunked Transfer Encoding) 就派上用场了。
它将原本的一个大消息体(Body)拆分成多个“块”(Chunk),每个块都自带长度信息。接收方(浏览器或客户端)根据这个长度信息来重组数据。虽然 HTTP 使用 chunked 来定义消息边界,解决了大型文本数据传输的问题,但在底层 TCP 传输过程中,“粘包” 和 “拆包” 依然是客观存在的物理现象。
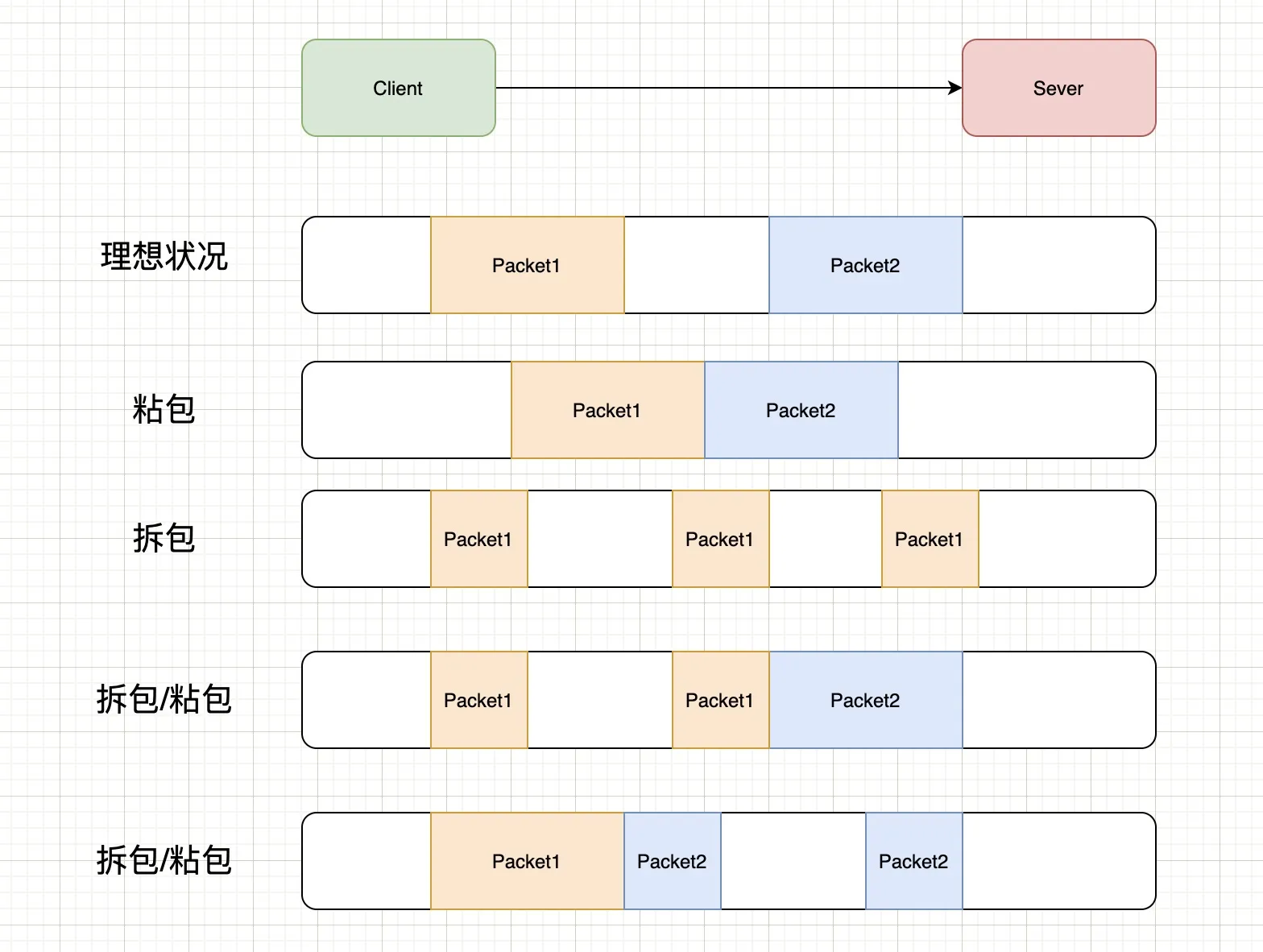
什么是“粘包”?
粘包是指发送方发送了多条消息,但接收方一次性将多条消息合并读取了。例如,你发送了 "Hello" 和 "World",接收方却收到了 "HelloWorld"。
TCP 是面向字节流的协议,它没有“消息边界”的概念。TCP 只负责把字节流从一端传输到另一端,至于如何划分这些字节流,是应用层的事情,粘包产生的原因是:
- Nagle 算法(发送端):为了提高网络传输效率,TCP 会将多个小的数据包合并成一个大的数据包发送。如果发送方连续发送多个小数据包,TCP 可能会把它们攒在一起发出去。
- 接收缓冲区(接收端):接收方的应用程序如果没有及时从 TCP 接收缓冲区读取数据,新到达的数据就会堆积在缓冲区里。当下次读取时,可能会一次性读出多个数据包的内容。
那我们的 Web 服务中是如何解决粘包问题的呢?或者说 Java 中如何解决粘包的?其实解决粘包的核心思路是在应用层定义消息边界。主要有三种方案:
方案一:固定长度法
规定每条消息的长度固定(例如 1024 字节)。发送方如果数据不足,用空字符(如 \0)填充;接收方每次固定读取 1024 字节。
在我们上述代码中是有示例的,如下所示:
java// 接收方
SocketChannel clientChannel = (SocketChannel) key.channel();
// 每次读取1024字节
ByteBuffer buffer = ByteBuffer.allocate(1024);
clientChannel.read(buffer);
此方案的缺点是有点浪费带宽(填充字符),且不灵活。
方案二:特殊分隔符法
在每条消息的末尾添加一个特殊的分隔符(如换行符 \n 或 $$$)。接收方读取数据,直到遇到分隔符才认为是一条完整的消息。
此类方式上述代码示例中也有对应的实现:
java// 使用 BufferedReader 按行读取(默认以 \n 或 \r\n 为分隔符)
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// 自动处理粘包,读到换行符为止
String message = reader.readLine();
此方案的缺点是消息体内容本身包含了分隔符,需要做转义处理,比较麻烦。
方案三:长度前缀法(推荐,工业级方案)
这是最通用的方案。消息结构为 [长度字段][实际数据]。发送方先发送 4 个字节的整数表示数据长度,再发送实际数据。接收方先读取 4 个字节得到长度 L,然后紧接着读取 L 个字节的数据。实现公式:接收方每次读取的字节数 = 4 (长度头) + L (消息体长度)。这种方式更加的灵活、高效、无特殊字符限制。
Http 协议中解决粘包的方式
“HTTP 分包传输机制 Transfer-Encoding: chunked” 本质上是应用层协议通过在数据流中插入 “长度前缀” 来定义消息边界。
什么是“拆包”?
在计算机网络和通信中,“拆包”(也常被称为分包或半包)是指一个完整的数据包在传输过程中被分割成多个部分,接收方需要分多次才能接收完整的现象。简单点来说,半包是粘包的反面,指发送方发送了一条完整的消息,但接收方分多次才读取完。例如,发送了 "Hello",接收方第一次读到 "He",第二次读到 "llo"。
拆包产生的根本原因无非就2点:
- 缓冲区机制:Socket 底层都有发送缓冲区和接收缓冲区。如果发送的数据量超过了当前缓冲区的剩余空间,或者一次 read() 操作读取的字节数小于实际发送的字节数,就会发生拆包。
- 网络限制(MTU 网络传输的最大传输单元):物理网络设备对单次传输的数据大小有限制。如果数据太大,IP 层会强制进行分片传输。
那半包的问题如何解决呢?
其实半包问题通常不需要单独处理,而是与粘包问题一起解决。上述的长度前缀法和分隔符法在处理数据时,都会先判断数据是否接收完整。如果没接收完(半包),代码逻辑会等待剩余数据到达后再进行拼装。
Tomcat Web 容器
当客户端(如浏览器、移动应用或其他服务)发送HTTP请求时,请求首先通过TCP/IP协议栈传输到 Tomcat 服务器的网络监听端口(默认 8080,HTTPS默认为 8443)。Tomcat支持两种I/O模式处理连接:
- NIO(非阻塞IO)模式
- BIO(阻塞IO)模式
提示
Tomcat 8之前,默认使用BIO连接器,每个请求都会分配一个线程,直到请求完成。
Tomcat 8及之后,默认使用NIO连接器,通过少量的线程处理大量连接。
NIO 工作原理:
- 使用 Java NIO 的 Selector 机制实现多路复用
- 主 Acceptor 线程接收连接后注册到 Selector
- Poller 线程通过
selector.select()轮询检测就绪的 Socket 通道 - 当检测到可读事件时,Worker 线程从 Socket 通道读取数据
- 数据被分批读入到 Socket 接收缓冲区,然后封装成 Java NIO 的
ByteBuffer对象
提示
- Acceptor 线程:接收新连接,放入 Poller 队列
- Poller 线程:监听已建立连接的I/O事件
- Worker 线程池:处理业务逻辑
Tomcat 配置参数:
properties// Tomcat NIO Connector配置(SpringBoot 2.x默认) server.tomcat.accept-count=100 // 等待队列大小 server.tomcat.max-connections=8192 // 最大连接数 server.tomcat.threads.max=200 // 最大工作线程 server.tomcat.threads.min-spare=10 // 最小空闲线程
处理 HTTP 请求的完整流程
Tomcat 接收到 HTTP 请求后,根据请求的路径和参数,调用相应的 SpringBoot 控制器(Controller)进行处理。SpringBoot 处理完业务逻辑后,将结果返回给 Tomcat,Tomcat 再将结果封装成 HTTP 响应。
步骤1:Connector监听并接收请求
- Tomcat 的
Connector 组件(默认NioEndpoint)监听8080端口,当客户端发起HTTP请求时,Acceptor线程接收连接; - 将连接交给 Poller 线程处理I/O事件,再由 Worker 线程池解析 HTTP 请求(解析请求行、请求头、请求体),封装为
org.apache.catalina.connector.Request和Response对象(Tomcat 内部封装,适配 Servlet 规范)。
步骤2:Engine路由到Host和Context
- Engine 接收
Connector传递的Request,根据请求域名(如localhost)匹配对应的Host组件; - Host 根据请求路径(如/hello)匹配对应的
Context组件(即Web应用)。
步骤3:Context匹配Servlet并调用
Context根据请求路径(如/helloServlet)匹配web.xml或注解配置的Servlet映射,找到对应的Wrapper组件;Wrapper负责管理目标Servlet的生命周期:若Servlet未初始化,则执行init()方法;若已初始化,直接从线程池分配线程执行service()方法。
步骤4:Servlet处理业务并返回响应
- Servlet 的
service()方法根据请求方式(GET/POST)调用doGet()/doPost(),处理业务逻辑并向Response写入数据; - Tomcat 将
Response对象转换为HTTP响应报文,通过Connector返回给客户端。
步骤5:连接回收
请求处理完成后,Worker 线程释放,连接根据 Keep-Alive 策略决定是否关闭,Connector 回收资源。
Tomcat Web 容器的核心职责
Tomcat作为Servlet容器,核心是管理Servlet的生命周期,具体包含:
- 加载:Web应用启动时,Tomcat 扫描 Servlet 类(注解/XML配置),通过类加载器加载 Servlet 类;
- 初始化:首次请求或应用启动时(load-on-startup),调用Servlet的
init()方法,仅执行一次; - 执行:每次请求触发
service()方法,由 Tomcat 线程池执行,多线程环境需注意线程安全; - 销毁:Web应用停止时,调用
destroy()方法,释放资源
如何实现一个简单的 Tomcat Web 容器?
了解了 Tomcat 的底层原理,同时掌握了网络通信的原理和各种序列化方式,我将会在下一篇文章中实现一个轻量级的web服务器,用来接收浏览器的请求,同时根据请求过来的信息,进行路由到接口上进行数据处理,根据最后处理的数据结果进行响应。
应用程序是如何建立 TCP 连接响应网络请求的?
当浏览器访问url以后,经过了网络传输的通信,传输到了 Web 服务器上,像我们使用 SpringBoot 中内置了 Tomcat 容器,在接收到网络请求时,通过 NIO 的模式进行建立连接与通信,通过 Selector 多路复用,轮询检测Channerl 通道,当检测到可读事件时,采用零拷贝的技术实现会将数据被分批读入到 Socket 接收缓冲区,读取完成以后会写入到 Channler 内的 Buffer 中。
读取完信息以后,会解析成 HTTP 请求对象,根据请求方式开始调用 doGet()/doPost() 的实现,通过 Spring MVC 分发,结合 DispatcherServlet 根据URL映射找到对应 Controller 执行。
当接口执行完成后,将响应的数据组装 Response 对象并转换为 HTTP 响应报文,最后通过 Tomcat 返回给客户端。


本文作者:柳始恭
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!